نه به معماری نمایشی

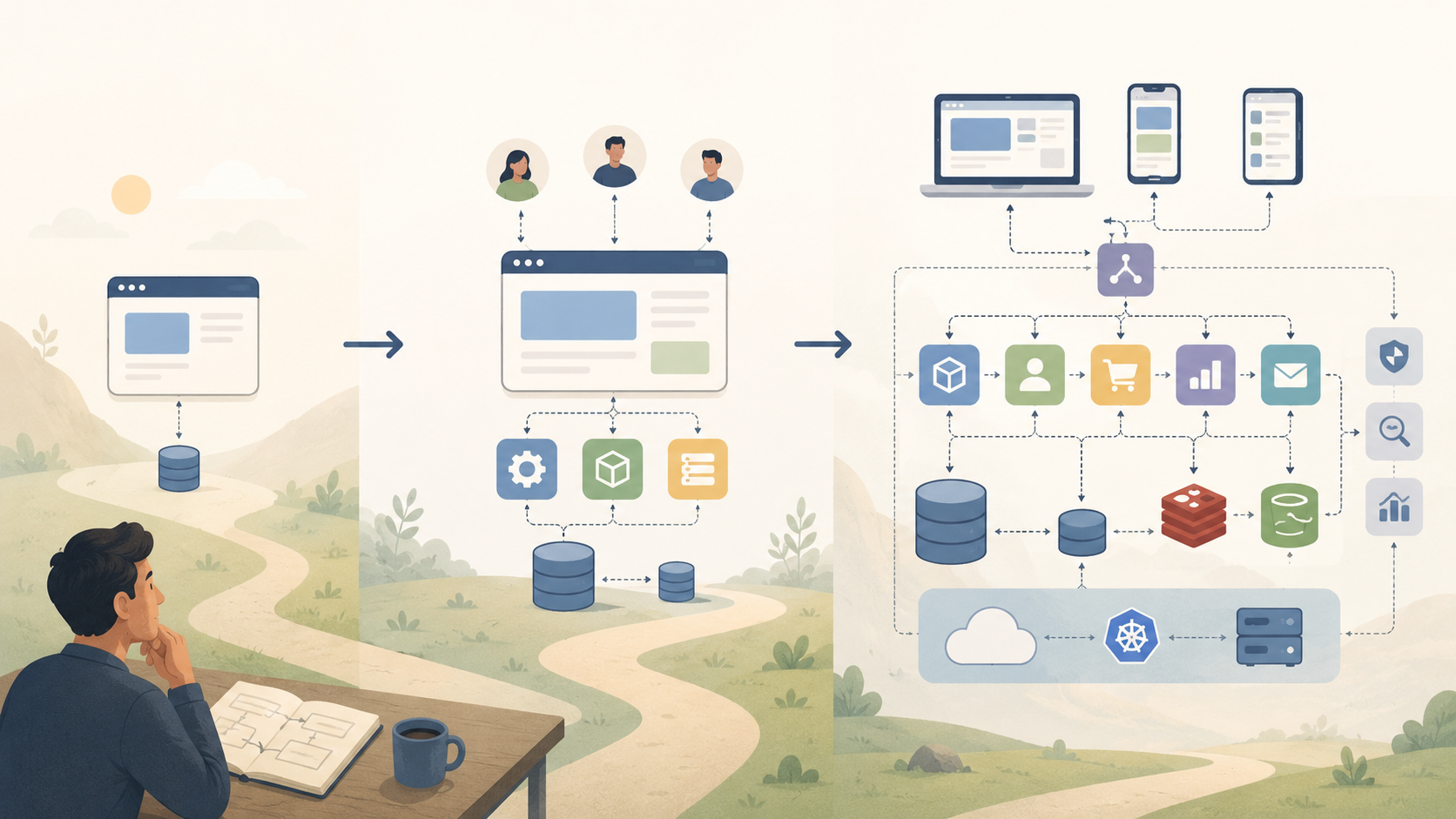
گاهی یک نرمافزار از جای خیلی سادهای آغاز میشود: چند صفحه، چند قابلیت روشن، چند کاربر اول، و یک تیم کوچک که فقط میخواهد محصولش درست کار کند. اما اگر آن محصول زنده بماند، آرامآرام بزرگ میشود؛ نیازهای تازه پیدا میکند، کاربران بیشتری سراغش میآیند، تصمیمهای قدیمی سنگینتر میشوند، و چیزهایی که دیروز ساده و کافی بودند، امروز گرههای تازه میسازند. درست همینجاست که بسیاری از واژههای ظاهراً خشک مهندسی نرمافزار، از دل زندگی واقعی یک سیستم معنا پیدا میکنند.
من در این نوشته نمیخواهم از همان ابتدا سراغ معماریهای پرزرقوبرق بروم و برای هر مسئلهای یک ابزار بزرگ روی میز بگذارم. برعکس، میخواهم از یک سؤال ساده شروع کنم: اگر واقعاً بخواهیم محصولی را قدمبهقدم بسازیم، چه زمانی به چه چیزی نیاز پیدا میکنیم؟ چه زمانی یک برنامهی ساده کافی است؟ چه زمانی همان سادگی، دیگر کمک نمیکند و تبدیل به مانع میشود؟ چرا روزی به طراحی بهتر رابطهای برنامهنویسی فکر میکنیم، روزی به صف پیام، روزی به کانتینر، روزی به مهاجرت داده، و روزی به عملیات یادگیری ماشین؟
این نوشته سفری مرحلهبهمرحله در مسیر بزرگشدن یک نرمافزار است؛ از روزی که فقط میخواهیم چیزی کار کند، تا روزی که باید قابل تغییر، قابل اعتماد و قابل نگهداری هم بماند. قرار نیست با واژهها مرعوب شویم؛ قرار است بفهمیم هرکدام کجا به درد میخورند و چرا نباید زودتر از موعد سراغشان برویم. خط اصلی این مسیر برای من همین است: نه معماری نمایشی، نه سادگی بیمسئولیت.
وقتی یک تغییر کوچک، چند جای سیستم را میشکند
گاهی ماجرا از یک تغییر خیلی کوچک آغاز میشود. مثلاً در پاسخ سرور، نام یک فیلد را عوض میکنیم؛ چون در کد تازه، نام جدید تمیزتر و دقیقتر به نظر میرسد. روی نسخهی وب همهچیز درست کار میکند. چند بار هم دستی امتحان میکنیم و مشکلی نمیبینیم. با خودمان میگوییم: «چیزی نبود، فقط اسم یک فیلد عوض شد.»
اما چند ساعت بعد پیامها شروع میشوند. برنامهی موبایل قیمت محصول را نشان نمیدهد. پنل مدیریت در بارگذاری دادهها خطا میدهد. شاید یک گزارش داخلی هم از همان پاسخ استفاده میکرده و حالا خالی مانده است. ناگهان روشن میشود چیزی که برای ما «یک تغییر کوچک» بود، برای چند بخش دیگر از سیستم، شکستن یک قول و قرار بوده است.
اینجاست که API یا همان رابط برنامهنویسی، از یک جزئیات فنی ساده به یک قرارداد تبدیل میشود. تا وقتی فقط خودمان از آن استفاده میکنیم، شاید چند مسیر و چند پاسخ ساده به نظر برسد. اما وقتی وب، موبایل، پنل مدیریت، یک تیم دیگر یا یک سرویس بیرونی به آن وابسته میشوند، دیگر با یک تکه کد معمولی طرف نیستیم. داریم زبانی مشترک میسازیم که دیگران بر پایهی آن کارشان را جلو میبرند.
هر API دیر یا زود از «راهی برای گرفتن داده» به «قراردادی میان بخشهای سیستم» تبدیل میشود. هرچه مصرفکنندههای بیشتری به آن وابسته شوند، تغییر دادن آن هم باید سنجیدهتر باشد.
رویکرد API-first را میشود خیلی ساده اینطور فهمید: اول قرارداد را روشن کنیم، بعد سراغ پیادهسازی برویم. یعنی پیش از اینکه با عجله کد بزنیم، کمی مکث کنیم و بپرسیم این بخش از سیستم قرار است با چه کسانی حرف بزند. چه دادهای لازم است؟ نامها برای مصرفکننده قابل فهماند؟ خطاها چطور برمیگردند؟ اگر چیزی تغییر کرد، تکلیف نسخههای قبلی چه میشود؟ پاسخ امروز فقط نیاز همین صفحه را حل میکند، یا برای رشد آرام فردا هم جایی میگذارد؟
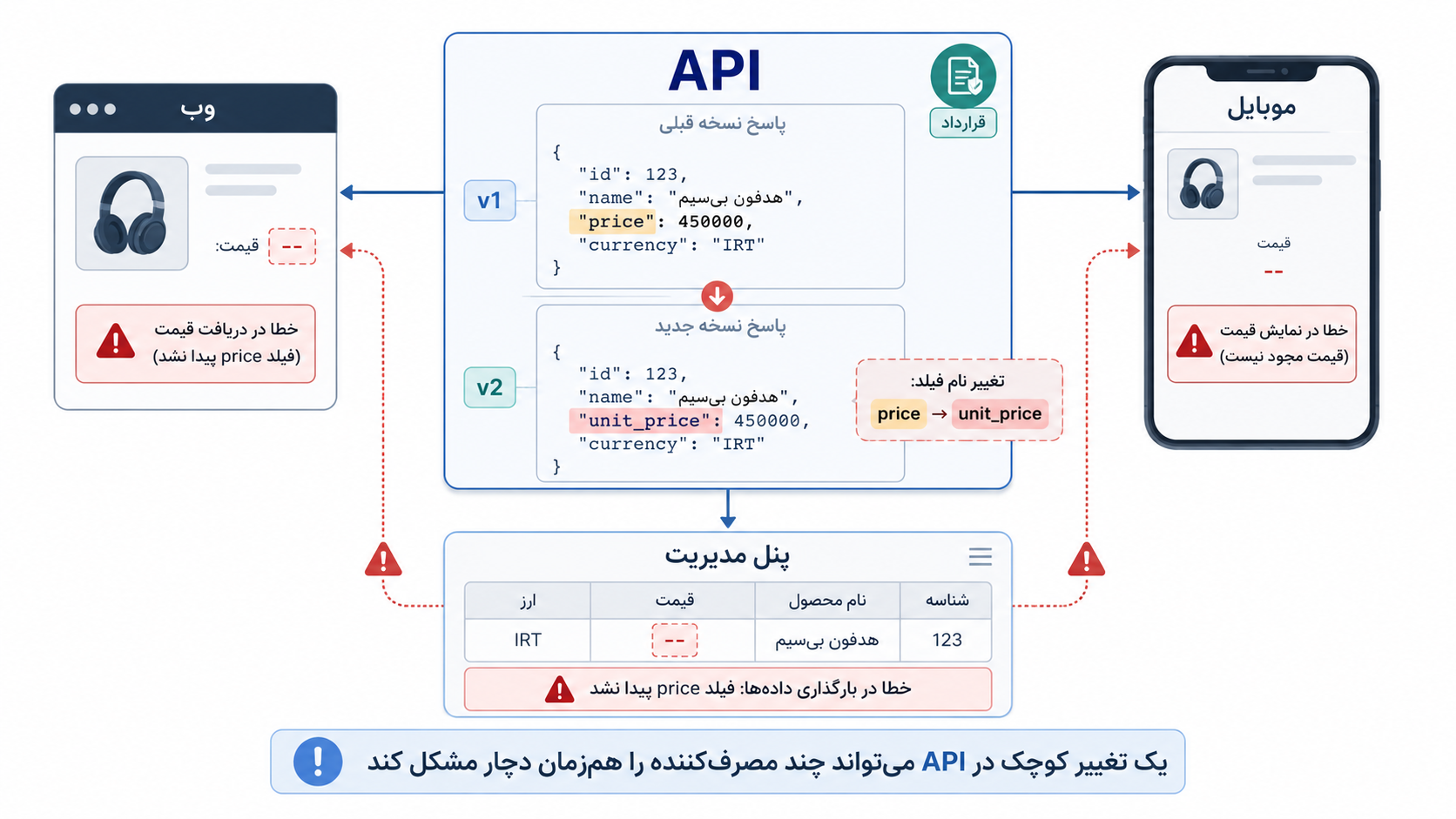
یک تغییر کوچک در پاسخ سرور، وقتی چند مصرفکننده دارد، دیگر فقط یک تغییر کوچک نیست.
اینجا بحث سازگاری هم مهم میشود. منظور از سازگاری پسرو (Backward Compatibility) این است که نسخههای قدیمیترِ مصرفکنندهها بعد از تغییر API همچنان کار کنند. مثلاً اگر فیلد price را ناگهان حذف کنیم و فقط unit_price را نگه داریم، برنامهی موبایلی که هنوز بهروزرسانی نشده ممکن است قیمت را گم کند. راه سنجیدهتر این است که برای مدتی هر دو فیلد را برگردانیم، مصرفکنندهها را به نام تازه کوچ بدهیم، و بعد از گذر زمان و با اطمینان، فیلد قدیمی را حذف کنیم.
سازگاری پیشرو (Forward Compatibility) از زاویهی دیگری به همین مسئله نگاه میکند: آیا مصرفکنندههای امروز میتوانند با پاسخهای کمی تازهتر کنار بیایند؟ مثلاً اگر سرور یک فیلد جدید به پاسخ اضافه کرد، آیا برنامهی موبایل فقط آن را نادیده میگیرد یا چون چیزی را نمیشناسد، خطا میدهد؟ API خوب معمولاً به مصرفکنندهها یاد میدهد در برابر چیزهای تازهای که به قرارداد افزوده میشوند، شکننده نباشند.
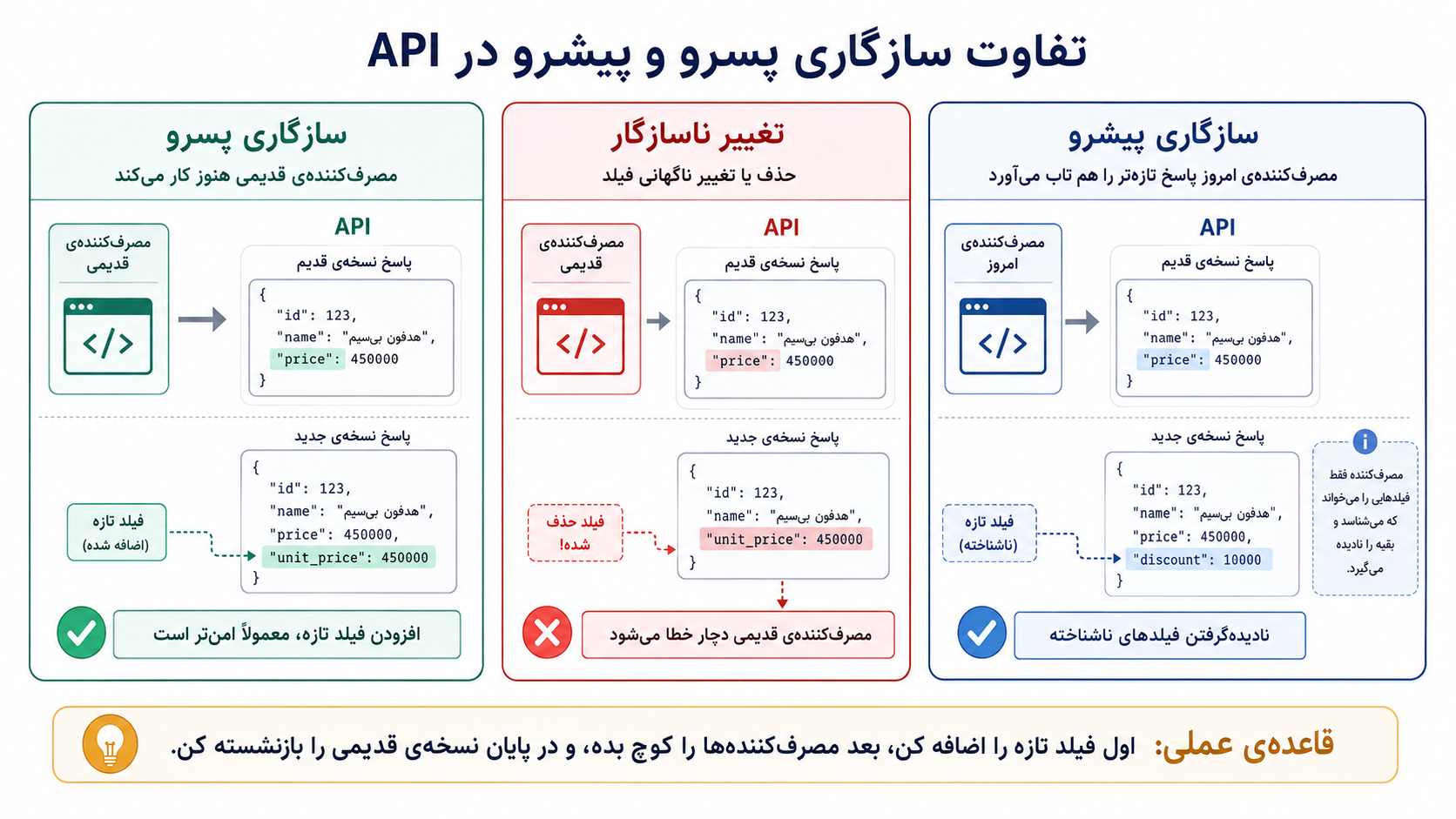
در تغییرهای امنتر، اول چیز تازه را اضافه میکنیم، سپس مصرفکنندهها را آرامآرام کوچ میدهیم، و در پایان نسخهی قدیمی را بازنشسته میکنیم.
در APIهای واقعی، تغییر خوب معمولاً یک حرکت ناگهانی نیست. اول چیز تازه را اضافه میکنیم، بعد مصرفکنندهها را آرامآرام به آن کوچ میدهیم، بعد رفتار قدیمی را منسوخ اعلام میکنیم، و در نهایت، وقتی مطمئن شدیم کسی به آن وابسته نیست، حذفش میکنیم.
| نوع تغییر | معمولاً امنتر است؟ | چرا؟ |
|---|---|---|
| افزودن یک فیلد تازه به پاسخ | بله | مصرفکنندههای قدیمی میتوانند آن را نادیده بگیرند. |
| حذف ناگهانی یک فیلد قدیمی | نه | مصرفکنندههای قدیمی ممکن است هنوز به آن وابسته باشند. |
| تغییر معنای یک فیلد بدون تغییر نام | نه | ظاهر قرارداد ثابت میماند، اما رفتار واقعی عوض میشود. |
| افزودن نسخهی تازه در کنار نسخهی قدیمی | معمولاً بله | فرصت مهاجرت مرحلهای میدهد. |
البته این نگاه به معنی سنگین کردن کار از روز اول نیست. قرار نیست محصولی را که هنوز شکل نگرفته، زیر بار سندهای طولانی، جلسههای زیاد و طراحیهای خشک ببریم. گاهی یک قرارداد کوتاه، چند نمونهی روشن از درخواست و پاسخ، نامگذاری دقیق، و توافق ساده میان اعضای تیم کافی است. مسئله این نیست که همهچیز را بزرگ و تشریفاتی کنیم؛ مسئله این است که بفهمیم کجا داریم چیزی میسازیم که دیگران روی آن حساب میکنند.
| نگاه عجولانه | نگاه سنجیدهتر |
|---|---|
| فعلاً همین پاسخ کار میکند. | چه کسی قرار است این پاسخ را مصرف کند؟ |
| نام فیلد را بعداً عوض میکنیم. | تغییر نام فیلد چه چیزی را میشکند؟ |
| خطا را هرطور شد برمیگردانیم. | خطا باید برای مصرفکننده قابل فهم باشد. |
| مستندات را بعداً مینویسیم. | چند نمونهی روشن از درخواست و پاسخ داریم. |
| فقط نیاز امروز مهم است. | نیاز امروز مهم است، اما راه تغییر فردا هم نباید بسته شود. |
API-first یعنی از روز اول کار را کند، رسمی و پر از تشریفات کنیم؟ نه. یعنی پیش از پیادهسازی، به قرارداد میان بخشهای سیستم کمی احترام بگذاریم.
یک نشانه که میگوید وقت جدیتر گرفتن API رسیده است
اگر برای تغییر دادن یک پاسخ ساده باید چند مصرفکننده را بررسی کنیم، با چند نفر هماهنگ شویم، و نگران شکستن بخشهای دیگر باشیم، آن API دیگر فقط یک جزئیات داخلی نیست. در این نقطه بهتر است آن را مثل یک قرارداد ببینیم: روشن، قابل فهم، تا حد ممکن پایدار، و قابل تغییر با احتیاط.
برای من، درس این بخش همین است: هنوز قرار نیست معماری بزرگی بسازیم، اما باید بفهمیم بعضی چیزها زودتر از بقیه به مرز سیستم تبدیل میشوند. API یکی از همان جاهاست؛ جایی که تصمیمهای کوچک امروز، روی آزادی عمل فردای ما اثر میگذارند.
وقتی یک پاسخ واحد، برای همه مناسب نیست
اوایل کار، معمولاً یک API عمومی برای همه کافی است. نسخهی وب همان دادهای را میگیرد که لازم دارد، صفحهها را میسازد، و کاربر هم بدون دردسر با محصول کار میکند. تا وقتی فقط یک نما داریم، این مدل ساده و قابل فهم است. حتی اگر کمی دادهی اضافه هم در پاسخها باشد، هنوز مسئلهی بزرگی به نظر نمیرسد.
اما محصول که جلوتر میرود، نماها هم شبیه هم نمیمانند. برنامهی موبایل میخواهد پاسخها سبکتر باشند، چون صفحه کوچکتر است و شبکه همیشه پایدار نیست. نسخهی وب شاید به دادههای بیشتری برای ساختن یک صفحهی کامل نیاز داشته باشد. پنل مدیریت هم اصلاً جنس دیگری از اطلاعات میخواهد؛ جزئیات بیشتر، وضعیتهای داخلی، ابزارهای جستوجو، و دادههایی که نباید در دسترس کاربر عادی باشد.
اینجاست که یک API عمومی کمکم زیر فشار قرار میگیرد. اگر بخواهیم همه را با همان پاسخ واحد راضی کنیم، یا پاسخها بیش از حد بزرگ و شلوغ میشوند، یا هر نما مجبور میشود خودش چندین درخواست بزند و دادهها را کنار هم بچیند. نتیجه معمولاً این است: بخشی از پیچیدگی بکاند، آرامآرام به سمت فرانتاند هل داده میشود.
وقتی نیازهای وب، موبایل و پنل مدیریت واقعاً از هم فاصله میگیرند، یک پاسخ واحد ممکن است دیگر سادهترین راه نباشد؛ ممکن است فقط ظاهر سادهای داشته باشد و پیچیدگی را به جای دیگری منتقل کند.
بکاند ویژهی نما یا Backend for Frontend، که معمولاً به اختصار BFF گفته میشود، پاسخی به همین وضعیت است. ایدهاش این است که بهجای ساختن یک API عمومی که قرار است همهی نماها را راضی کند، برای هر تجربهی کاربری مهم، یک لایهی بکاند نزدیکتر به همان نما بسازیم. این لایه میتواند دادهها را از چند سرویس یا چند API بگیرد، آنها را به شکل مناسب کنار هم بگذارد، چیزهای اضافه را حذف کند، و پاسخی برگرداند که دقیقاً به درد همان نما بخورد.
مثلاً برنامهی موبایل شاید برای صفحهی سفارش فقط نام محصول، قیمت، وضعیت ارسال و یک دکمهی اقدام لازم داشته باشد. اما پنل مدیریت برای همان سفارش، شناسههای داخلی، وضعیت پرداخت، تاریخچهی تغییرات، یادداشت پشتیبانی و چند فیلتر دیگر میخواهد. اگر هر دو را با یک پاسخ واحد تغذیه کنیم، یا موبایل دادهی زیادی میگیرد، یا پنل مدیریت دادهی کمی. BFF کمک میکند هرکدام چیزی را بگیرند که برای تجربهی خودشان مناسبتر است.
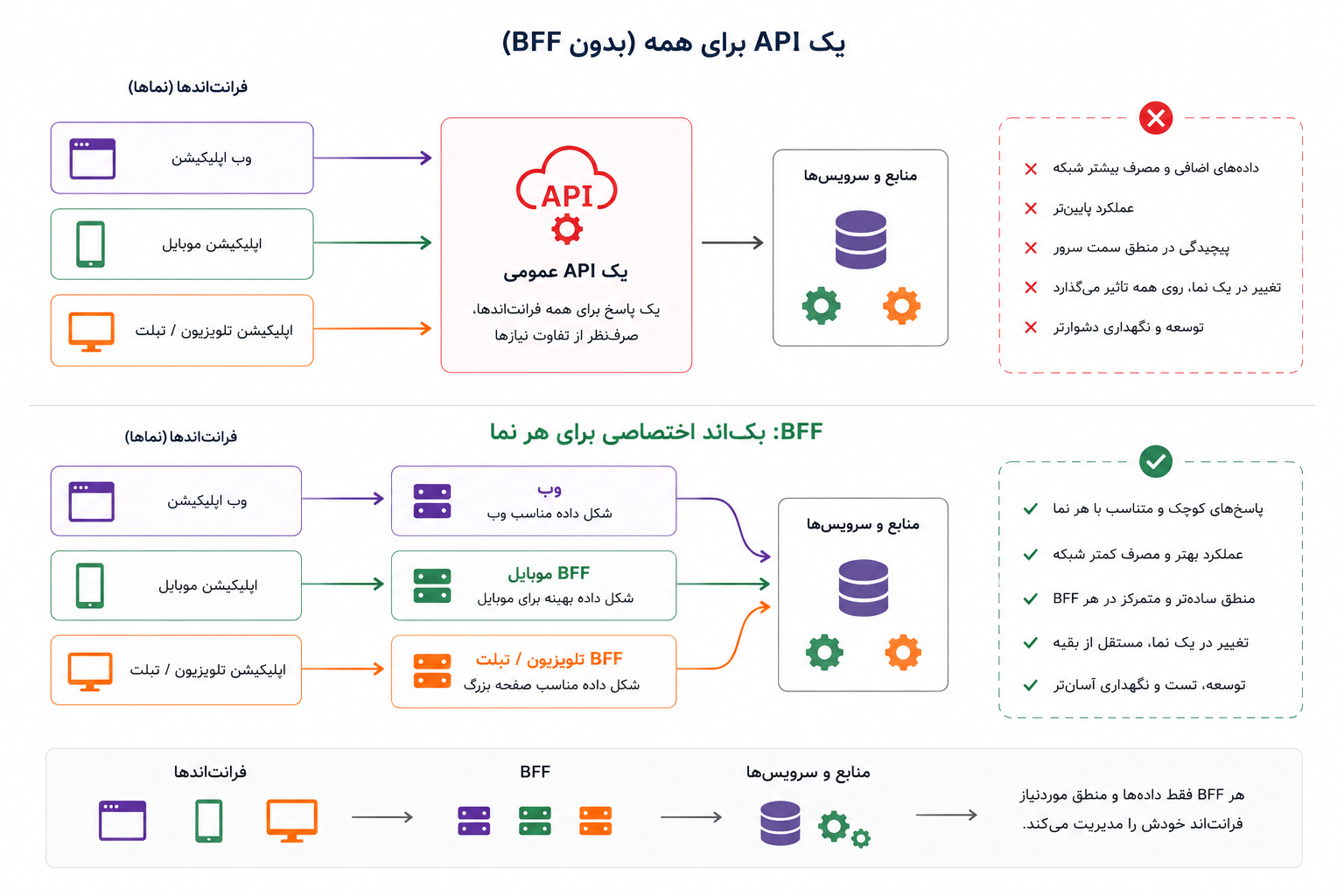
در این تصویر، اصل مسئله دیده میشود: وقتی نیاز نماها از هم فاصله میگیرد، یک پاسخ عمومی ممکن است همه را کمی ناراضی کند؛ اما BFF میتواند پاسخ هر نما را به شکل مناسب خودش آماده کند.
البته اینجا هم همان قاعدهی همیشگی برقرار است: نباید زودتر از درد واقعی، درمان پیچیده بیاوریم. اگر محصول کوچک است، فقط یک کلاینت دارد، یا تفاوت نیازها هنوز جدی نشده، ساختن چند لایهی BFF بیشتر از اینکه کمک کند، نگهداری را سخت میکند. هر لایهی تازه یعنی کد تازه، خطای تازه، آزمون تازه، مالکیت تازه و هماهنگی تازه.
| وضعیت | احتمالاً چه کاری بهتر است؟ |
|---|---|
| فقط یک نما داریم و نیازها سادهاند | همان API عمومی کافی است. |
| وب و موبایل تفاوتهای کوچک دارند | شاید کمی بهبود در همان API کافی باشد. |
| هر نما دادهی متفاوت، شکل متفاوت و سرعت متفاوت میخواهد | BFF میتواند ارزشمند شود. |
| هر صفحه برای خودش BFF جدا میخواهد | احتمالاً داریم بیش از حد خرد میکنیم. |
BFF یعنی برای هر صفحه یا هر دکمه، یک بکاند جدا بسازیم؟ نه. BFF زمانی معنا دارد که تفاوت تجربهها واقعی، تکرارشونده و پرهزینه شده باشد؛ نه وقتی فقط میخواهیم معماری را پیچیدهتر نشان بدهیم.
یک نشانه که میگوید شاید وقت BFF رسیده است
اگر فرانتاند برای ساختن یک صفحه باید چندین API را صدا بزند، دادههای زیادی را دور بریزد، پاسخها را خودش به هم بچسباند، و مدام درگیر جزئیات داخلی بکاند شود، احتمالاً بخشی از مسئولیت اشتباه جابهجا شده است. در این نقطه، یک لایهی BFF میتواند پیچیدگی را به جایی برگرداند که بهتر میتواند آن را مدیریت کند.
برای من، BFF یعنی احترام گذاشتن به این واقعیت که همهی مصرفکنندهها یکسان نیستند. وب، موبایل و پنل مدیریت شاید از یک محصول حرف بزنند، اما تجربهی یکسانی نمیسازند. پس گاهی لازم است بکاند هم بهجای یک پاسخ عمومی برای همه، پاسخهایی نزدیکتر به نیاز هر نما فراهم کند؛ البته فقط وقتی این تفاوت واقعاً به اندازهی کافی جدی شده باشد.
وقتی ورودی سیستم شلوغ میشود و سرویسها هم با هم حرف دارند
تا اینجا محصول چند نمای متفاوت پیدا کرده است: وب، موبایل و پنل مدیریت. هرکدام هم نیاز خودش را دارد و کمکم مسیرهای بیشتری به بکاند باز شدهاند. اول شاید همهچیز ساده به نظر برسد؛ چند درخواست از بیرون میآید و چند پاسخ برمیگردد. اما بعد از مدتی سؤالهای تازهای پیدا میشوند: چه کسی حق دارد وارد سیستم شود؟ اگر یک کاربر یا یک ربات بیش از اندازه درخواست فرستاد چه کنیم؟ درخواستها را کجا ثبت و ردیابی کنیم؟ نسخههای مختلف API را چطور مدیریت کنیم؟
اگر برای هر سرویس جداگانه همین منطقها را بنویسیم، خیلی زود با تکرار و آشفتگی روبهرو میشویم. یک سرویس احراز هویت را یکجور انجام میدهد، سرویس دیگر محدودسازی درخواست را جور دیگری پیاده میکند، و لاگها هم هرکدام شکل خودشان را دارند. نتیجه این میشود که ورودی سیستم به جای یک مسیر قابل فهم، تبدیل میشود به چند در کوچک و پراکنده که هرکدام قانون خودش را دارد.
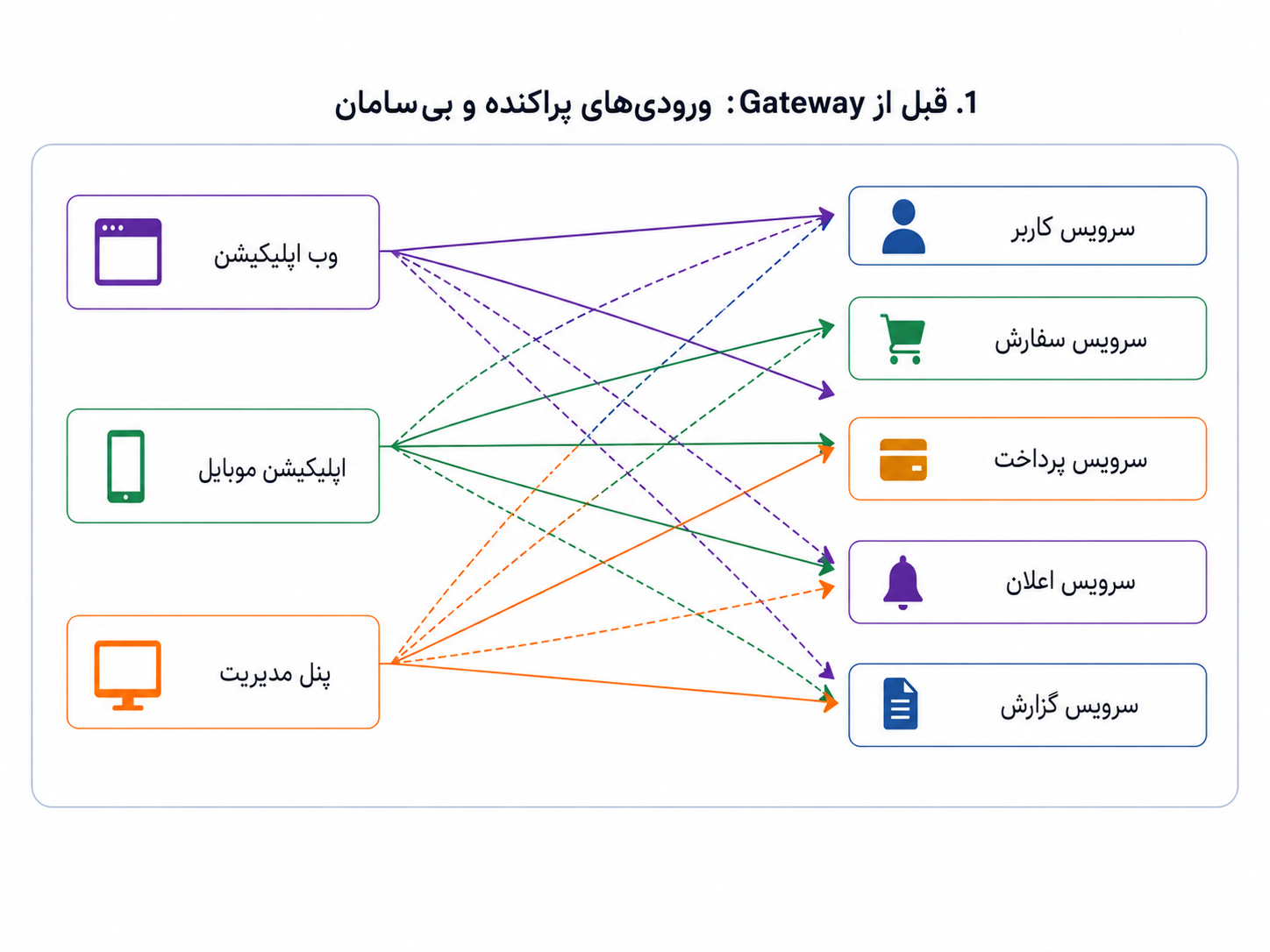
وقتی هر نما مستقیم به چند مسیر و سرویس وصل میشود، کنترل ورودیها سختتر و پراکندهتر میشود.
اینجاست که API Gateway معنا پیدا میکند. Gateway را میتوان مثل در ورودی آگاهانهی سیستم دید؛ جایی که درخواستهای بیرونی از آن عبور میکنند و بعد به سرویس مناسب میرسند. این لایه میتواند بخشی از کارهای مشترک را متمرکزتر کند: احراز هویت، محدودسازی نرخ درخواست، مسیریابی، ثبت لاگ، کنترل دسترسی و گاهی تبدیل شکل درخواست یا پاسخ.
API Gateway برای مدیریت ورودیهای بیرونی سیستم است. یعنی جایی میان کلاینتها و سرویسهای داخلی مینشیند تا هر سرویس مجبور نباشد همهی دغدغههای مشترک ورودی را دوباره از نو حل کند.
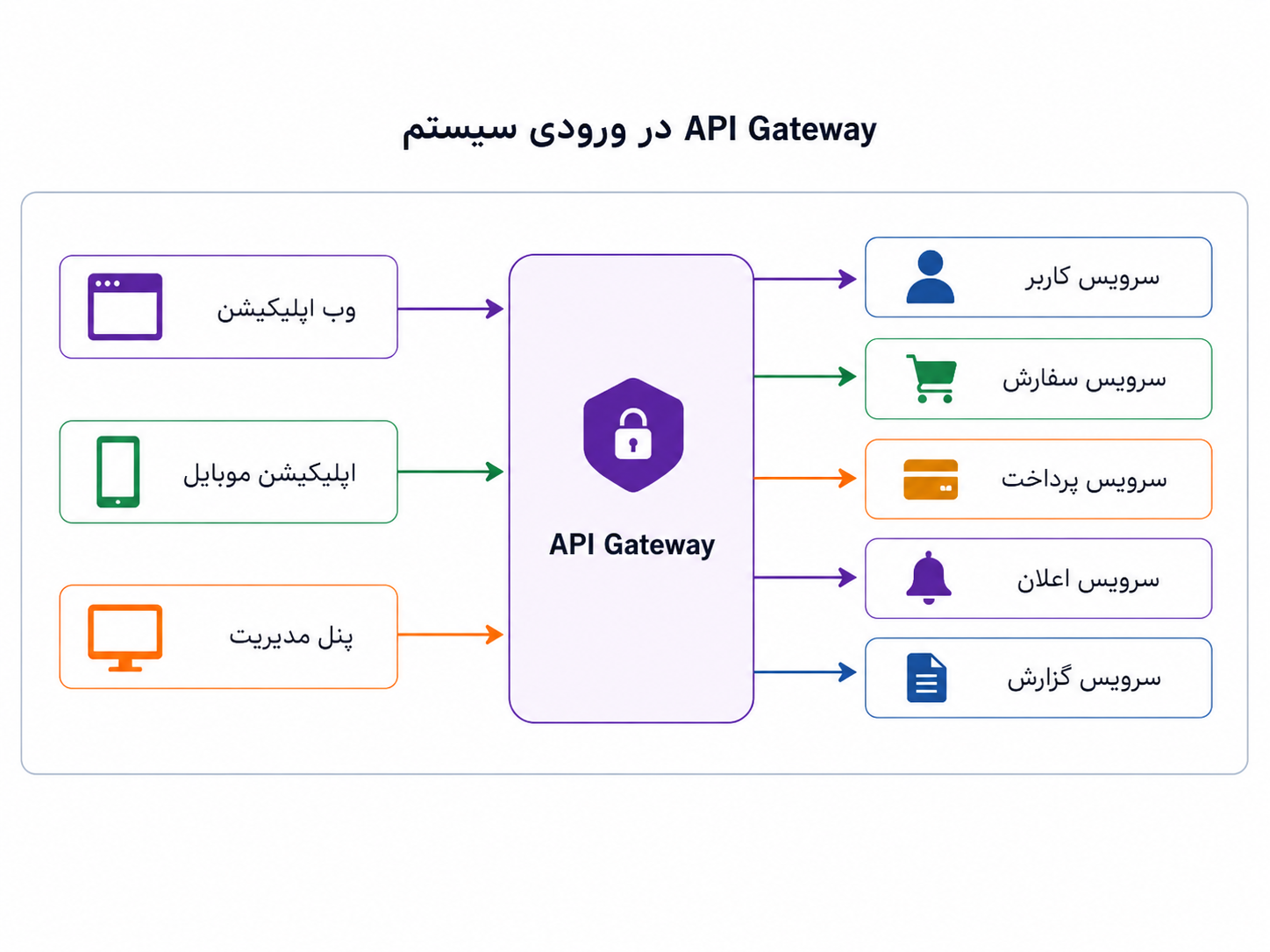
در این مدل، درخواستهای بیرونی اول از یک نقطهی مشخص عبور میکنند و بعد به سرویس مناسب میرسند.
اینجا ممکن است یک سؤال طبیعی پیش بیاید: مگر در بخش قبل نگفتیم BFF هم بین فرانتاند و بکاند مینشیند؟ پس Gateway چه فرقی با BFF دارد؟ فرق اصلی در نیت و مسئولیت آنهاست. BFF نزدیک به تجربهی کاربری است و میپرسد «این نما دقیقاً چه دادهای و با چه شکلی لازم دارد؟» اما Gateway نزدیک به مرز ورودی سیستم است و میپرسد «این درخواست اصلاً اجازهی ورود دارد؟ به کدام سرویس باید برود؟ چطور محدود، ثبت و ردیابی شود؟»
BFF پاسخ را برای نیاز یک نما شکل میدهد؛ Gateway ورود درخواستها به سیستم را مدیریت میکند. ممکن است در یک معماری هر دو را داشته باشیم: کلاینتها اول از Gateway عبور کنند و بعد، بسته به نیاز، به BFF وب، BFF موبایل یا سرویسهای داخلی برسند.
| پرسش | BFF | API Gateway |
|---|---|---|
| به چه چیزی نزدیکتر است؟ | تجربهی کاربری و نیاز هر نما | مرز ورودی سیستم |
| دغدغهی اصلی چیست؟ | شکلدهی پاسخ مناسب برای وب، موبایل یا پنل مدیریت | ورود امن، مسیریابی، محدودسازی و ثبت درخواستها |
| منطق کسبوکار کجا باید باشد؟ | تا حد ممکن نه در BFF؛ فقط ترکیب و آمادهسازی دادهی نما | نباید در Gateway پخش شود؛ Gateway جای منطق محصول نیست |
| چه زمانی معنا پیدا میکند؟ | وقتی نیاز نماها واقعاً متفاوت شده باشد | وقتی ورودیها زیاد، حساس یا پراکنده شده باشند |
اما این تمرکز یک دام هم دارد. هرچه چیزهای بیشتری را از یک نقطه عبور میدهیم، باید بیشتر مراقب باشیم همان نقطه به گلوگاه یا محل خوابیدن کل سیستم تبدیل نشود. Gateway قرار نیست یک سرور تنها و قهرمان باشد که اگر از کار افتاد، همهی مسیرهای ورود به سیستم هم از کار بیفتند. Gateway یک نقش معماری است، نه الزاماً یک نمونهی منفرد.
وقتی ورودیهای سیستم را از یک Gateway عبور میدهیم، کنترل و نظم بیشتری به دست میآوریم؛ اما همزمان باید مراقب باشیم Gateway به «نقطهی شکست واحد» (Single Point of Failure) تبدیل نشود. در عمل، Gateway معمولاً باید چند نمونهی فعال داشته باشد، پشت بارپخشکننده قرار بگیرد، پایش و هشدار درست داشته باشد، و در برابر افزایش ناگهانی درخواستها تابآور باشد.
داستان همینجا تمام نمیشود. فرض کنیم محصول بزرگتر شده و دیگر پشت صحنه فقط یک بکاند ساده نداریم. سرویس سفارش با سرویس پرداخت حرف میزند، پرداخت با کیف پول، سفارش با اعلان، و گزارشگیری با چند بخش دیگر. حالا مسئله فقط «ورود درخواست از بیرون» نیست؛ مسئلهی تازه این است که سرویسهای داخلی چگونه با هم حرف بزنند.
اینجا سؤالها عوض میشوند. اگر سرویس سفارش کند شد، از کجا بفهمیم مشکل از خودش بوده یا از پرداخت؟ اگر ارتباط بین دو سرویس شکست، تکرار درخواست چگونه انجام شود؟ ارتباط داخلی سرویسها امن است؟ اگر بخواهیم فقط بخشی از ترافیک را به نسخهی تازهی یک سرویس بفرستیم، این کار کجا مدیریت شود؟ آیا همهی این منطقها باید در کد تکتک سرویسها تکرار شوند؟
Service Mesh برای چنین مسئلهای مطرح میشود. اگر API Gateway بیشتر به در ورودی شهر شبیه باشد، Service Mesh بیشتر شبیه شبکهی خیابانها و چراغها و تابلوهایی است که رفتوآمد درون شهر را قابل کنترل و قابل مشاهده میکند. این لایه روی ارتباط میان سرویسهای داخلی تمرکز دارد: ردیابی درخواستها، کنترل ترافیک، امنیت ارتباط سرویس به سرویس، سیاستهای تکرار درخواست، و مشاهدهپذیری بهتر.
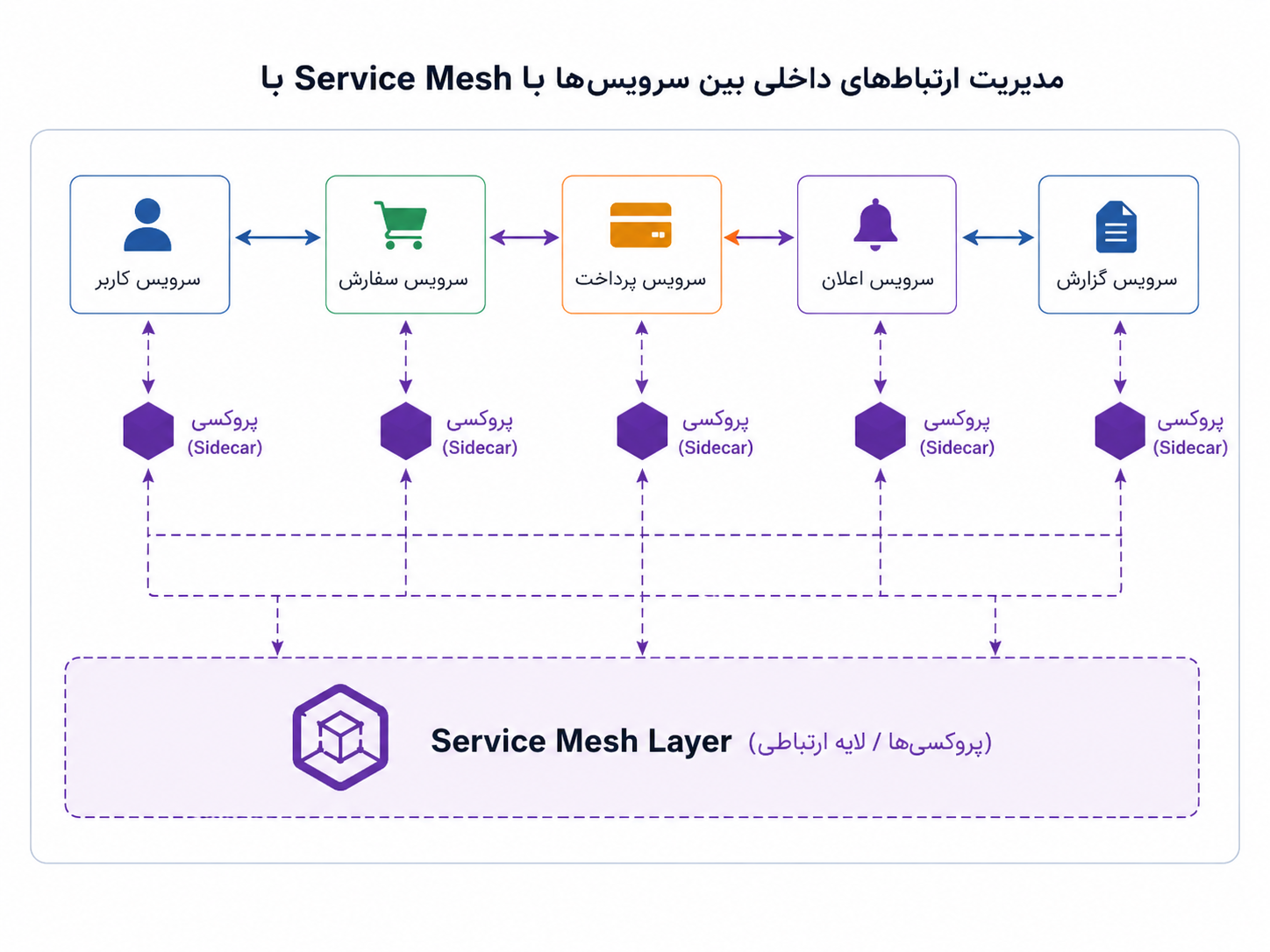
اگر Gateway ورودی سیستم را سامان میدهد، Service Mesh گفتوگوی درونی سرویسها را قابل مشاهدهتر و قابل کنترلتر میکند.
Service Mesh را نباید فقط چون مدرن و جذاب است وارد سیستم کنیم. اگر چند سرویس محدود داریم و ارتباطها سادهاند، این لایه میتواند خودش به منبع تازهای از پیچیدگی تبدیل شود.
برای سادهتر شدن تفاوت این سه، میشود اینطور نگاه کرد:
| مفهوم | بیشتر کجا مینشیند؟ | مسئلهی اصلی که حل میکند | خطر مهم اگر بد طراحی شود |
|---|---|---|---|
| BFF | نزدیک به هر نمای کاربری | آمادهسازی پاسخ مناسب برای وب، موبایل یا پنل مدیریت | ممکن است منطق محصول را تکهتکه و پخش کند. |
| API Gateway | میان کلاینتها و سرویسهای داخلی | مدیریت ورودی بیرونی، مسیریابی، احراز هویت، محدودسازی درخواست | میتواند گلوگاه یا نقطهی شکست واحد شود. |
| Service Mesh | میان خود سرویسهای داخلی | مدیریت ارتباط سرویس به سرویس، ردیابی، امنیت داخلی، کنترل ترافیک | میتواند پیچیدگی عملیاتی و عیبیابی را بیشتر کند. |
چه زمانی هنوز به Service Mesh نیاز نداریم؟
اگر تعداد سرویسها کم است، ارتباطها سادهاند، مشاهدهپذیری پایهای داریم و مشکل جدی در مدیریت ترافیک داخلی نداریم، احتمالاً Service Mesh زود است. در چنین مرحلهای، ساده نگه داشتن معماری ارزشمندتر از افزودن یک لایهی عملیاتی تازه است.
برای من، تفاوت اصلی این سه در محل درد است. اگر درد ما در تفاوت نیاز نماهاست، BFF میتواند کمک کند. اگر درد ما در ورودی سیستم است، یعنی کلاینتها زیاد شدهاند، احراز هویت و مسیریابی و کنترل درخواستها پراکنده شده، Gateway قابل بررسی است. اگر درد ما در درون سیستم است، یعنی سرویسها زیاد شدهاند و گفتوگوی میان آنها سخت، کند یا نامرئی شده، آن وقت Service Mesh معنا پیدا میکند.
پس باز هم همان قاعدهی کلی تکرار میشود: ابزار را از روی اسمش انتخاب نکنیم؛ از روی دردی انتخاب کنیم که واقعاً در سیستم پیدا شده است.
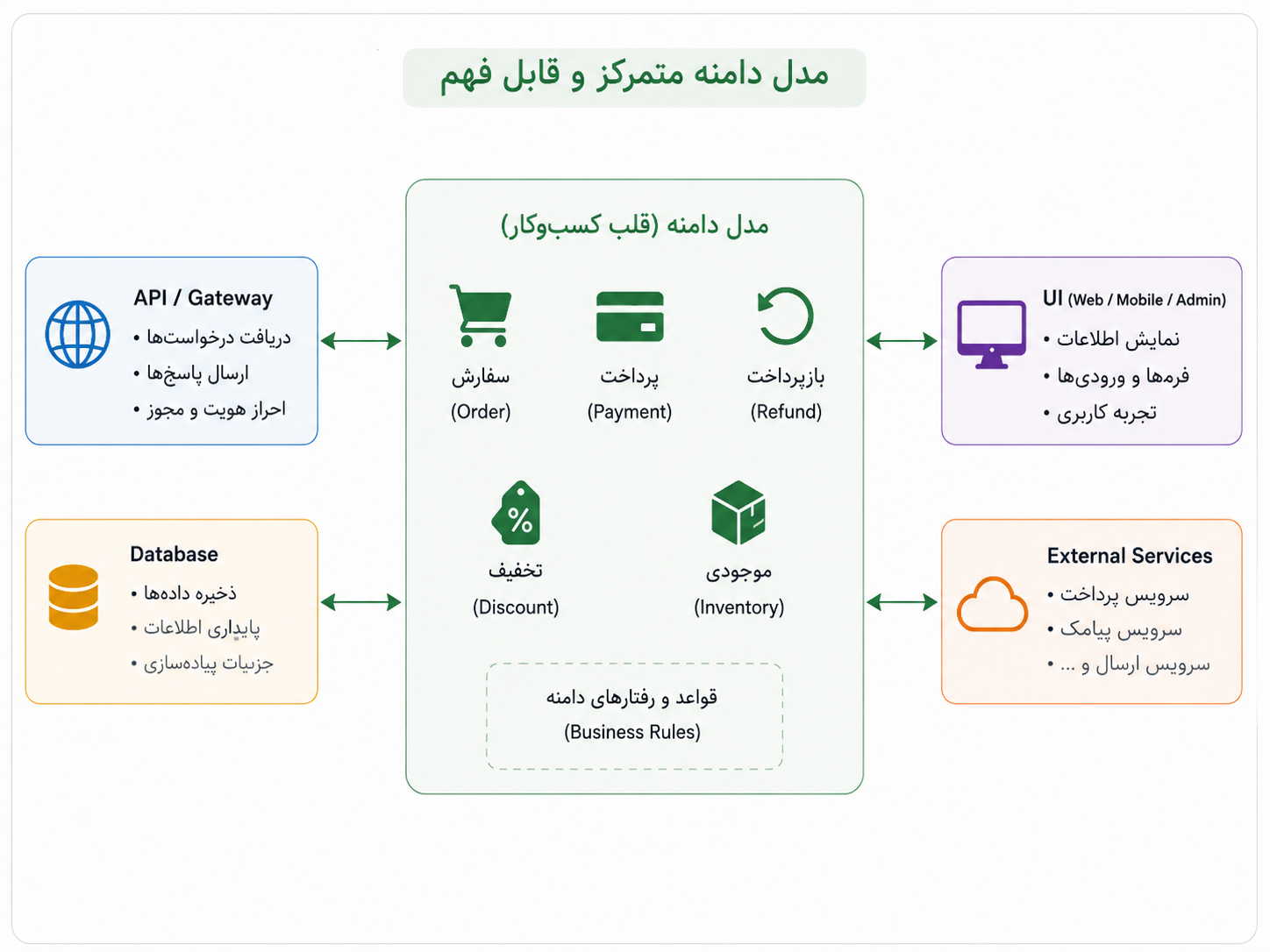
وقتی زبان کسبوکار در کد گم میشود
اوایل کار، ثبت سفارش شاید خیلی ساده به نظر برسد. کاربر چیزی را انتخاب میکند، پرداخت انجام میشود، سفارش ثبت میشود و تمام. در چنین مرحلهای، چند تابع ساده و چند مسیر روشن شاید کاملاً کافی باشند. هنوز نه وضعیتهای زیادی داریم، نه قانونهای ریز و درشت، نه استثناهایی که هر هفته تغییر کنند.
اما محصول که رشد میکند، سفارش دیگر فقط «سفارش» نیست. تخفیف اضافه میشود، لغو سفارش میآید، بازپرداخت مطرح میشود، موجودی باید کنترل شود، وضعیت پرداخت اهمیت پیدا میکند، پشتیبانی میخواهد بعضی چیزها را دستی تغییر دهد، و برای هرکدام هم چند قاعدهی کوچک اما مهم داریم. کمکم میبینیم چیزی که در ظاهر یک قابلیت ساده بود، در عمل تبدیل شده به مجموعهای از تصمیمهای کسبوکاری.
مشکل از جایی شروع میشود که این تصمیمها در کد پخش میشوند. کمی از منطق سفارش در کنترلر است، کمی در مدل پایگاه داده، کمی در سرویس پرداخت، کمی در پنل مدیریت، و کمی هم در یک تابع کمکی قدیمی که معلوم نیست دقیقاً چرا نوشته شده است. حالا اگر بخواهیم یک قانون کوچک را تغییر دهیم، باید چند جا را بگردیم و امیدوار باشیم چیزی از قلم نیفتاده باشد.
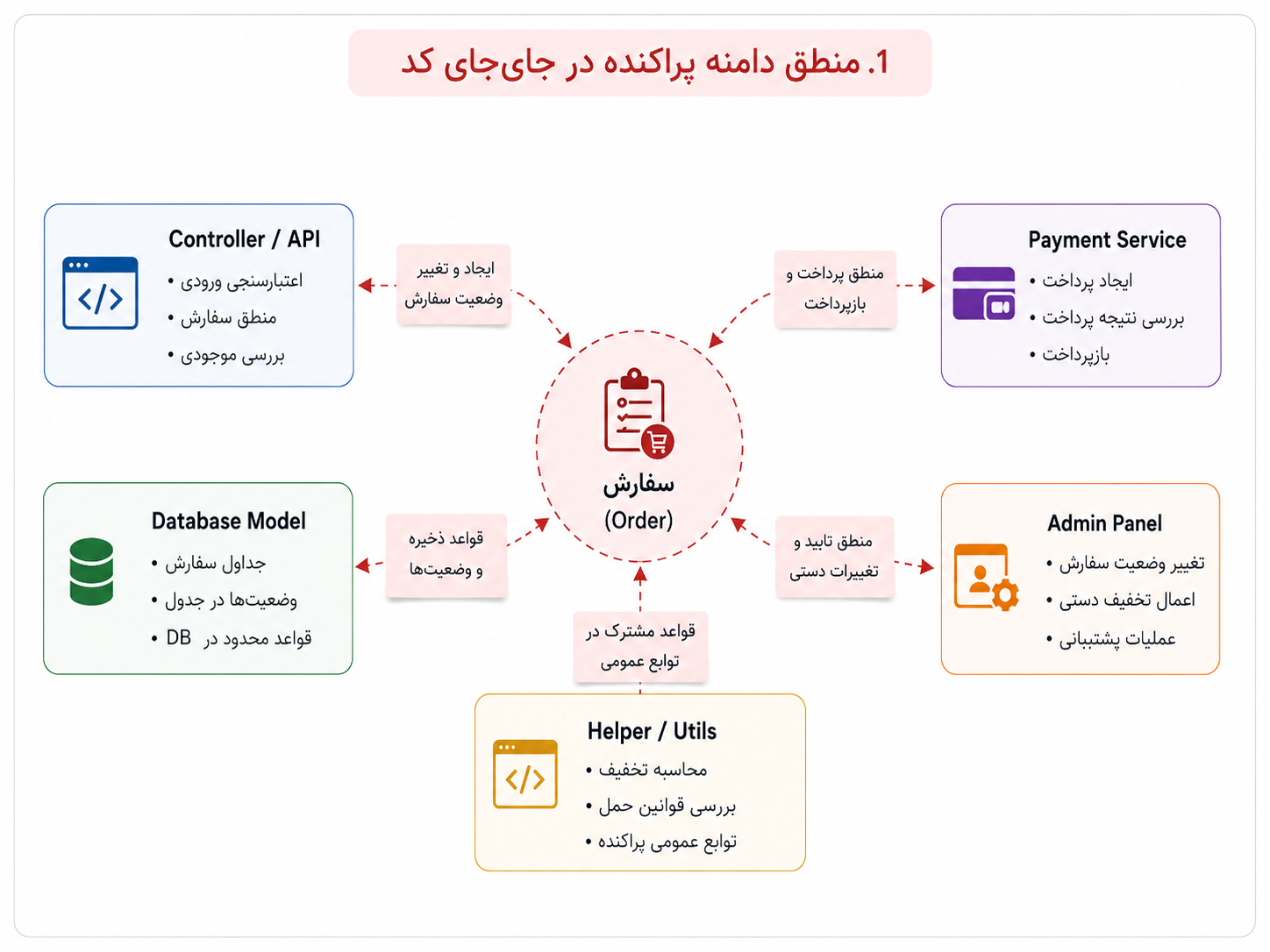
در این وضعیت، مشکل فقط زیاد شدن کد نیست؛ مشکل این است که زبان کسبوکار در میان جزئیات فنی گم شده است.
اینجاست که طراحی دامنهمحور یا Domain Driven Design، که معمولاً DDD گفته میشود، معنا پیدا میکند. من DDD را پیش از آنکه یک مجموعه اصطلاح یا الگوی پیادهسازی بدانم، تلاشی برای جدی گرفتن زبان مسئله میفهمم. یعنی اگر در کسبوکار ما مفاهیمی مثل سفارش، پرداخت، بازپرداخت، تخفیف، موجودی و تسویه مهماند، در کد هم باید جای روشن و قابل فهم داشته باشند.
DDD میگوید کد نباید فقط بازتاب جدولها، کنترلرها و مسیرهای فنی باشد. کد باید تا حد ممکن زبان مسئله را هم نشان دهد؛ همان واژهها، همان قاعدهها و همان مرزهایی که اهل کسبوکار با آنها فکر میکنند.
در نگاه دامنهمحور، به جای اینکه قانونهای مهم را در گوشهوکنار سیستم پخش کنیم، تلاش میکنیم هستهی مسئله را بهتر بشناسیم و مدل کنیم. مثلاً سفارش فقط یک ردیف در جدول نیست؛ رفتاری دارد، وضعیت دارد، قاعده دارد. پرداخت فقط یک فراخوانی به سرویس بیرونی نیست؛ نتیجه، شکست، بازگشت و اثر روی سفارش دارد. تخفیف فقط یک عدد کمشده از قیمت نیست؛ قانون اعتبار، زمان، محدودیت و شرایط استفاده دارد.
وقتی مدل دامنه روشنتر باشد، تغییر دادن یک قانون کسبوکاری کمتر شبیه جستوجو در تاریکی میشود.
البته باید مراقب باشیم DDD را هم به یک نمایش معماری تبدیل نکنیم. طراحی دامنهمحور یعنی از روز اول دهها کلاس، اصطلاح، پوشه و مراسم پیچیده بسازیم؟ نه. اگر مسئله ساده است و قانونهای کسبوکار هنوز کم و پایدارند، ساختار ساده میتواند کاملاً کافی باشد. DDD وقتی ارزشمند میشود که دامنه واقعاً پیچیده، تغییرپذیر و پرقاعده شده باشد؛ جایی که فهم مشترک از مسئله، خودش تبدیل به بخشی از کیفیت نرمافزار میشود.
این بحث به نقد سادهانگارانه از «مسئولیت واحد» هم نزدیک است. اگر فقط از روی اسم کلاسها و تابعها دربارهی مسئولیت حرف بزنیم، ممکن است مسئلهی اصلی را نبینیم. مسئولیت در عمل به این برمیگردد که تغییرها از کجا میآیند و کدام قاعدههای کسبوکار باید کنار هم فهمیده و نگهداری شوند. من دربارهی این زاویه، جداگانه در نوشتهی نقدی بر اصل مسئولیت واحد حرف زدهام.
DDD یعنی هر پروژهای را از روز اول با واژههای سنگین، لایههای زیاد و مدلهای پیچیده شروع کنیم؟ نه. DDD یعنی وقتی مسئلهی کسبوکار جدی و پیچیده شد، اجازه ندهیم زبان آن در میان جزئیات فنی گم شود.
برای تشخیص اینکه هنوز ساختار ساده کافی است یا باید جدیتر به دامنه فکر کنیم، این مقایسه کمک میکند:
| وضعیت | احتمالاً چه نگاهی بهتر است؟ |
|---|---|
| محصول تازه است و قانونهای کسبوکار کماند | ساده نگه داشتن ساختار کافی است. |
| چند مفهوم کسبوکاری مدام در حال تغییرند | باید نامها و مرزهای دامنه را جدیتر بگیریم. |
| یک قانون در چند جای کد تکرار شده است | نشانهی پخش شدن منطق دامنه است. |
| تغییر یک قاعدهی کوچک چند بخش نامرتبط را درگیر میکند | مدل دامنه احتمالاً جای روشن و متمرکزی ندارد. |
| تیم فنی و تیم کسبوکار از واژههای متفاوت برای یک چیز استفاده میکنند | نیاز به زبان مشترک جدیتر شده است. |
یک نشانهی ساده که میگوید دامنه را خوب مدل نکردهایم
اگر برای توضیح یک قانون کسبوکاری، مجبوریم اول مسیر کنترلر، شکل جدول، چند شرط پراکنده و چند تابع کمکی را توضیح دهیم، احتمالاً مدل دامنهی ما به زبان مسئله نزدیک نیست. در چنین وضعیتی، کد شاید کار کند، اما فهم آن به مرور سخت و پرهزینه میشود.
برای من، DDD قبل از آنکه جواب آماده باشد، یک یادآوری مهم است: نرمافزار فقط با فریمورک و پایگاه داده و API ساخته نمیشود؛ با فهم درست مسئله هم ساخته میشود. هرچه قواعد کسبوکار مهمتر و تغییرپذیرتر شوند، لازم است این فهم در خود کد هم دیده شود، نه فقط در ذهن چند نفر یا در چند سند پراکنده.
وقتی این را بپذیریم، پرسش بعدی طبیعی میشود: اگر منطق دامنه قلب سیستم است، چطور نگذاریم زیر فشار پایگاه داده، فریمورک، API بیرونی یا ابزارهای دیگر له شود؟ این همان جایی است که معماری ششضلعی وارد داستان میشود.
وقتی قلب سیستم نباید اسیر ابزارهای اطرافش شود
در بخش قبل گفتیم منطق دامنه باید جای روشنتری در کد داشته باشد. یعنی اگر سفارش، پرداخت، بازپرداخت و تخفیف برای کسبوکار مهماند، نباید در کنترلرها، مدلهای پایگاه داده و چند تابع پراکنده گم شوند. اما این فقط نصف ماجراست. حتی اگر مفاهیم دامنه را خوب پیدا کنیم، باز هم ممکن است آنها را زیر آوار ابزارها دفن کنیم.
فرض کنیم میخواهیم قانون لغو سفارش را تغییر دهیم. از نظر کسبوکار، قانون شاید ساده باشد: اگر سفارش هنوز وارد مرحلهی ارسال نشده، لغو مجاز است؛ اگر ارسال آغاز شده، باید چند شرط دیگر بررسی شود. اما وقتی وارد کد میشویم، میبینیم برای آزمودن همین قانون ساده باید پایگاه داده بالا باشد، فریمورک وب اجرا شود، سرویس پرداخت شبیهسازی شود، تنظیمات محیطی آماده باشد و چند جزئیات فنی دیگر هم همراهش بیاید. اینجا درد اصلی روشن میشود: منطق دامنه را داریم، اما هنوز آزاد نیست.
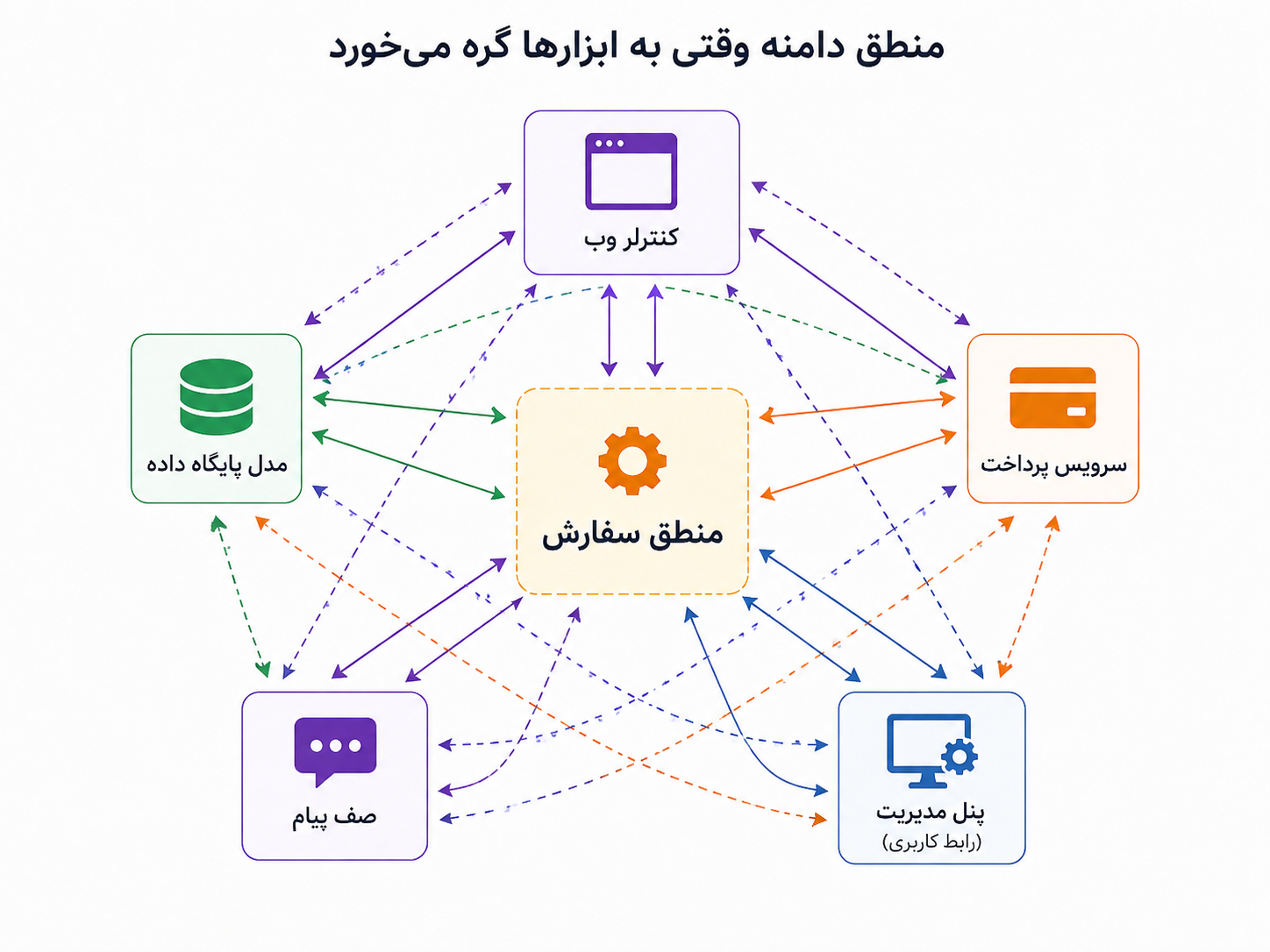
در این وضعیت، منطق سفارش در مرکز دیده میشود، اما از هر طرف به کنترلر، پایگاه داده، صف پیام، پنل مدیریت و سرویس پرداخت کشیده شده است.
معماری ششضلعی یا Hexagonal Architecture پاسخی به همین فشار است. ایدهی اصلیاش این نیست که حتماً کد را به شکل یک ششضلعی واقعی بچینیم یا از روز اول پوشههای زیاد بسازیم. حرف اصلی سادهتر است: هستهی سیستم، یعنی منطق اصلی کسبوکار، باید تا حد ممکن مستقل از ابزارهای بیرونی بماند. پایگاه داده، فریمورک وب، API پرداخت، صف پیام و رابط کاربری مهماند، اما نباید شکل فکر کردن دامنه را تعیین کنند.
معماری ششضلعی میگوید دامنه باید در مرکز بماند و ابزارها از بیرون به آن وصل شوند. یعنی ابزارها باید در خدمت منطق دامنه باشند، نه اینکه منطق دامنه را شبیه خودشان کنند.
نسبت این بحث با طراحی دامنهمحور مهم است. DDD کمک میکند بفهمیم «قلب مسئله» چیست و چه واژهها و قاعدههایی برای کسبوکار مهماند. معماری ششضلعی کمک میکند از همان قلب محافظت کنیم تا با تغییر پایگاه داده، فریمورک وب، سرویس پرداخت یا پیامرسان، منطق اصلی سیستم مدام زخمی نشود. پس این دو، دو جواب جدا برای یک مسئله نیستند؛ یکی بیشتر به فهم و مدلکردن دامنه کمک میکند، دیگری به مرزبندی و محافظت از آن مدل در برابر ابزارها.
DDD بیشتر میپرسد: «مسئلهی اصلی کسبوکار چیست و با چه زبان و مدلی باید آن را بفهمیم؟» معماری ششضلعی بیشتر میپرسد: «حالا که این مدل را جدی گرفتیم، چطور نگذاریم به دیتابیس، فریمورک، API بیرونی و جزئیات زیرساختی گره بخورد؟»
برای توضیح سادهی این معماری، دو واژهی مهم داریم: درگاه و سازگارکننده. درگاه یا Port یعنی هستهی سیستم میگوید من برای انجام کارم به چه قابلیتی نیاز دارم؛ مثلاً ذخیرهی سفارش، گرفتن نتیجهی پرداخت، ارسال پیام یا انتشار یک رخداد. سازگارکننده یا Adapter یعنی بخش بیرونی میآید و آن نیاز را با ابزار واقعی برآورده میکند؛ مثلاً با PostgreSQL، Redis، Kafka، یک API پرداخت یا هر ابزار دیگری.
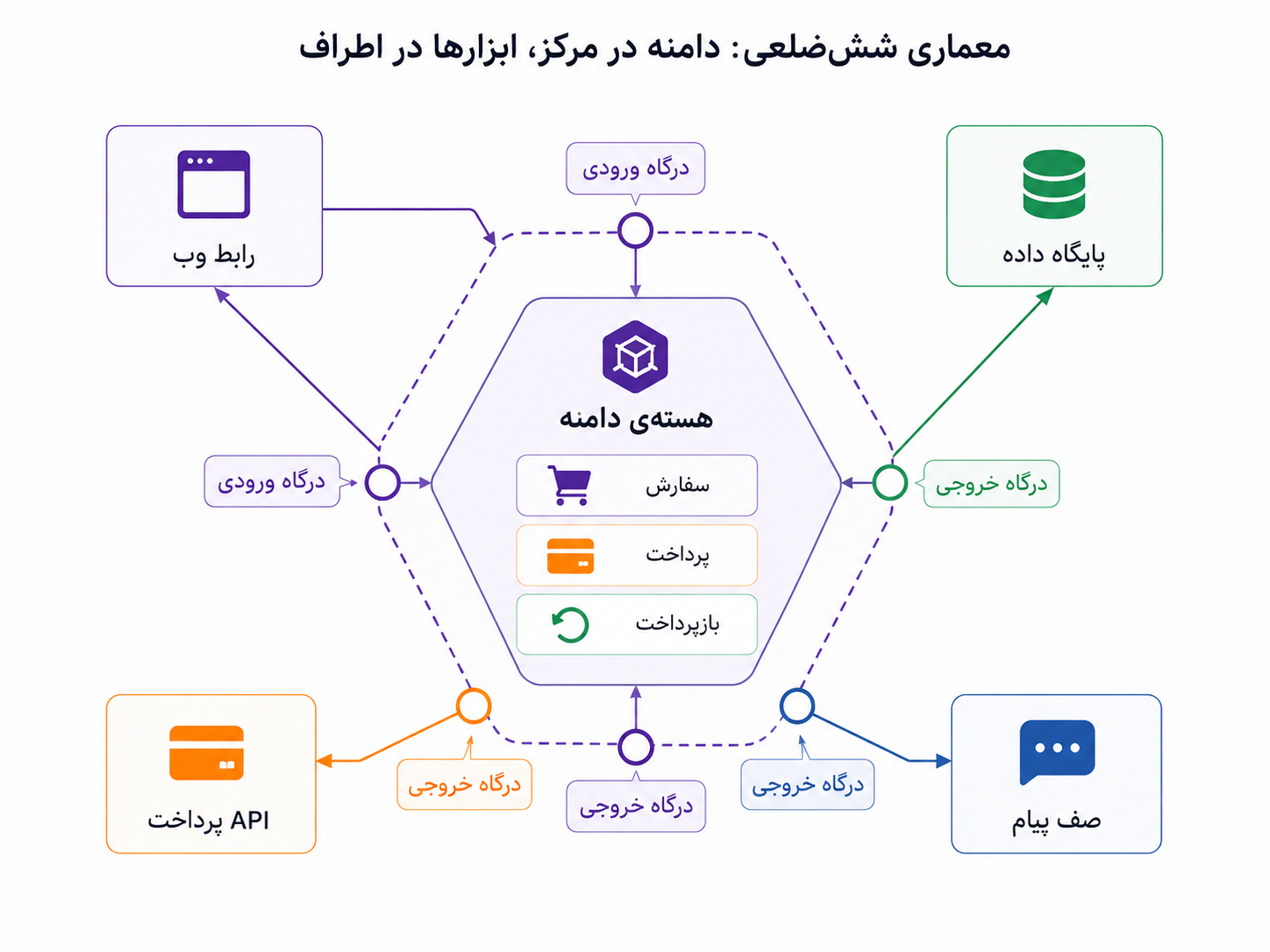
در این تصویر، دامنه در مرکز است. رابط وب، پایگاه داده، صف پیام و API پرداخت دور آن قرار گرفتهاند، نه در دل آن.
مثلاً هستهی سفارش لازم نیست بداند دادهها دقیقاً در کدام جدول ذخیره میشوند. کافی است بگوید «من به چیزی نیاز دارم که سفارش را ذخیره کند». بعد یک سازگارکنندهی واقعی میتواند این نیاز را با پایگاه داده پیاده کند. اگر روزی روش ذخیرهسازی عوض شد، نباید قانون لغو سفارش یا منطق بازپرداخت را از نو بنویسیم. تغییر باید بیشتر در لبهی سیستم رخ دهد، نه در قلب آن.
این جداسازی چند فایدهی مهم دارد. آزمون منطق دامنه سادهتر میشود، چون برای بررسی یک قانون کسبوکاری لازم نیست همهی ابزارهای بیرونی را بالا بیاوریم. تغییر ابزارها هم کمخطرتر میشود، چون هستهی سیستم کمتر به جزئیات آنها وابسته است. از همه مهمتر، مرز ذهنی سیستم روشنتر میشود: میفهمیم کدام بخش واقعاً منطق کسبوکار است و کدام بخش فقط راهی برای اتصال این منطق به جهان بیرون.
| وضعیت | اگر مرزها مبهم باشند | اگر مرز ششضلعی روشنتر باشد |
|---|---|---|
| تغییر قانون لغو سفارش | درگیر کنترلر، دیتابیس و سرویس پرداخت میشویم. | بیشتر در هستهی دامنه تغییر میدهیم. |
| آزمودن منطق بازپرداخت | به فریمورک، دیتابیس و تنظیمات محیطی وابسته میشویم. | میتوانیم منطق را با جایگزینهای سادهتر بیازماییم. |
| تعویض ابزار ذخیرهسازی | خطر دستزدن به منطق کسبوکار زیاد میشود. | تغییر بیشتر در سازگارکنندهی ذخیرهسازی رخ میدهد. |
| اتصال به سرویس پرداخت جدید | ممکن است قواعد پرداخت در همهجا پخش شوند. | سازگارکنندهی تازه میتواند پشت همان درگاه بنشیند. |
معماری ششضلعی یعنی برای هر پروژهی کوچک، از روز اول چندین لایه، درگاه، سازگارکننده و پوشه بسازیم؟ نه. اگر محصول هنوز ساده است و منطق کسبوکار کم و پایدار است، این حجم از جداسازی میتواند خودش هزینهی اضافی بسازد. ارزش این معماری وقتی بیشتر میشود که دامنه مهم، ابزارها متنوع، و تغییرات بیرونی پرهزینه شده باشند.
یک نشانه که میگوید مرز دامنه خوب محافظت نشده است
اگر برای تست یک قانون سادهی کسبوکار باید وبسرور، پایگاه داده، صف پیام و چند سرویس بیرونی را همزمان درگیر کنیم، احتمالاً منطق دامنه بیش از حد به ابزارها چسبیده است. در چنین وضعیتی، مشکل فقط کندی تست نیست؛ مشکل این است که فهم و تغییر قلب سیستم به جزئیات بیرونی وابسته شده است.
برای من، معماری ششضلعی ادامهی طبیعی DDD است. DDD کمک میکند بفهمیم چه چیزی قلب مسئله است؛ معماری ششضلعی کمک میکند آن قلب را از فشار ابزارها دور نگه داریم. نه چون ابزارها بیاهمیتاند، بلکه چون ابزارها باید قابل تعویض، قابل آزمون و در خدمت دامنه باشند.
وقتی هستهی دامنه جای روشنتری پیدا میکند، پرسش بعدی هم آرامآرام پیدا میشود: آیا همیشه یک مدل واحد برای خواندن و نوشتن کافی است؟ یا گاهی فشار گزارشگیری، نمایش داده و تغییرات پیچیده باعث میشود مدل خواندن و نوشتن را جدا ببینیم؟ این همان جایی است که کمکم به CQRS نزدیک میشویم.
وقتی خواندن و نوشتن نیازهای متفاوت پیدا میکنند
تا اینجا تلاش کردهایم قلب سیستم را بهتر بشناسیم و از ابزارهای اطرافش جدا نگه داریم. با طراحی دامنهمحور فهمیدیم سفارش، پرداخت، بازپرداخت و تخفیف فقط چند جدول نیستند؛ هرکدام رفتار و قاعده دارند. با معماری ششضلعی هم گفتیم این منطق نباید به فریمورک، پایگاه داده یا API بیرونی گره بخورد. اما وقتی سیستم بزرگتر میشود، فشار تازهای پیدا میشود: آیا همان مدلی که برای نوشتن و اجرای قانون مناسب است، برای خواندن، گزارشگیری و نمایش سریع هم مناسب میماند؟
فرض کنیم برای ثبت سفارش، مدل نسبتاً خوبی داریم. وقتی کاربر سفارش ثبت میکند، موجودی بررسی میشود، وضعیت پرداخت درست پیش میرود، تخفیف اعتبارسنجی میشود و قانونهای دامنه رعایت میشوند. این بخش از سیستم باید دقیق و سختگیر باشد؛ چون دارد وضعیت واقعی سیستم را تغییر میدهد.
اما از سمت دیگر، نیازهای خواندن آرامآرام زیاد میشوند. برنامهی موبایل فقط یک فهرست سبک و سریع از سفارشهای کاربر میخواهد. پنل مدیریت میخواهد سفارشها را بر اساس وضعیت پرداخت، شهر، روش ارسال، کد تخفیف، مبلغ، زمان ثبت و وضعیت پشتیبانی جستوجو کند. داشبورد مدیریتی تعداد سفارشهای امروز، مبلغ کل، سفارشهای لغوشده، میانگین زمان ارسال و نرخ بازپرداخت را میخواهد. اینها بیشتر از اینکه دنبال اجرای قانون باشند، دنبال نمای مناسب، سریع و قابل جستوجو از دادهها هستند.
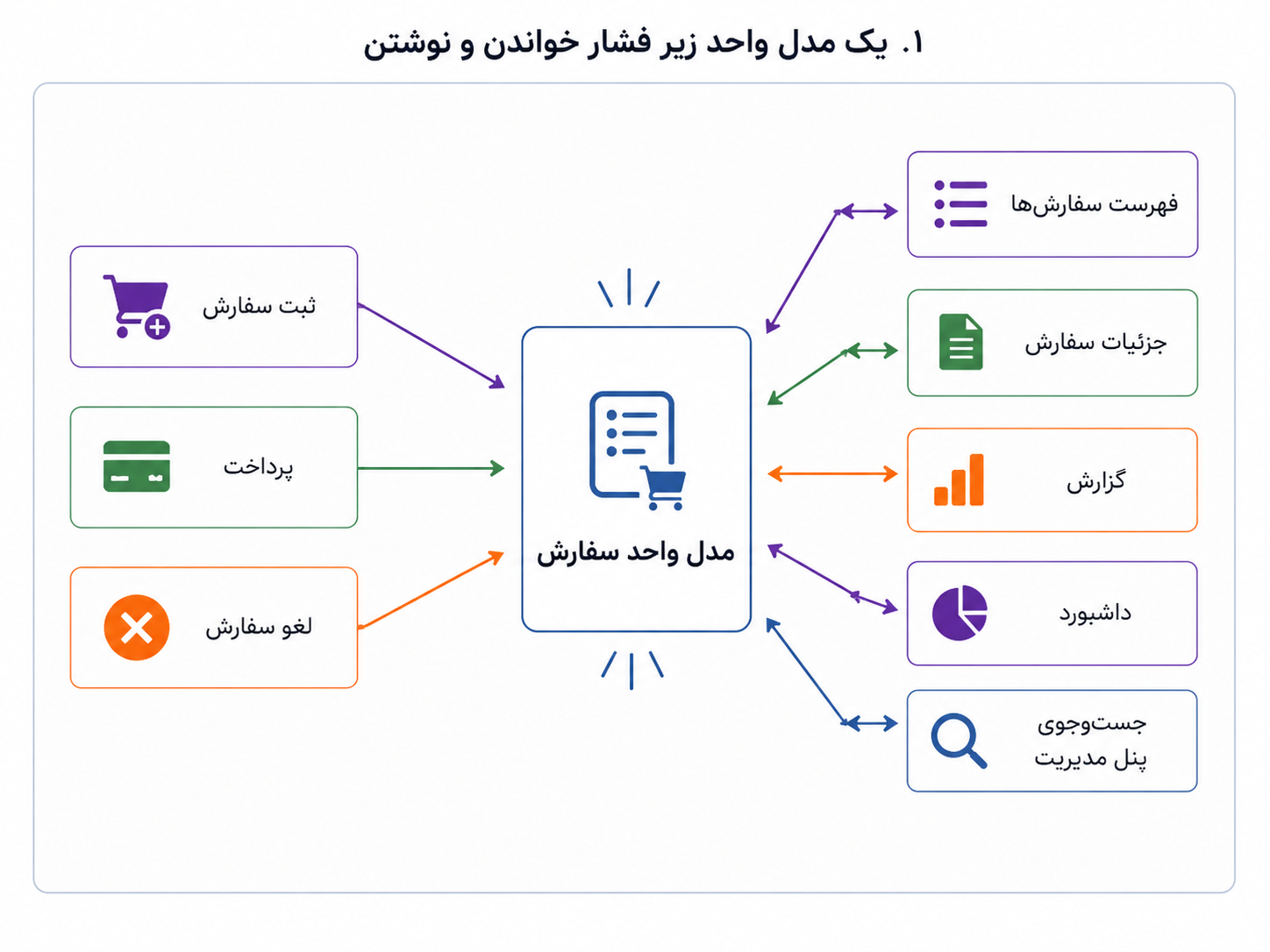
یک مدل واحد میتواند مدتی پاسخگو باشد، اما وقتی نیازهای خواندن و نوشتن از دو جهت متفاوت رشد میکنند، همان مدل کمکم زیر فشار میرود.
اینجاست که CQRS مطرح میشود. CQRS کوتاهشدهی Command Query Responsibility Segregation است و میتوان آن را «جداسازی مسئولیت فرمان و پرسوجو» ترجمه کرد. فرمان یعنی کاری که وضعیت سیستم را تغییر میدهد؛ مثل ثبت سفارش، پرداخت، لغو سفارش یا بازپرداخت. پرسوجو یعنی کاری که فقط داده را میخواند؛ مثل نمایش فهرست سفارشها، گرفتن جزئیات سفارش، ساختن گزارش یا نمایش داشبورد.
CQRS میگوید گاهی بهتر است مسیر نوشتن و مسیر خواندن را جدا ببینیم. نوشتن بیشتر درگیر درستی، قواعد دامنه و تغییر وضعیت است؛ خواندن بیشتر درگیر سرعت، شکل مناسب داده، جستوجو و نمایش است.
در سادهترین برداشت، CQRS نمیگوید حتماً باید دو پایگاه داده، صف پیام، Kafka یا Event Sourcing داشته باشیم. گاهی جداسازی فقط در سطح کد است: یک مسیر برای فرمانها و تغییر وضعیت، یک مسیر برای پرسوجوها و خواندن داده. در مرحلههای پیچیدهتر، ممکن است مدل خواندن جدا بسازیم؛ مثلاً جدولی آماده برای گزارش یا نمایی سبک برای موبایل. در سیستمهای بزرگتر، حتی ممکن است پایگاه دادهی خواندن و نوشتن هم جدا شوند. اما اینها پلههای مختلفاند، نه تعریف اجباری CQRS.
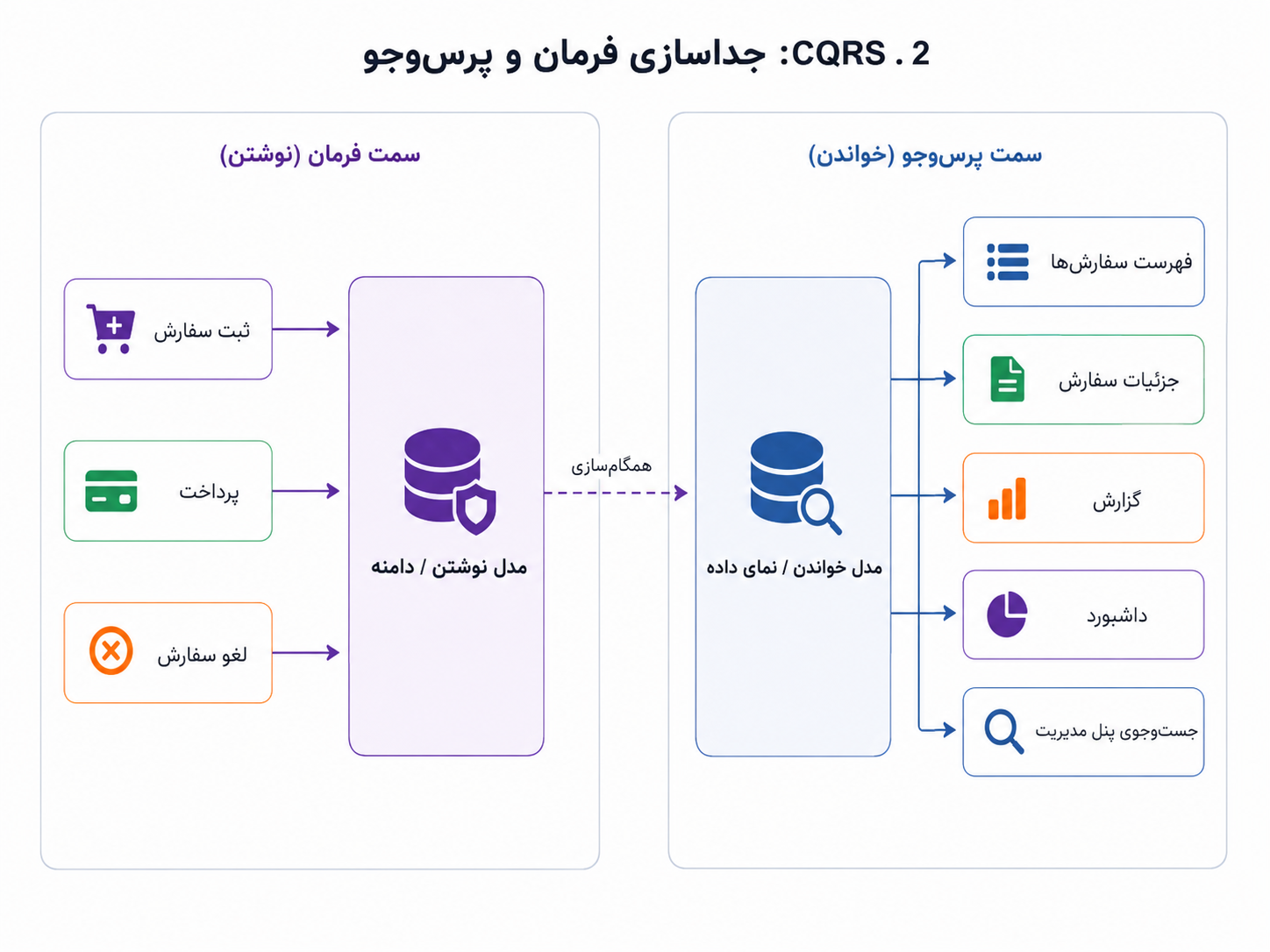
در این مدل، سمت فرمان مسئول تغییر وضعیت و رعایت قواعد دامنه است؛ سمت پرسوجو مسئول ساختن نماهای مناسب برای خواندن، گزارش و جستوجو.
نسبت CQRS با DDD و معماری ششضلعی هم باید روشن باشد. DDD کمک میکند بفهمیم منطق دامنه چیست. معماری ششضلعی کمک میکند این منطق را از ابزارهای بیرونی جدا نگه داریم. CQRS زمانی مطرح میشود که فشار خواندن و نوشتن از هم فاصله میگیرد. پس مسئلهی CQRS این نیست که «دامنه کجا باشد»، بلکه این است که «آیا مدل و مسیر خواندن باید همان مدل و مسیر نوشتن باشد؟»
DDD بیشتر دربارهی فهم و مدلکردن زبان کسبوکار است. معماری ششضلعی دربارهی محافظت از هستهی دامنه در برابر ابزارهاست. CQRS دربارهی تفاوت نیازهای خواندن و نوشتن است. این سه میتوانند کنار هم بیایند، اما هرکدام به درد متفاوتی پاسخ میدهند.
این جداسازی میتواند چند فایده داشته باشد. مدل نوشتن میتواند تمیزتر و نزدیکتر به قواعد دامنه بماند، چون مجبور نیست همهی نیازهای گزارشگیری و نمایش را هم در خود جا بدهد. مدل خواندن هم میتواند برای سرعت و شکل مناسب داده ساخته شود، بدون اینکه منطق اصلی سفارش و پرداخت را آلوده کند. برای مثال، ممکن است سمت نوشتن با مفهوم سفارش و وضعیتهایش کار کند، اما سمت خواندن یک نمای آماده داشته باشد که دقیقاً برای فهرست موبایل یا داشبورد مدیریتی طراحی شده است.
| وضعیت | مدل واحد احتمالاً کافی است؟ | CQRS چه زمانی ارزشمند میشود؟ |
|---|---|---|
| خواندن و نوشتن ساده و کمترافیکاند | بله | معمولاً نیازی نیست. |
| گزارشها و جستوجوها زیاد و پیچیده شدهاند | شاید نه | وقتی کوئریها مدل نوشتن را سنگین و آشفته میکنند. |
| مدل نوشتن پر از فیلدها و نیازهای نمایشی شده است | نه همیشه | وقتی نیازهای خواندن دارند منطق دامنه را آلوده میکنند. |
| خواندن باید بسیار سریع و متناسب با نماهای مختلف باشد | نه همیشه | وقتی نمای خواندن جدا میتواند فشار را کم کند. |
| دادهی خواندن ممکن است کمی با تأخیر بهروز شود | بستگی دارد | وقتی تأخیر کوتاه پذیرفتنی است، جداسازی آسانتر میشود. |
CQRS یعنی حتماً معماری بزرگ، دو پایگاه داده، Event Sourcing و کلی زیرساخت تازه؟ نه. CQRS از یک ایدهی ساده شروع میشود: فرمان و پرسوجو نیازهای متفاوتی دارند. اینکه این جداسازی فقط در کد باشد یا تا سطح پایگاه داده و پیامرسان جلو برود، به اندازه و درد واقعی سیستم بستگی دارد.
یک نشانه که میگوید شاید CQRS زود است
اگر هنوز گزارشها سادهاند، ترافیک خواندن و نوشتن پایین است، و همان مدل داده بدون فشار جدی هم برای تغییر وضعیت و هم برای نمایش کافی است، آوردن CQRS احتمالاً زود است. در این مرحله، جداسازی بیش از حد میتواند فهم سیستم را سختتر کند و هزینهی نگهداری را بالا ببرد.
یک نشانه که میگوید شاید وقت فکر کردن به CQRS رسیده است
اگر هر نیاز نمایشی تازه باعث تغییر در مدل نوشتن میشود، گزارشها کوئریهای سنگین و شکننده میسازند، پنل مدیریت و داشبوردها مدام شکل متفاوتی از داده میخواهند، و منطق دامنه کمکم با نیازهای خواندن قاطی شده است، احتمالاً باید دستکم به جداسازی مسیر فرمان و پرسوجو فکر کنیم.
برای من، CQRS یک یادآوری مهم است: همهی نیازهای سیستم از یک جنس نیستند. ثبت سفارش و لغو سفارش باید دقیق، قانونمند و محافظهکار باشد. فهرست سفارشها و گزارش مدیریتی باید سریع، قابل جستوجو و مناسب نمایش باشد. اگر این دو نیاز هنوز سادهاند، یک مدل واحد کافی است. اما وقتی از هم فاصله گرفتند، جدا دیدن آنها میتواند سیستم را قابل فهمتر و قابل تغییرتر کند.
این جداسازی آرامآرام ما را به یک سؤال بعدی میرساند: اگر تغییرهای مهم سیستم را فقط بهصورت وضعیت نهایی ذخیره نکنیم و خود رخدادهای مهم را هم نگه داریم چه میشود؟ اینجا وارد بحث Event Sourcing میشویم.
وقتی سیستم باید خبر بدهد، نه اینکه همه را مستقیم صدا بزند
تا اینجا چند بار با یک الگوی تکرارشونده روبهرو شدیم: هرچه محصول رشد میکند، یک تصمیم سادهی دیروز کمکم زیر فشار نیازهای تازه قرار میگیرد. در CQRS گفتیم خواندن و نوشتن ممکن است نیازهای متفاوتی پیدا کنند. حالا میخواهیم از زاویهی دیگری به رشد سیستم نگاه کنیم: وقتی یک اتفاق در سیستم میافتد، چند بخش دیگر باید از آن باخبر شوند؟
فرض کنیم کاربر سفارشی ثبت میکند و پرداخت هم موفق میشود. در نگاه ساده، شاید بگوییم سفارش ثبت شد و تمام. اما در محصول واقعی، این اتفاق فقط برای سرویس سفارش مهم نیست. موجودی باید کم شود، برای کاربر اعلان فرستاده شود، داشبورد فروش باید بهروز شود، گزارش مالی بعداً باید آن را حساب کند، و شاید سیستم امتیازدهی هم بخواهد به رفتار کاربر واکنش نشان دهد.
اگر سرویس سفارش بخواهد همهی این کارها را خودش و بهصورت مستقیم انجام دهد، خیلی زود گرفتار زنجیرهای از وابستگیها میشود. باید سرویس اعلان را بشناسد، سرویس موجودی را صدا بزند، گزارش مالی را خبر کند، داشبورد را بهروز کند و با سیستم امتیازدهی هم هماهنگ شود. حالا اگر یکی از این بخشها کند یا خراب شود، مسیر اصلی ثبت سفارش هم ممکن است آسیب ببیند.
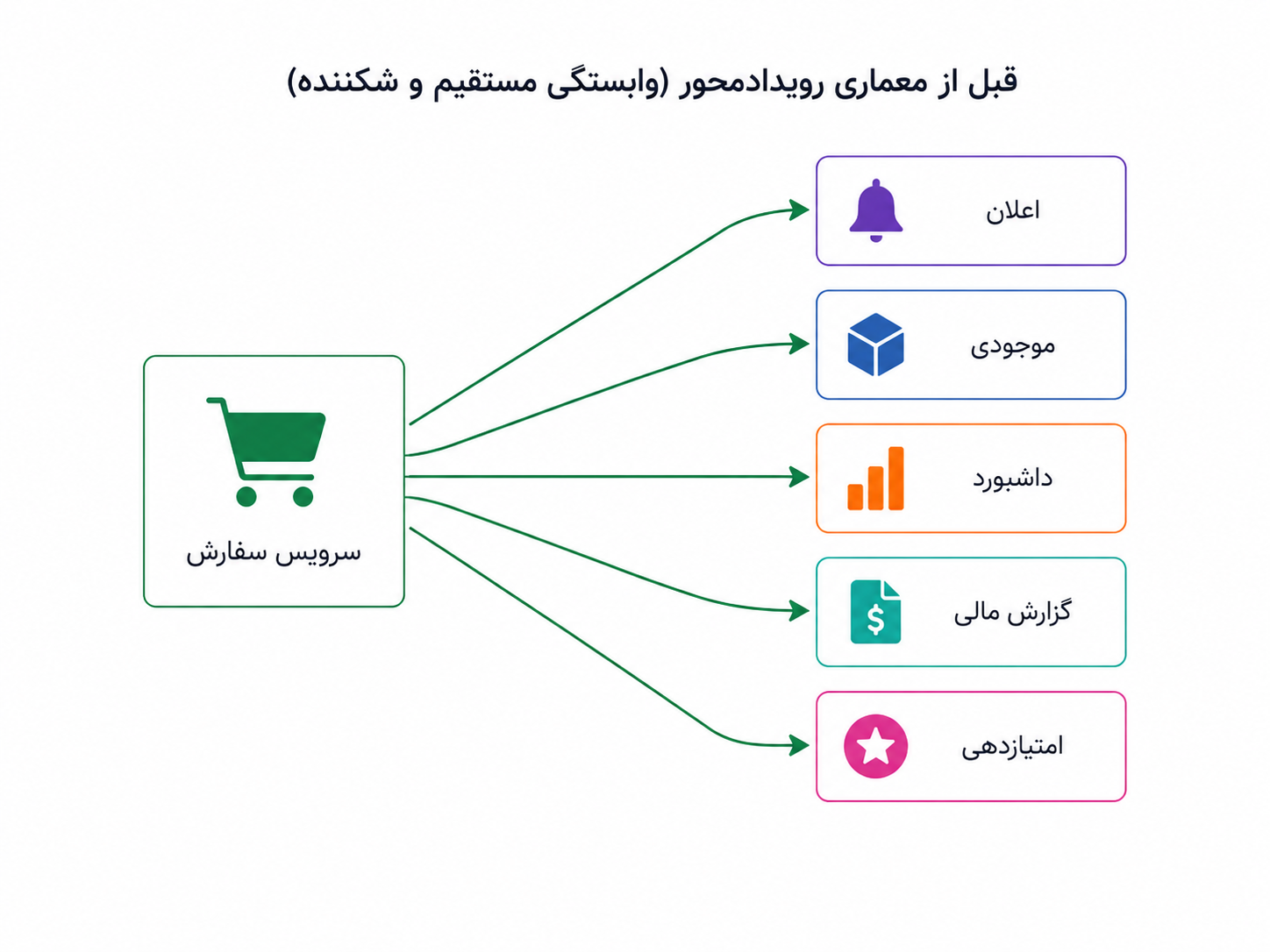
وقتی یک سرویس مجبور است همهی واکنشهای بعد از یک اتفاق را خودش مدیریت کند، وابستگیها زیاد و شکننده میشوند.
معماری رویدادمحور یا Event-Driven Architecture از همینجا معنا پیدا میکند. ایدهاش این است که بهجای اینکه سرویس سفارش همه را مستقیم صدا بزند، فقط یک خبر رسمی منتشر کند: «سفارش ثبت شد». بعد هر بخشی که به این اتفاق علاقه دارد، واکنش خودش را انجام میدهد. سرویس اعلان پیام میفرستد، سرویس موجودی مقدار کالا را کم میکند، داشبورد دادهی خودش را بهروز میکند و گزارش مالی هم مسیر خودش را میرود.
در معماری رویدادمحور، یک بخش لازم نیست همهی واکنشهای بعد از یک اتفاق را مستقیم مدیریت کند. کافی است رخداد مهم را منتشر کند و بخشهای علاقهمند، مستقلتر به آن واکنش نشان دهند.
رویداد با دستور مستقیم فرق دارد. وقتی میگوییم «سفارش ثبت شد»، داریم دربارهی چیزی خبر میدهیم که قبلاً رخ داده است. اما وقتی میگوییم «به کاربر پیامک بفرست»، داریم به یک بخش دیگر دستور میدهیم کاری انجام دهد. این تفاوت کوچک، در طراحی سیستم مهم است. رخداد، سرویس منتشرکننده را از دانستن جزئیات واکنشهای بعدی آزادتر میکند.
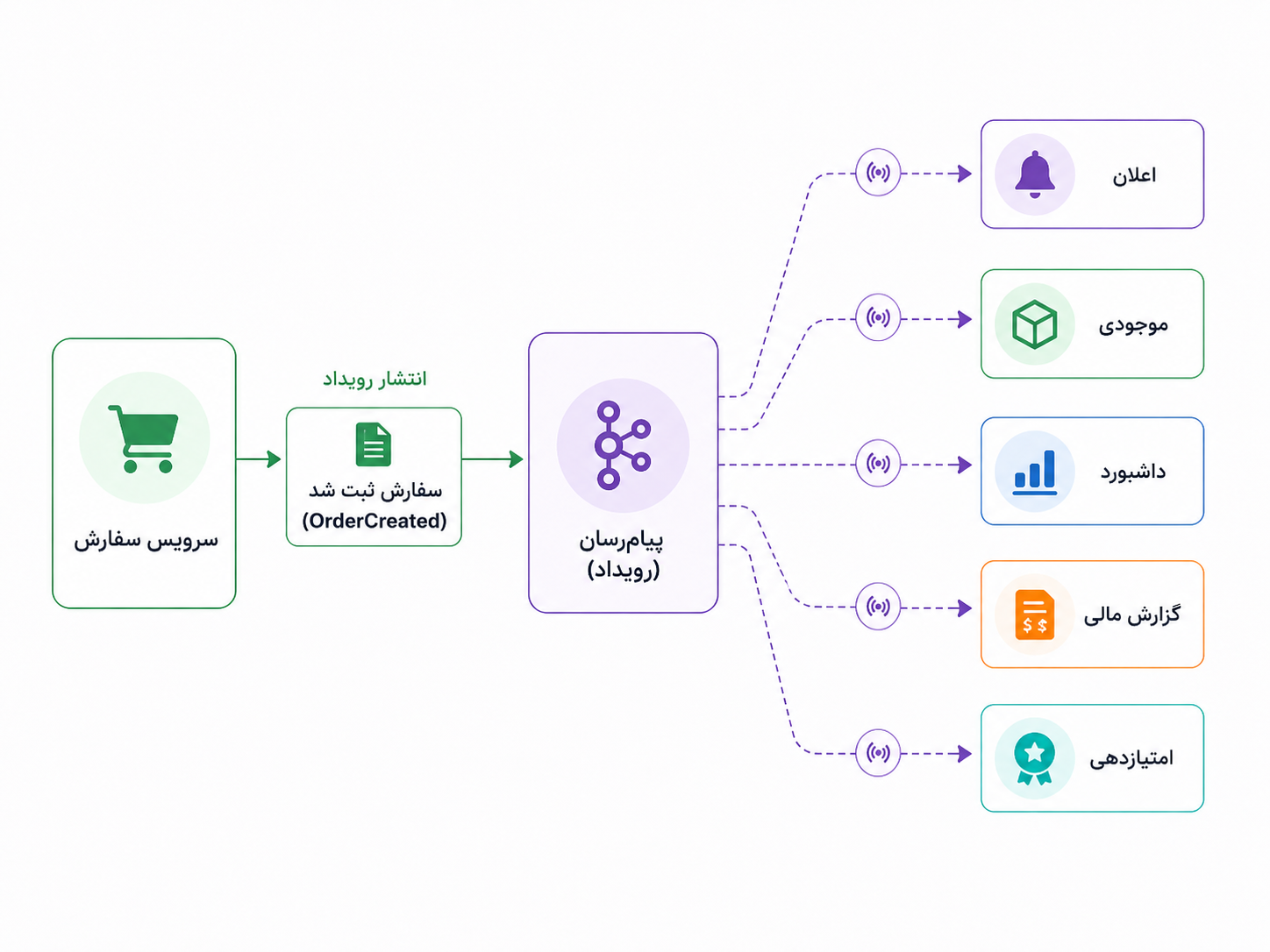
سرویس سفارش لازم نیست همهی مصرفکنندهها را بشناسد؛ فقط خبر رسمی اتفاق را منتشر میکند.
برای رساندن این رخدادها معمولاً یک پیامرسان یا واسط ارتباطی در میان قرار میگیرد؛ چیزی که پیام را از تولیدکننده میگیرد و به مصرفکنندهها میرساند. در این بخش لازم نیست وارد جزئیات ابزارهایی مثل Kafka یا RabbitMQ شویم؛ فعلاً همین قدر کافی است که بدانیم پیامرسان کمک میکند تولیدکنندهی رخداد و مصرفکنندههای آن کمتر به هم قفل شوند. جزئیات صف پیام، الگوهای مصرف، تکرار پیام و تفاوت ابزارها را جداگانه در بخش Message Queue باز میکنیم.
نکتهی مهم این است که معماری رویدادمحور فقط مزیت نیست؛ پیچیدگی تازه هم میآورد. در مدل مستقیم، مسیر اجرا معمولاً واضحتر است: این سرویس آن سرویس را صدا زد و پاسخ گرفت. اما در مدل رویدادمحور، یک رخداد منتشر میشود و چند مصرفکننده بعداً واکنش نشان میدهند. ممکن است پیام دیر برسد، دوباره برسد، مصرفکنندهای موقتاً از کار بیفتد، یا فهمیدن مسیر کامل یک اتفاق سختتر شود. پس آزادی بیشتر، با مسئولیت عملیاتی بیشتر همراه است.
رویدادمحور کردن سیستم یعنی هر تغییر کوچک را تبدیل به رخداد کنیم و همهچیز را از مسیر پیامها بگذرانیم؟ نه. اگر سیستم کوچک است و واکنشها ساده و کماند، فراخوانی مستقیم میتواند خواناتر و کمهزینهتر باشد. معماری رویدادمحور وقتی ارزشمند میشود که یک اتفاق برای چند بخش مهم باشد و نخواهیم همهی آن بخشها مستقیم و همزمان به هم گره بخورند.
اینجا بد نیست خیلی کوتاه مرز CDC را هم روشن کنیم. گرفتن تغییرات داده یا Change Data Capture، که معمولاً CDC گفته میشود، یعنی تغییرهای پایگاه داده را دنبال کنیم و آنها را به جریان پیام یا رخداد تبدیل کنیم. مثلاً وقتی ردیفی در جدول سفارشها اضافه میشود یا وضعیت سفارشی تغییر میکند، CDC میتواند این تغییر را بخواند و برای بخشهای دیگر منتشر کند.
در معماری رویدادمحور، رخداد میتواند آگاهانه از دل منطق دامنه منتشر شود؛ مثلاً سرویس سفارش بعد از ثبت موفق سفارش، رخداد «سفارش ثبت شد» را منتشر کند. CDC اما معمولاً از تغییرهای پایگاه داده خبر میسازد. پس CDC میتواند راهی عملی برای وصل کردن سیستمهای قدیمی یا دادهمحور به جریان پیامها باشد، اما همان Event Sourcing نیست.
برای اینکه مرز این مفهومها با بخشهای قبلی و بعدی روشن بماند، میشود اینطور نگاه کرد:
| مفهوم | پرسش اصلی | چیزی که در این بخش نباید با آن قاطی شود |
|---|---|---|
| CQRS | آیا خواندن و نوشتن نیازهای متفاوتی دارند؟ | قرار نیست هر جداسازی خواندن و نوشتن حتماً رویدادمحور باشد. |
| معماری رویدادمحور | وقتی اتفاقی افتاد، چه بخشهایی باید باخبر شوند؟ | قرار نیست رخدادها الزاماً منبع اصلی حقیقت باشند. |
| CDC | اگر تغییر در پایگاه داده رخ داد، چطور دیگران باخبر شوند؟ | CDC با رخداد دامنه و Event Sourcing یکی نیست. |
| Event Sourcing | اگر خود رخدادها منبع اصلی حقیقت باشند چه؟ | این پرسش را در بخش بعدی باز میکنیم. |
یک نشانه که میگوید شاید معماری رویدادمحور کمک کند
اگر بعد از یک اتفاق مهم، چند بخش مستقل باید واکنش نشان دهند و اضافهکردن هر واکنش تازه باعث تغییر در سرویس اصلی میشود، احتمالاً وابستگیها زیادی مستقیم شدهاند. در این نقطه، انتشار رخداد میتواند کمک کند سرویس اصلی فقط خبر اتفاق را بدهد و واکنشهای بعدی در بخشهای جدا انجام شوند.
یک نشانه که میگوید شاید هنوز زود است
اگر فقط دو بخش ساده با هم حرف میزنند، مسیر اجرا باید کاملاً همزمان و قابل پیشبینی باشد، و پیچیدگی عملیاتی پیامرسان برای تیم سنگین است، رویدادمحوری کامل ممکن است بیشتر از آنکه کمک کند، فهم و عیبیابی سیستم را سخت کند.
برای من، معماری رویدادمحور یعنی پذیرفتن اینکه بعضی اتفاقها فقط متعلق به یک بخش نیستند. سفارش ثبت میشود، اما اعلان، موجودی، داشبورد و گزارش هم از آن تأثیر میگیرند. بهجای اینکه سرویس سفارش همه را مستقیم بشناسد، میتواند خبر رسمی اتفاق را منتشر کند و بقیهی بخشها مستقلتر واکنش نشان دهند.
تا اینجا رخدادها را مثل خبرهایی دیدیم که بین بخشهای سیستم جابهجا میشوند. اما اگر این رخدادها فقط پیام گذرا نباشند و خودشان منبع اصلی حقیقت سیستم شوند چه؟ این پرسش ما را به Event Sourcing میرساند.
وقتی پیامها باید امن و قابلاعتماد جابهجا شوند
در بخش قبل گفتیم معماری رویدادمحور کمک میکند سرویسها بهجای صدا زدن مستقیم یکدیگر، خبر اتفاقهای مهم را منتشر کنند. سرویس سفارش لازم نیست خودش اعلان بفرستد، موجودی کم کند، داشبورد را بهروز کند و گزارش مالی بسازد. میتواند بگوید «سفارش ثبت شد» و بخشهای علاقهمند، هرکدام واکنش خودشان را انجام دهند.
اما این حرف یک پرسش عملی مهم را باز میگذارد: این پیامها قرار است از کجا عبور کنند؟ اگر سرویس اعلان لحظهای از کار افتاده باشد چه؟ اگر سرویس گزارش مالی کندتر از بقیه پردازش کند چه؟ اگر پیام به مصرفکننده رسید اما پردازش آن شکست خورد چه؟ اینجاست که صف پیام یا Message Queue وارد داستان میشود.
صف پیام را میتوان مثل یک فضای میانی میان تولیدکننده و مصرفکننده دید. تولیدکننده پیام را در صف میگذارد و لازم نیست منتظر بماند همهی مصرفکنندهها همان لحظه کارشان را انجام دهند. مصرفکنندهها هم با سرعت و توان خودشان پیامها را میخوانند و پردازش میکنند. این فاصلهی کوچک، در سیستمهای بزرگ ارزش زیادی دارد؛ چون دو طرف را از وضعیت لحظهای هم آزادتر میکند.
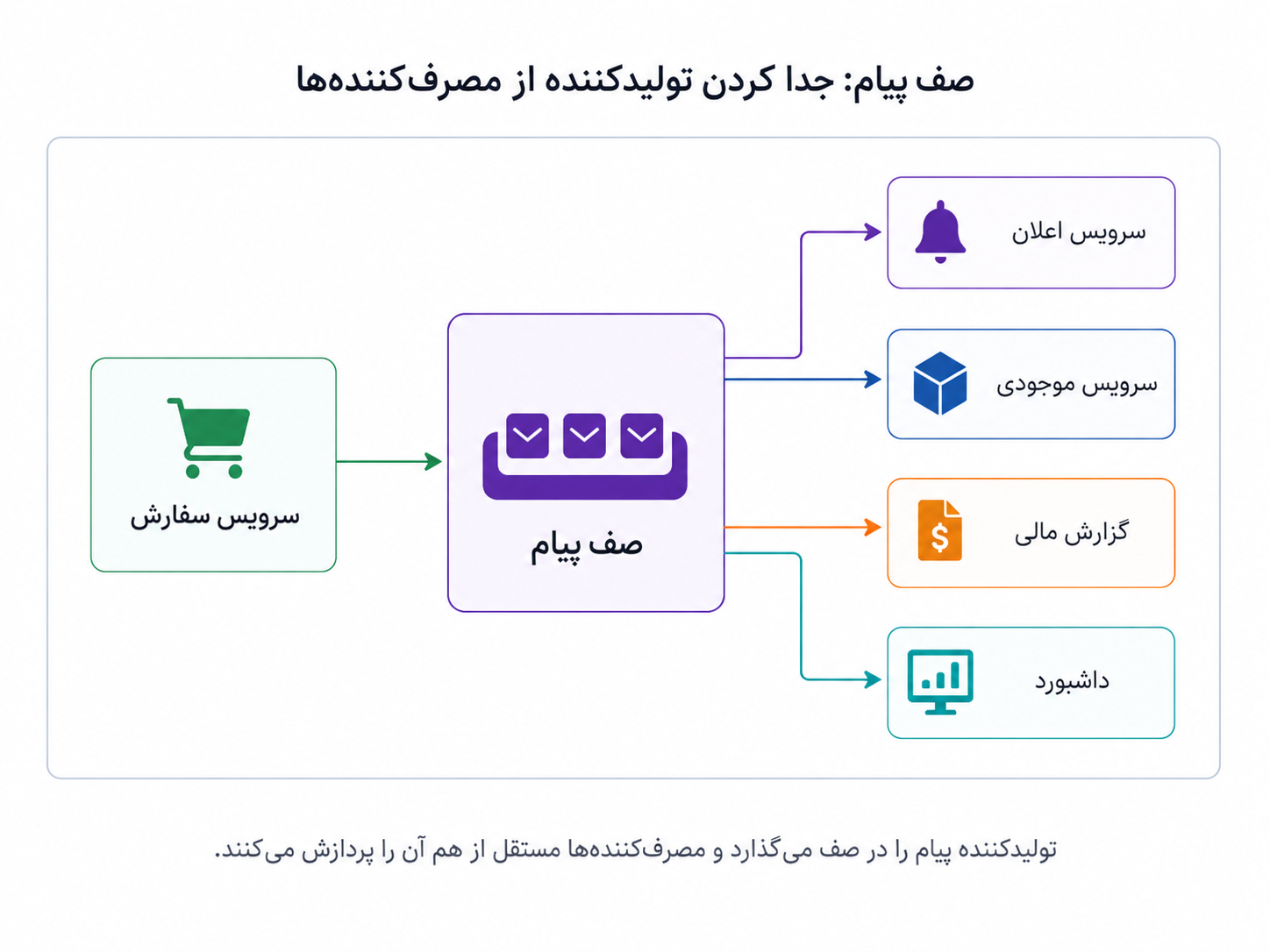
تولیدکننده پیام را در صف میگذارد و مصرفکنندهها مستقل از هم آن را پردازش میکنند.
صف پیام کمک میکند تولیدکننده و مصرفکننده کمتر به زمان، سرعت و وضعیت لحظهای هم وابسته باشند. تولیدکننده پیام را تحویل میدهد؛ مصرفکنندهها بعداً آن را میخوانند، پردازش میکنند و نتیجهی کار خودشان را جلو میبرند.
در سادهترین شکل، چند نقش اصلی داریم. تولیدکننده یا Producer بخشی است که پیام را میفرستد؛ مثلاً سرویس سفارش. مصرفکننده یا Consumer بخشی است که پیام را میخواند و کاری انجام میدهد؛ مثلاً سرویس اعلان یا گزارش مالی. خود صف یا موضوع، جایی است که پیامها در آن قرار میگیرند. بعضی ابزارها بیشتر با واژهی صف شناخته میشوند، بعضی با مفهوم جریان یا موضوع، اما ایدهی پایه یکی است: پیامها باید جایی قرار بگیرند تا بین بخشهای سیستم جابهجا شوند.
اینجا تفاوت Message Queue با معماری رویدادمحور هم مهم است. معماری رویدادمحور میگوید بخشهای سیستم میتوانند با خبر دادن دربارهی اتفاقها با هم هماهنگ شوند. صف پیام بیشتر دربارهی زیرساخت رساندن آن خبرهاست. یعنی EDA بیشتر سبک طراحی ارتباط است، اما Message Queue ابزار و سازوکاری است برای اینکه این ارتباط عملیتر، قابل تحملتر و قابل بازیابیتر شود.
در بخش Event-Driven Architecture پرسیدیم «وقتی اتفاقی افتاد، چه بخشهایی باید باخبر شوند؟» در این بخش میپرسیم «این خبر چطور قابل اعتماد جابهجا شود، اگر مصرفکننده کند بود یا پردازش شکست خورد چه کنیم؟»
یکی از نکتههای مهم در صف پیام، تأیید پردازش است. مصرفکننده معمولاً بعد از اینکه پیام را گرفت و کارش را انجام داد، به صف اعلام میکند که پیام با موفقیت پردازش شده است. اگر پردازش شکست بخورد، سیستم میتواند پیام را دوباره برای تلاش بعدی نگه دارد یا بعد از چند بار شکست، آن را به جای جداگانهای بفرستد تا بعداً بررسی شود. به این جای جداگانه معمولاً صف پیامهای مشکلدار یا Dead Letter Queue گفته میشود.
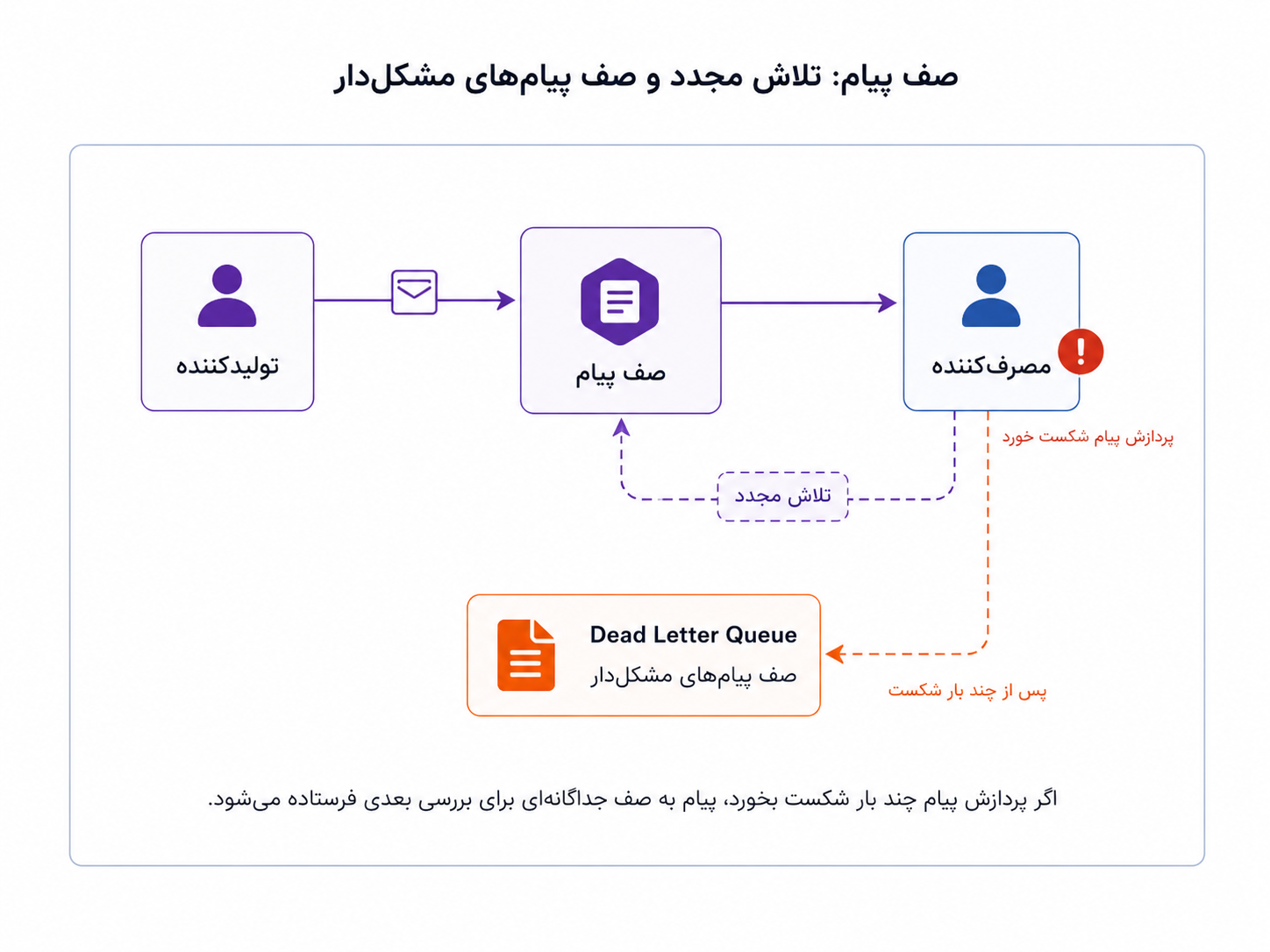
همهی خطاها نباید مسیر اصلی را متوقف کنند؛ بعضی پیامها میتوانند دوباره پردازش شوند یا برای بررسی جدا شوند.
اما صف پیام هم جادو نمیکند. وقتی پیامها غیرهمزمان جابهجا میشوند، باید با چند واقعیت کنار بیاییم. ممکن است یک پیام بیش از یک بار به مصرفکننده برسد، پس مصرفکننده باید تا حد ممکن در برابر پردازش تکراری مقاوم باشد. ممکن است ترتیب پیامها مهم باشد، پس باید بدانیم ابزار و طراحی ما چه تضمینی دربارهی ترتیب میدهد. ممکن است مصرفکننده عقب بماند و صف بزرگ شود. ممکن است پیامها در یک بخش پردازش شوند و در بخش دیگر هنوز نه، و این یعنی سیستم برای مدتی در وضعیت کاملاً همزمان و یکدست نیست.
| مسئله | پرسشی که باید از خودمان بپرسیم |
|---|---|
| پیام تکراری | اگر همین پیام دوبار برسد، آیا نتیجه خراب میشود؟ |
| ترتیب پیامها | آیا ترتیب رخدادها برای این مصرفکننده مهم است؟ |
| شکست پردازش | بعد از شکست، پیام باید دوباره امتحان شود یا کنار گذاشته شود؟ |
| عقبماندن مصرفکننده | اگر مصرفکننده کند شد، صف چقدر میتواند رشد کند؟ |
| مشاهدهپذیری | از کجا بفهمیم پیام کجا گیر کرده یا چند بار شکست خورده است؟ |
در این فضا نام ابزارهایی مثل RabbitMQ و Kafka زیاد شنیده میشود. برای فهم اولیه، میشود خیلی ساده گفت RabbitMQ بیشتر با الگوی صف، تحویل پیام و پردازش کارها شناخته میشود. Kafka بیشتر شبیه یک جریان پایدار از پیامها و رخدادهاست که پیامها را برای مدتی نگه میدارد و مصرفکنندههای مختلف میتوانند از آن بخوانند. این توضیح کامل نیست، اما برای جایگاه ذهنی کافی است: هر دو برای جابهجایی پیام استفاده میشوند، اما نگاه و نقطهی قوتشان یکسان نیست.
صف پیام یعنی سیستم خودبهخود سادهتر و مطمئنتر میشود؟ نه. صف پیام وابستگی مستقیم را کمتر میکند و تحمل خطا را بهتر میکند، اما عیبیابی، پایش، ترتیب پیامها، پیامهای تکراری و وضعیتهای نیمهکاره را هم وارد داستان میکند.
چه زمانی هنوز به صف پیام نیاز نداریم؟
اگر دو بخش ساده با هم ارتباط مستقیم دارند، پاسخ همزمان لازم است، ترافیک پایین است و شکست یک بخش مسیر پیچیدهای ایجاد نمیکند، اضافه کردن صف پیام ممکن است زود باشد. در چنین مرحلهای، ارتباط مستقیم شاید خواناتر و کمهزینهتر باشد.
چه زمانی صف پیام ارزشمندتر میشود؟
اگر یک اتفاق باید چند مصرفکنندهی مستقل را خبر کند، مصرفکنندهها سرعتهای متفاوت دارند، بعضی کارها میتوانند با تأخیر انجام شوند، یا نمیخواهیم خطای یک مصرفکننده مسیر اصلی را خراب کند، صف پیام میتواند کمک کند. البته به شرطی که برای پایش، تلاش مجدد و پیامهای مشکلدار هم فکر کرده باشیم.
برای من، صف پیام یعنی پذیرفتن اینکه همهی بخشهای سیستم لازم نیست همزمان و مستقیم به هم قفل باشند. بعضی کارها میتوانند کمی دیرتر، مستقلتر و با امکان تلاش دوباره انجام شوند. این استقلال ارزشمند است، اما فقط وقتی که هزینههای عملیاتی آن را هم بپذیریم.
تا اینجا فقط دربارهی مسیر جابهجایی پیامها حرف زدیم: پیام از کجا عبور کند، اگر مصرفکننده کند بود چه شود، اگر پردازش شکست خورد چطور دوباره تلاش کنیم، و پیامهای مشکلدار را کجا نگه داریم. بخش بعدی یک پرسش جداست: گاهی خود رخدادها فقط پیام عبوری نیستند و برای فهم تاریخچهی سیستم اهمیت پیدا میکنند. آنجا وارد Event Sourcing میشویم.
وقتی فقط وضعیت فعلی کافی نیست
در بخشهای قبل، رخدادها را از دو زاویه دیدیم. در معماری رویدادمحور، رخداد راهی بود برای خبر دادن به بخشهای دیگر سیستم. در صف پیام، دربارهی این حرف زدیم که پیامها و رخدادها چطور میان تولیدکننده و مصرفکننده جابهجا شوند. اما Event Sourcing پرسش دیگری دارد: اگر خود رخدادها فقط پیام عبوری نباشند و تاریخچهی رسمی سیستم را بسازند چه؟
فرض کنیم کاربری به پشتیبانی پیام میدهد و میگوید: «من سفارشم را لغو کردم، ولی چرا فقط بخشی از پولم برگشته؟» پشتیبانی وارد پنل میشود و فقط یک چیز میبیند: وضعیت سفارش «لغوشده» است. این اطلاعات بد نیست، اما کافی هم نیست. برای فهمیدن ماجرا باید بدانیم سفارش چه زمانی ثبت شد، پرداخت چه زمانی انجام شد، لغو قبل از ارسال بود یا بعد از آن، لغو را خود کاربر انجام داد یا پشتیبانی، قانون بازپرداخت در آن لحظه چه بوده، و آیا بازپرداخت کامل شده یا فقط آغاز شده است.
اینجا مشکل روشن میشود: وضعیت فعلی فقط آخر داستان را نشان میدهد، نه مسیر رسیدن به آن را.
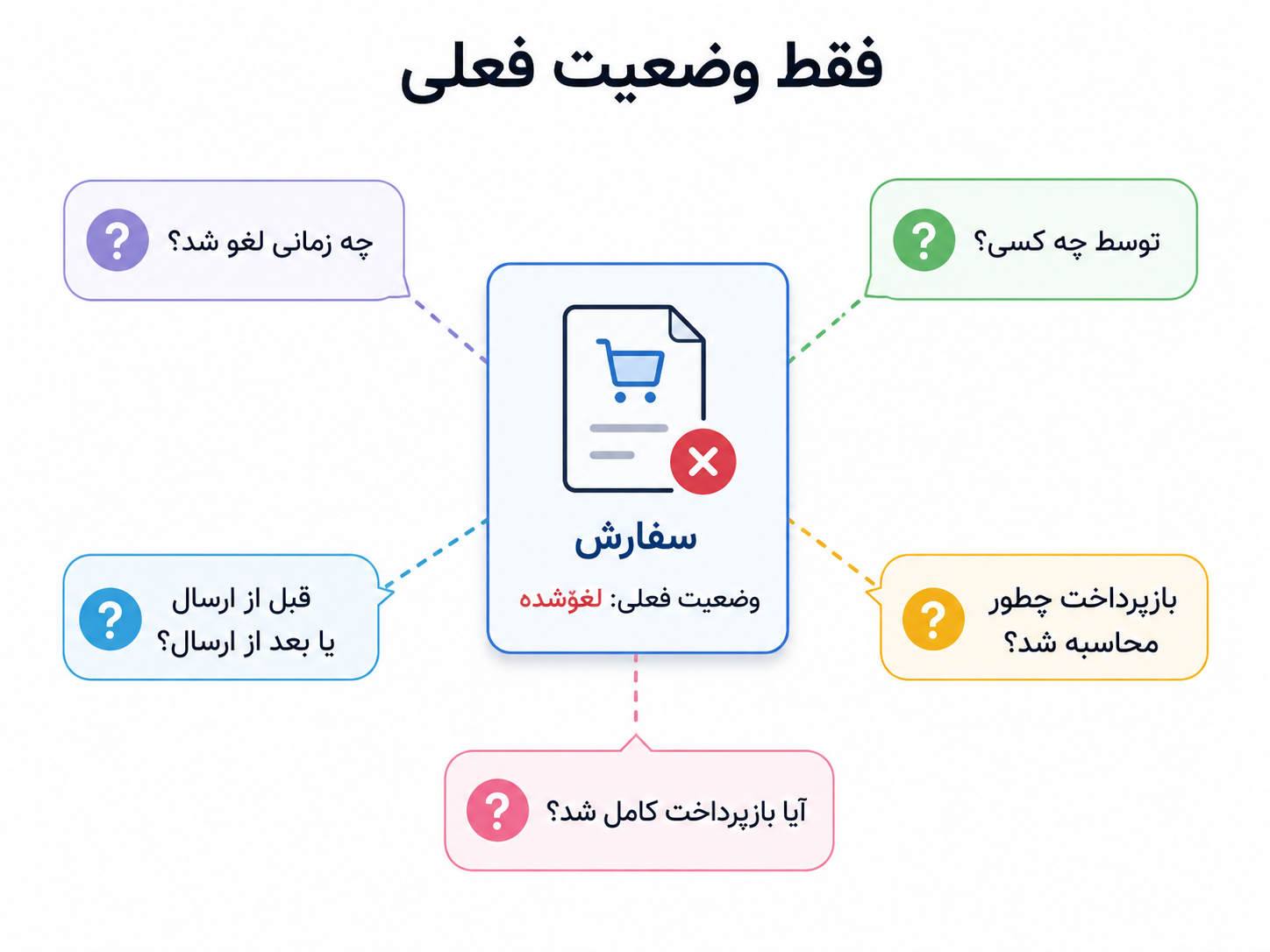
اگر فقط بدانیم سفارش «لغوشده» است، هنوز نمیدانیم چه اتفاقهایی باعث رسیدن سفارش به این وضعیت شدهاند.
در مدل معمول، بیشتر با وضعیت فعلی کار میکنیم. مثلاً در جدول سفارش، یک فیلد داریم که میگوید سفارش الان پرداختشده، ارسالشده یا لغوشده است. اما در Event Sourcing، منبع اصلی حقیقت فقط وضعیت نهایی نیست؛ رخدادهایی است که در طول زمان اتفاق افتادهاند. یعنی به جای اینکه فقط بگوییم سفارش الان چه وضعیتی دارد، تاریخچهی اتفاقها را نگه میداریم.
برای یک سفارش، این رخدادها میتوانند چنین چیزهایی باشند: سفارش ثبت شد، پرداخت انجام شد، ارسال آغاز شد، سفارش لغو شد، بازپرداخت صادر شد. بعد وضعیت فعلی سفارش از روی همین رخدادها ساخته میشود. در این نگاه، وضعیت فعلی نتیجهی تاریخچه است؛ نه جایگزین تاریخچه.
در Event Sourcing، رخدادها منبع اصلی حقیقتاند. یعنی سیستم میتواند وضعیت فعلی را با خواندن و اعمال کردن رخدادهای گذشته بازسازی کند.
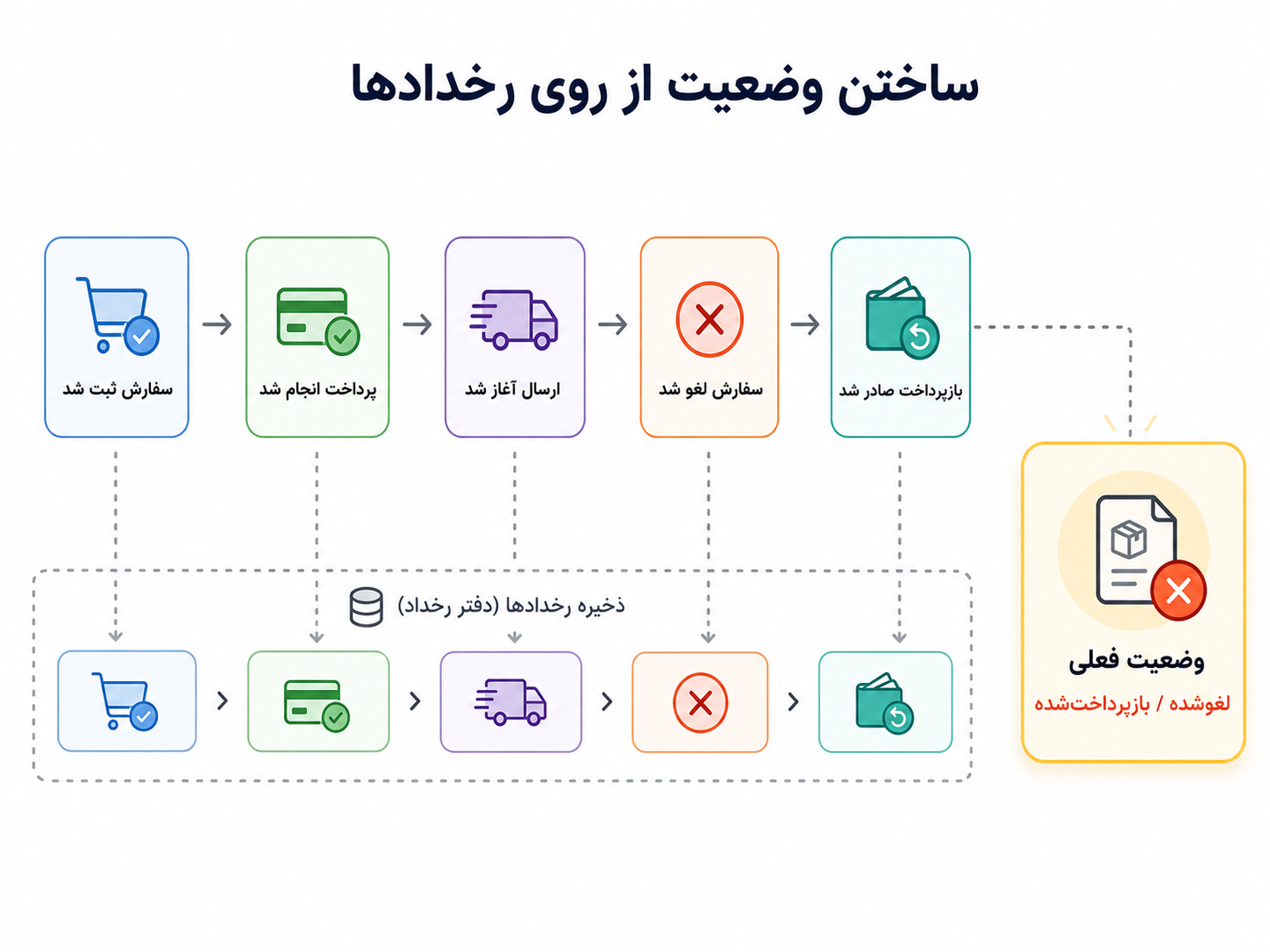
رخدادها فقط خبرهای پراکنده نیستند؛ تاریخچهای هستند که وضعیت فعلی از روی آنها ساخته میشود.
مرز این مفهوم با فصلهای قبلی مهم است. در معماری رویدادمحور، شاید رخداد را برای خبر دادن به سرویسهای دیگر منتشر کنیم. در صف پیام، دربارهی رساندن و پردازش همین پیامها حرف زدیم. اما در Event Sourcing، رخدادها نقش عمیقتری دارند: آنها حافظهی رسمی سیستماند. حتی اگر هیچ سرویس دیگری رخدادها را مصرف نکند، خود سیستم میتواند برای بازسازی وضعیت، حسابرسی یا تحلیل خطا به آنها تکیه کند.
رخدادمحوری میپرسد «چه بخشهایی باید از یک اتفاق باخبر شوند؟» صف پیام میپرسد «این خبر چطور قابل اعتماد جابهجا شود؟» Event Sourcing میپرسد «آیا خود رخدادها منبع حقیقت و تاریخچهی رسمی سیستم هستند؟»
Event Sourcing را نباید با لاگ معمولی هم یکی گرفت. لاگ عملیاتی معمولاً برای مشاهده، عیبیابی و فهم رفتار سیستم نوشته میشود. اما رخداد در Event Sourcing بخشی از مدل اصلی سیستم است. اگر رخدادهای سفارش را از دست بدهیم، فقط چند خط گزارش را از دست ندادهایم؛ بخشی از حقیقت سیستم را از دست دادهایم.
همچنین Event Sourcing الزاماً همان CQRS نیست. ممکن است سیستمی CQRS داشته باشد، اما رخدادها را منبع حقیقت نداند. ممکن است Event Sourcing داشته باشیم و بعد برای خواندن سریعتر، مدلهای خواندن جدا بسازیم؛ در این حالت این دو کنار هم میآیند. اما یکی تعریف دیگری نیست. CQRS دربارهی جداسازی خواندن و نوشتن است؛ Event Sourcing دربارهی این است که وضعیت از روی رخدادهای ذخیرهشده ساخته شود.
| مفهوم | پرسش اصلی | اشتباه رایج |
|---|---|---|
| CQRS | آیا خواندن و نوشتن نیازهای متفاوتی دارند؟ | فکر کنیم هر CQRS یعنی Event Sourcing. |
| معماری رویدادمحور | چه بخشهایی باید از اتفاقها باخبر شوند؟ | فکر کنیم هر رخداد منتشرشده منبع حقیقت است. |
| صف پیام | پیامها چطور قابل اعتماد جابهجا شوند؟ | فکر کنیم وجود Kafka یا RabbitMQ یعنی Event Sourcing داریم. |
| Event Sourcing | آیا رخدادها تاریخچهی رسمی و منبع حقیقت سیستماند؟ | فکر کنیم Event Sourcing فقط یک لاگ مفصلتر است. |
این سبک چند مزیت جدی دارد. برای حسابرسی و پشتیبانی، تاریخچهی دقیقتری از اتفاقها داریم. اگر لازم باشد بفهمیم چرا یک سفارش به وضعیت فعلی رسیده، میتوانیم مسیر رخدادها را دنبال کنیم. اگر باگی در محاسبهی وضعیت پیدا شود، گاهی میتوان با منطق اصلاحشده، وضعیت را از روی رخدادهای گذشته دوباره ساخت. همچنین میتوان از همان تاریخچه برای ساختن نماهای خواندن، گزارشها یا تحلیلهای تازه استفاده کرد.
اما این مزایا ارزان به دست نمیآیند. ترتیب رخدادها مهم میشود. نسخهبندی رخدادها دردسر دارد؛ چون رخدادهای قدیمی ممکن است با شکل جدید کد یکی نباشند. بازسازی وضعیت باید دقیق و قابل اعتماد باشد. حذف یا اصلاح دادهها ساده نیست، چون تاریخچه بخشی از حقیقت سیستم است. خواندن داده هم گاهی مستقیم و ساده مثل خواندن یک ردیف از جدول نیست و به مدلهای خواندن جدا نیاز پیدا میکند.
Event Sourcing را نباید فقط برای خاصتر کردن معماری وارد سیستم کنیم. اگر مسئلهی ما CRUD ساده است، تاریخچهی دقیق برای تصمیمهای کسبوکار مهم نیست، و نگهداری رخدادها ارزش روشن ندارد، این الگو میتواند بیش از آنکه کمک کند، مدل ذهنی و پیادهسازی را سنگین کند.
چه زمانی Event Sourcing میتواند ارزشمند باشد؟
وقتی تاریخچهی دقیق برای حسابرسی، پشتیبانی، بازسازی وضعیت، تحلیل خطا یا فهم تصمیمهای کسبوکار مهم است، Event Sourcing میتواند گزینهی جدیتری باشد. مثلاً در سیستمهایی که مسیر رسیدن به یک وضعیت به اندازهی خود وضعیت اهمیت دارد، نگه داشتن رخدادها ارزش واقعی پیدا میکند.
چه زمانی احتمالاً زیادهروی است؟
اگر فقط چند موجودیت ساده داریم، بیشتر عملیاتها CRUD معمولیاند، تاریخچهی دقیق ارزش کسبوکاری ندارد، و تیم هنوز درگیر سادهسازی نیازهای پایه است، Event Sourcing احتمالاً زود است. در چنین مرحلهای، یک مدل وضعیت ساده همراه با ثبت تغییرات مهم ممکن است کافیتر و خواناتر باشد.
برای من، Event Sourcing یعنی به رسمیت شناختن این نکته که گاهی «چه اتفاقی افتاد» مهمتر از «الان در چه وضعیتی هستیم» است. وضعیت فعلی لازم است، اما همیشه کافی نیست. وقتی تاریخچه بخشی از حقیقت سیستم میشود، رخدادها دیگر فقط پیام نیستند؛ حافظهی رسمی سیستماند.
تا اینجا بیشتر دربارهی شکل ارتباط و مدلسازی رفتار سیستم حرف زدیم. از اینجا به بعد کمکم باید به سراغ زیرساخت و اجرای قابل تکرار برویم: اینکه محیطها، تنظیمات، سرویسها و منابع زیرساختی را چطور قابل بازسازی و قابل کنترل نگه داریم. این همان جایی است که Infrastructure as Code وارد داستان میشود.
وقتی «روی سیستم من کار میکند» دیگر کافی نیست
تقریباً هر تیم نرمافزاری، دیر یا زود، با این جمله روبهرو میشود: «روی سیستم من کار میکند.» برنامه روی لپتاپ توسعهدهنده اجرا میشود، آزمونها سبزند، همهچیز ظاهراً درست است؛ اما وقتی همان کد به محیط تست یا تولید میرود، خطا میدهد. چرا؟ شاید نسخهی Python فرق دارد، شاید یک کتابخانهی سیستمی نصب نیست، شاید متغیر محیطی جا افتاده، شاید مسیر فایلها فرق میکند، یا شاید نسخهی PostgreSQL و Redis با محیط توسعه یکی نیست.
اینجا یک نکتهی مهم روشن میشود: کد برنامه فقط خودش نیست. برنامه همراه با نسخهی زبان، وابستگیها، کتابخانههای سیستمی، تنظیمات، مسیرها، دستور اجرا و حتی فرضهای پنهانی دربارهی محیط اجرا معنی پیدا میکند. اگر این محیط در هرجا کمی فرق کند، همان کد میتواند رفتار متفاوتی داشته باشد.

مسئله همیشه خود کد نیست؛ گاهی محیط اجرا عوض شده و همان تغییر کوچک کافی است تا برنامه در محیط دیگر خراب شود.
این درد تازه نیست. پیش از فراگیر شدن کانتینرها، یکی از راهحلهای رایج این بود که محیط کاملتری را با ماشین مجازی یا VM بسازیم. ماشین مجازی کمک میکرد یک سیستمعامل کاملتر و جداگانهتر داشته باشیم، اما هزینهاش هم کم نبود: سنگینتر بود، بالا آمدنش زمان بیشتری میگرفت، و برای هر برنامه انگار یک رایانهی کوچک جداگانه روشن میکردیم.
کانتینرها از همینجا جذاب شدند. ایدهی جداسازی سبکتر فرایندها در لینوکس قدیمیتر از Docker بود، اما Docker حدود سال ۲۰۱۳ این تجربه را برای توسعهدهندهها بسیار سادهتر و فراگیرتر کرد. جذابیت Docker این بود که یک زبان روزمره به تیمها داد: یک فایل بنویس، وابستگیها و دستور اجرا را مشخص کن، image بساز، و همان image را در محیطهای مختلف اجرا کن. به زبان ساده، Docker مشکل «این برنامه دقیقاً با چه محیطی اجرا میشود؟» را قابل کنترلتر کرد.
کانتینر کمک میکند برنامه و وابستگیهای اجراییاش را در یک بستهی قابل حملتر قرار دهیم. هدف این نیست که همهی تفاوتهای محیطی جادویی از بین بروند؛ هدف این است که اجرای برنامه قابل تکرارتر، شفافتر و کمتر وابسته به تنظیمات دستی هر ماشین باشد.
فرض کنیم سرویس سفارش با Python نوشته شده است. بدون کانتینر، ممکن است روی هر سرور دستی Python نصب کنیم، پکیجها را نصب کنیم، تنظیمات را بچینیم و امیدوار باشیم همهچیز شبیه محیط توسعه است. با Docker معمولاً یک Dockerfile مینویسیم و در آن مشخص میکنیم از چه نسخهای از Python استفاده شود، چه وابستگیهایی نصب شود، کد کجا کپی شود و دستور اجرای برنامه چیست. بعد از روی آن یک image ساخته میشود.
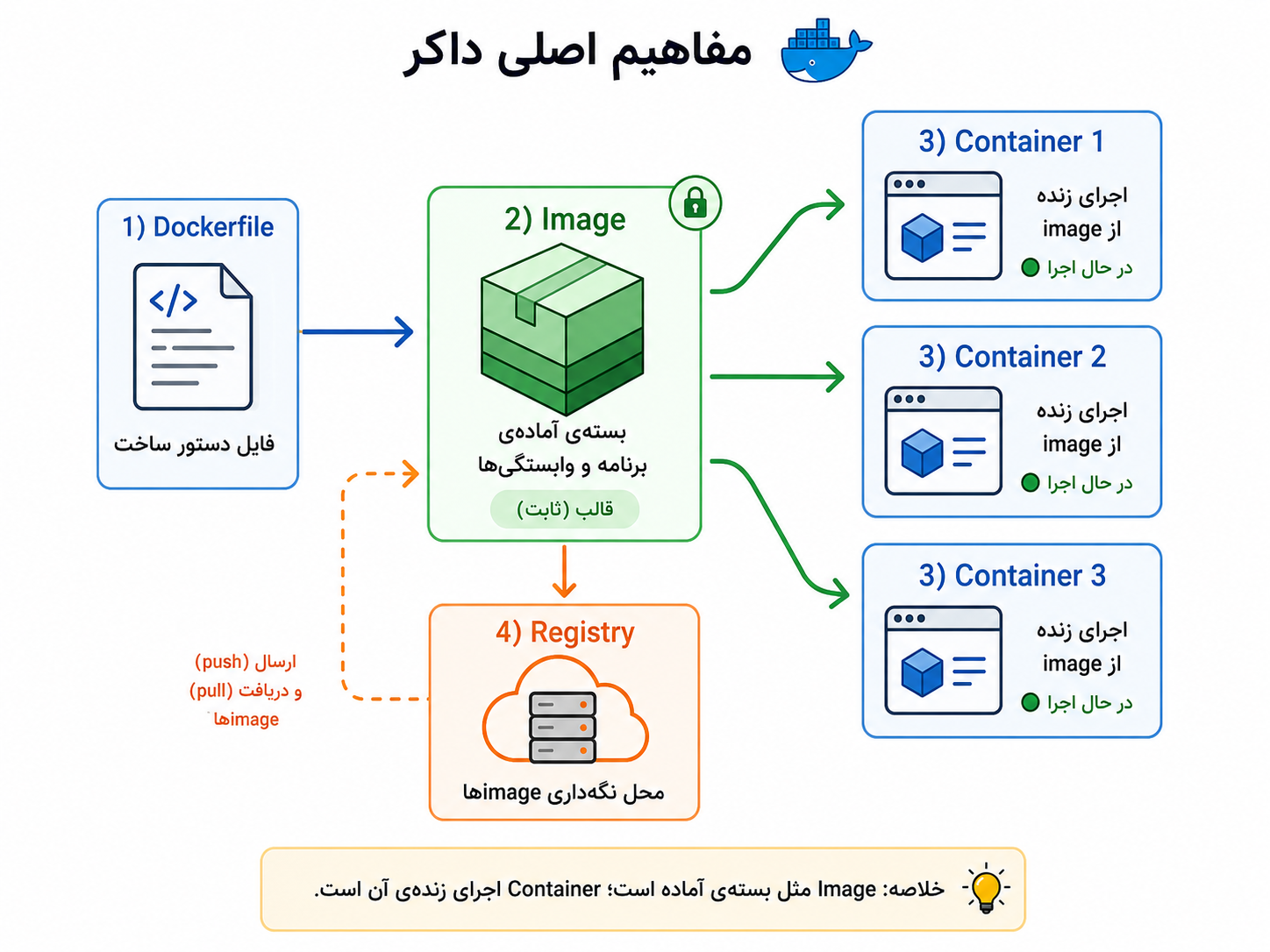
از Dockerfile یک image ساخته میشود؛ image مثل بستهی آماده و ثابت برنامه است، container اجرای زندهی همان image است، و registry جایی است که imageها را در آن نگهداری و جابهجا میکنیم.
چند واژهی پایهای اینجا مهماند:
| مفهوم | توضیح ساده |
|---|---|
| Image | بستهی آمادهی برنامه و وابستگیهای اجراییاش |
| Container | اجرای زندهی یک image |
| Dockerfile | دستورالعمل ساخت image |
| Registry | جایی برای نگهداری و انتشار imageها؛ مثل Docker Hub یا registry داخلی |
| Volume | راهی برای وصل کردن دادهی بیرونی یا ماندگار به container |
تا اینجا Docker و کانتینر کمک میکنند برنامه را تمیزتر و قابل حملتر اجرا کنیم. اما این پایان داستان نیست. وقتی فقط یک سرویس کوچک داریم، شاید Docker یا Docker Compose برای توسعه و حتی بعضی استقرارهای ساده کافی باشد. Docker Compose ابزاری است که اجازه میدهد چند کانتینر مرتبط را با یک فایل کنار هم تعریف و اجرا کنیم؛ مثلاً برنامه، پایگاه داده و Redis را برای محیط توسعه با یک دستور بالا بیاوریم. Compose کمک میکند اجرای چندتکهی یک برنامه سادهتر شود، اما معمولاً برای مدیریت جدی سرویسها در مقیاس تولید، جای Kubernetes را نمیگیرد.
اگر Docker میگوید «یک برنامه را داخل container اجرا کن»، Docker Compose میگوید «چند container مرتبط را کنار هم اجرا کن». برای توسعه، تست محلی و استقرارهای ساده میتواند بسیار مفید باشد؛ اما چیزهایی مثل self-healing، rollout تدریجی، service discovery در مقیاس بزرگ و مدیریت چند ماشین، همان جایی است که کمکم پای Kubernetes وسط میآید.
وقتی محصول بزرگتر میشود و چند سرویس داریم، مسئلهها عوض میشوند: سرویس سفارش، پرداخت، کاربر، اعلان، گزارش، workerها، پایگاه داده، صف پیام و چند نسخهی همزمان از سرویسها.
حالا پرسشهای تازهای داریم. اگر کانتینر سرویس سفارش خراب شد، چه کسی دوباره آن را بالا بیاورد؟ اگر ترافیک زیاد شد، چه کسی تعداد نمونهها را بیشتر کند؟ اگر نسخهی جدید منتشر کردیم، چطور آرامآرام جایگزین نسخهی قدیمی شود؟ سرویس پرداخت چطور آدرس پایدار سرویس سفارش را پیدا کند؟ تنظیمات غیرحساس و رمزها کجا نگهداری شوند؟ از کجا بفهمیم یک نمونه سالم است یا باید از مسیر ترافیک خارج شود؟
اینجا Kubernetes وارد داستان میشود. Kubernetes را گوگل در سال ۲۰۱۴ معرفی کرد و طراحی آن از تجربهی داخلی گوگل در اجرای workloadهای بزرگ، بهویژه سامانههایی مثل Borg، الهام گرفته بود. نسخهی ۱.۰ آن در سال ۲۰۱۵ منتشر شد و بعدتر به یکی از پایههای مهم دنیای cloud-native تبدیل شد. اگر Docker به توسعهدهندهها گفت «برنامه را قابل بستهبندیتر کن»، Kubernetes گفت «حالا تعداد زیادی از این بستهها را در یک محیط واقعی مدیریت کن».
ماشین مجازی میگفت: محیط کاملتری را با خودت ببر. کانتینر گفت: سبکتر و توسعهدهندهپسندتر بستهبندی کن. Docker Compose گفت: چند کانتینر مرتبط را راحتتر کنار هم اجرا کن. Kubernetes گفت: حالا تعداد زیادی اجرای کانتینری را در چند ماشین، با بازیابی، مقیاسدهی و بهروزرسانی مدیریت کن.
Kubernetes یک هماهنگکننده یا orchestrator است. یعنی ما وضعیت مطلوب را به آن میگوییم، و Kubernetes تلاش میکند آن وضعیت را حفظ کند. مثلاً میگوییم از سرویس سفارش همیشه سه نمونه در حال اجرا باشد. اگر یکی از آنها خراب شود، Kubernetes تلاش میکند نمونهی تازهای بالا بیاورد. اگر نسخهی جدید منتشر کنیم، میتواند نسخهی قدیمی را کمکم با نسخهی تازه جایگزین کند. اگر بخواهیم سرویسها همدیگر را پیدا کنند، برایشان آدرس پایدار فراهم میکند.
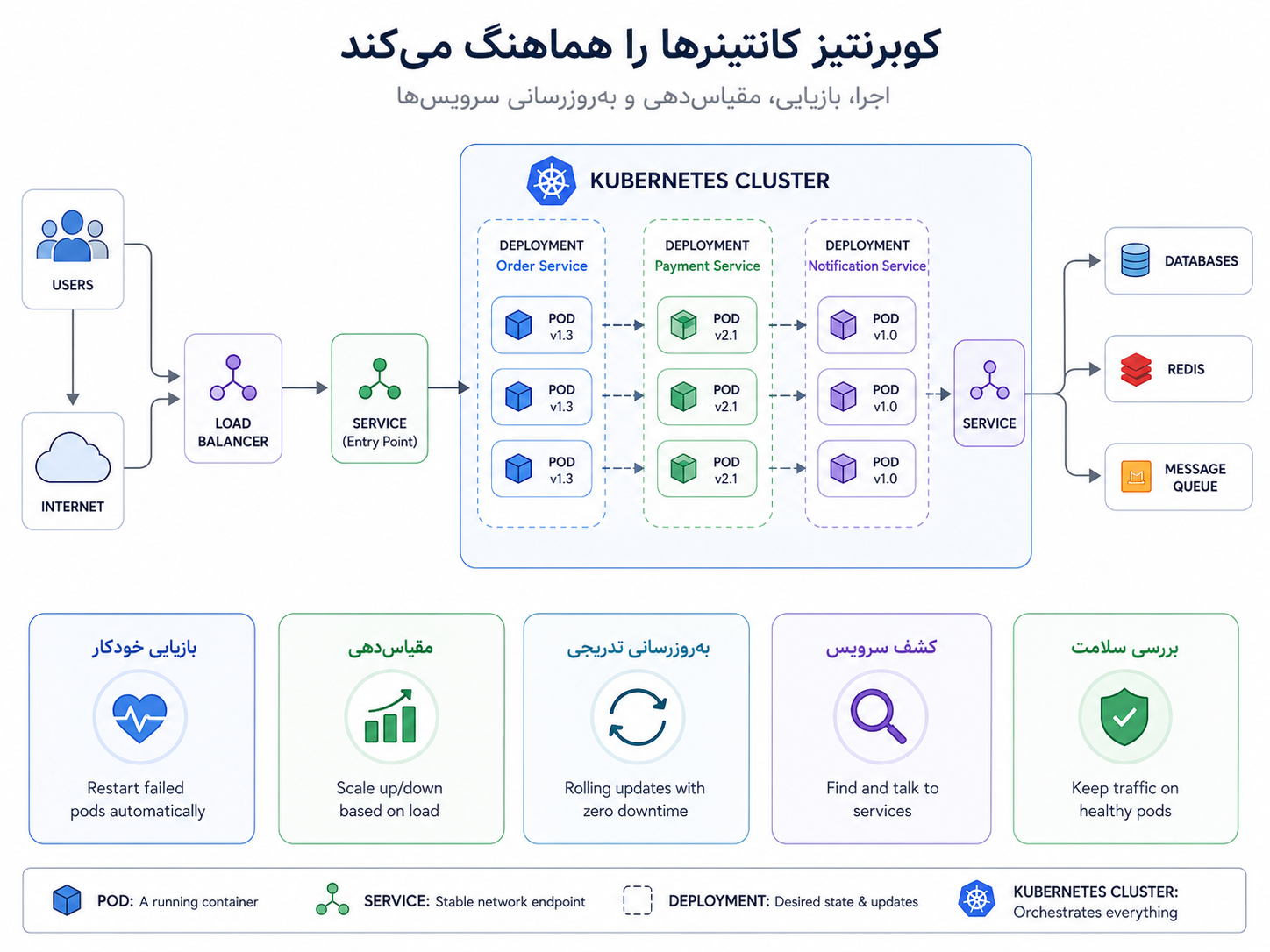
کانتینرها برنامه را قابل بستهبندیتر میکنند؛ Kubernetes اجرای تعداد زیادی کانتینر را در محیط واقعی هماهنگ میکند.
برای فهم اولیهی Kubernetes، این چند مفهوم کافی است:
| مفهوم | توضیح ساده |
|---|---|
| Pod | کوچکترین واحد اجرایی در Kubernetes؛ معمولاً جایی که کانتینر برنامه اجرا میشود |
| Deployment | تعریف میکند چند نمونه از برنامه اجرا شود و بهروزرسانی چگونه انجام شود |
| Service | آدرس پایدار برای دسترسی به Podها، حتی اگر خود Podها تغییر کنند |
| ConfigMap | نگهداری تنظیمات غیرحساس برنامه |
| Secret | نگهداری دادههای حساس مثل رمز، توکن و کلیدها |
| Health Check | راهی برای تشخیص اینکه برنامه سالم است یا باید از مدار خارج شود |
| Rollout | جایگزین کردن تدریجی نسخهی قدیمی با نسخهی جدید |
یک مثال ساده را در نظر بگیریم. ما سرویس سفارش را containerize میکنیم و image آن را در registry میگذاریم. بعد در Kubernetes یک Deployment تعریف میکنیم که بگوید سه نمونه از این سرویس اجرا شود. یک Service هم تعریف میکنیم تا بقیهی سرویسها لازم نباشد آدرس تکتک Podها را بدانند. تنظیماتی مثل نام صف یا آدرس سرویسهای داخلی میتواند در ConfigMap بیاید، و چیزهایی مثل رمز اتصال به پایگاه داده در Secret نگهداری شود. اگر یکی از Podها خراب شود، Kubernetes تلاش میکند نمونهی جایگزین بالا بیاورد. اگر نسخهی تازهای از image منتشر کنیم، Deployment میتواند rollout انجام دهد.
اینها کمک میکنند اجرای سرویسها از حالت «چند دستور دستی روی چند ماشین» به وضعیتی نزدیکتر شود که قابل تعریف، قابل پیگیری و قابل تکرار است. اما نباید دچار خیالپردازی شویم: Kubernetes پیچیدگی عملیاتی جدی دارد. خود خوشه باید نصب، نگهداری، پایش، امنسازی و بهروزرسانی شود. اگر تیم هنوز یک برنامهی ساده دارد، شاید Docker Compose، یک ماشین مجازی، یک سکوی سادهی میزبانی یا حتی یک PaaS انتخاب بهتری باشد.
Kubernetes جایزهی بلوغ فنی نیست که هر پروژهای باید زود به آن برسد. اگر تعداد سرویسها کم است، ترافیک ساده است، rollout و مقیاسدهی پیچیده نداریم، و تیم هنوز هزینهی عملیاتی Kubernetes را نمیپذیرد، آوردن آن میتواند بیش از آنکه کمک کند، سیستم را سنگینتر کند.
| وضعیت | انتخاب محتملتر |
|---|---|
| یک برنامهی ساده برای تیم کوچک | اجرای مستقیم، Docker Compose یا یک PaaS ساده |
| چند سرویس با نیاز به محیطهای مشابه | Docker، Docker Compose و registry داخلی میتوانند کمک کنند |
| سرویسهای متعدد با rollout، scaling و self-healing | Kubernetes میتواند ارزشمند شود |
| چند کار کوتاه و پراکنده | شاید Serverless یا Job/CronJob ساده مناسبتر باشد |
| نیاز به کنترل کامل روی شبکه، منابع و استقرار | Kubernetes گزینهی جدیتری است، اما با هزینهی عملیاتی بیشتر |
برای من، کانتینرها پاسخ به یک درد خیلی انسانیاند: «چرا این برنامه اینجا کار میکند و آنجا نه؟» و Kubernetes پاسخ به درد مرحلهی بعدی است: «حالا که همهچیز را کانتینری کردیم، چه کسی این همه اجرا را در محیط واقعی زنده، سالم، قابل کشف و قابل بهروزرسانی نگه دارد؟» این دو یکی نیستند، اما به هم وصلاند. Docker بیشتر دربارهی بستهبندی و اجرای تکرارپذیر است؛ Docker Compose اجرای چند کانتینر مرتبط را سادهتر میکند؛ Kubernetes بیشتر دربارهی هماهنگکردن و نگهداری تعداد زیادی اجرای کانتینری در محیط واقعی است.
تا اینجا دربارهی سرویسهایی حرف زدیم که واقعاً باید اجرا شوند، نسخه داشته باشند، در دسترس بمانند و در محیطهای مختلف قابل تکرار باشند. اما همهی کارهای سیستم از جنس سرویس دائمی نیستند. بعضی کارها فقط گاهی و در واکنش به یک رخداد، پیام، زمانبندی یا وبهوک اجرا میشوند. آیا برای آنها هم باید Deployment یا worker همیشهروشن داشته باشیم؟ این همان پرسشی است که ما را به Serverless میرساند.
وقتی بعضی کارها ارزش سرویس دائمی ندارند
تا اینجا دربارهی سرویسهایی حرف زدهایم که باید قابل اجرا، قابل بستهبندی و قابل مدیریت باشند. اما همهی کارهای سیستم از جنس سرویس دائمی نیستند. بعضی کارها کوتاه، پراکنده و واکنشیاند: رسیدگی به یک وبهوک پرداخت، ساخت تصویر بندانگشتی بعد از آپلود فایل، تولید یک گزارش سبک زمانبندیشده، پاکسازی دادههای موقت، یا ارسال اعلان بعد از رسیدن یک پیام.
سؤال اصلی این فصل این است: آیا برای هر کار کوتاه و مقطعی باید یک سرویس یا worker همیشهروشن نگه داریم؟ گاهی جواب بله است، اما همیشه نه. اگر کاری فقط هنگام رسیدن یک رخداد یا زمانبندی خاص اجرا میشود، شاید بتوان آن را به شکل تابع یا واحد اجرایی کوتاهعمر اجرا کرد؛ چیزی که فقط هنگام نیاز روشن میشود و بعد از پایان کار، دیگر لازم نیست مثل یک سرویس دائمی زنده بماند.
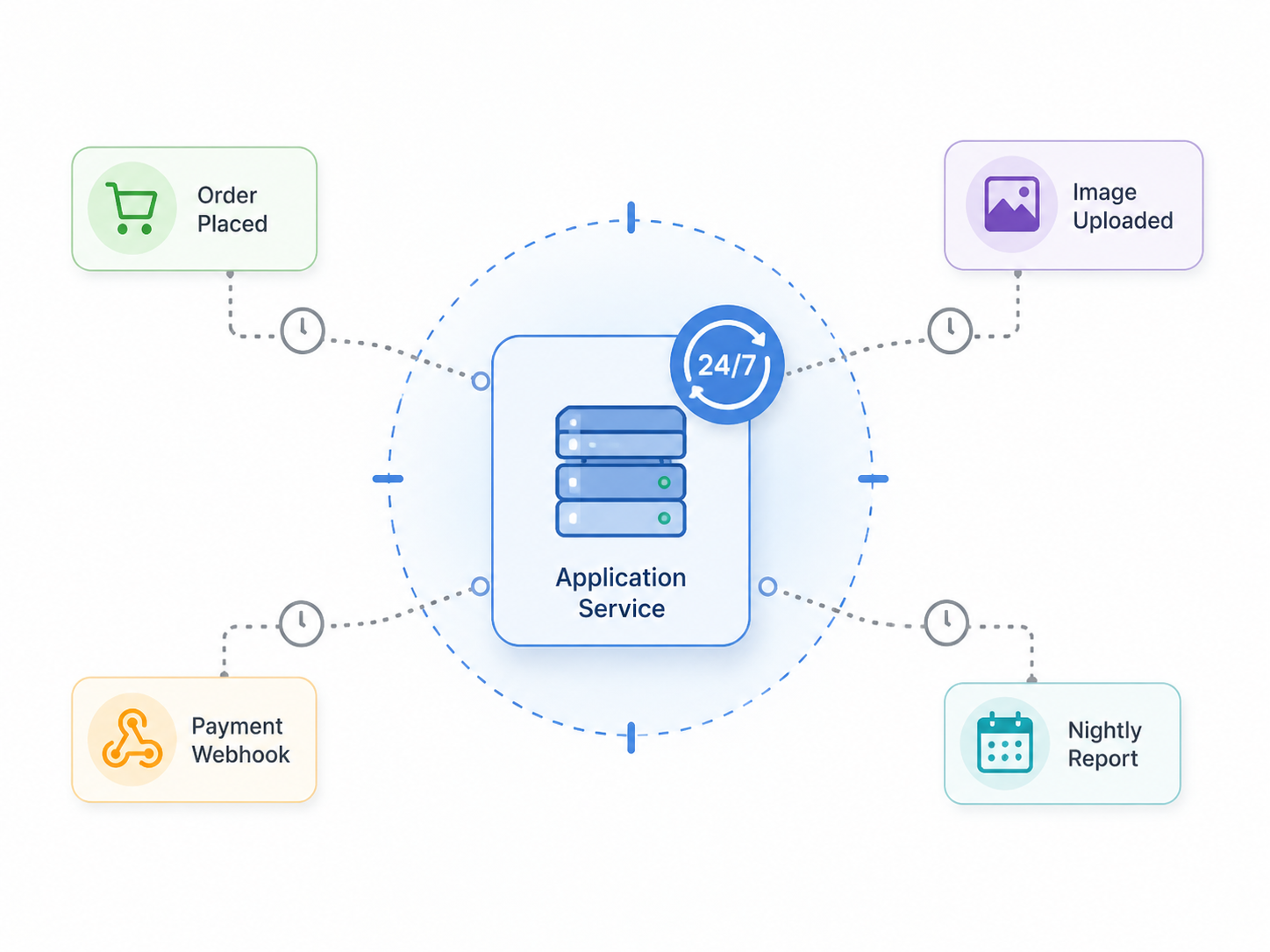
وقتی کارها کوتاه و پراکندهاند، نگه داشتن یک سرویس همیشهروشن ممکن است بیش از نیاز واقعی هزینه و پیچیدگی بسازد.
معماری بیسرور یا Serverless Architecture از همین پرسش شروع میشود. نامش کمی گمراهکننده است: بیسرور یعنی سروری وجود ندارد؟ نه. سرور هست، اما ما بهصورت مستقیم آن را مدیریت نمیکنیم. در این مدل، معمولاً منطق کوچک و مشخصی را به شکل تابع تعریف میکنیم و سکوی اجرا آن را هنگام نیاز اجرا میکند: با یک درخواست HTTP، با یک پیام در صف، با یک زمانبندی، با آپلود فایل، یا با رسیدن یک وبهوک.
Serverless برای کارهایی جذاب است که کوتاه، مستقل، رخدادمحور یا زمانبندیشدهاند و نمیخواهیم برای آنها یک سرویس همیشهروشن نگه داریم. تمرکز از «نگهداری یک سرویس دائمی» به «اجرای کد هنگام نیاز» جابهجا میشود.
برای ملموستر شدن، فرض کنید سرویس پرداخت بعد از موفق شدن پرداخت، یک وبهوک به سیستم ما میفرستد. در مدل معمول، ممکن است یک سرویس همیشهروشن داشته باشیم که منتظر این درخواستها بماند. در مدل Serverless، میتوانیم یک تابع کوچک تعریف کنیم که فقط وقتی این وبهوک رسید اجرا شود: امضای درخواست را بررسی کند، تکراری نبودن پیام را بسنجد، وضعیت پرداخت را ذخیره کند، و اگر لازم بود یک پیام برای ادامهی پردازش منتشر کند. بعد از تمام شدن کار، تابع هم تمام میشود.
در عمل، این مدل را با ابزارها و سکوهای مختلفی میبینیم. در دنیای ابری، نامهایی مثل AWS Lambda، Google Cloud Functions، Azure Functions، Cloudflare Workers، Vercel Functions و Netlify Functions زیاد شنیده میشوند. در فضای نزدیک به Kubernetes هم ابزارهایی مثل Knative و OpenFaaS مطرح میشوند. هدف این نوشته مقایسهی این ابزارها نیست؛ فقط میخواهیم جای ذهنیشان روشن شود: اینها کمک میکنند کدی کوچک را در واکنش به یک محرک اجرا کنیم، بدون اینکه خودمان مستقیماً یک سرویس دائمی برای آن نگه داریم.
| کار نمونه | محرک اجرا | شکل رایج پیادهسازی |
|---|---|---|
| بررسی وبهوک پرداخت | رسیدن یک درخواست HTTP | یک تابع Serverless پشت یک endpoint |
| ساخت تصویر بندانگشتی | بارگذاری فایل در فضای ذخیرهسازی | تابعی که با رخداد آپلود اجرا میشود |
| ارسال اعلان | رسیدن پیام در صف | تابعی که پیام را مصرف و اعلان را ارسال میکند |
| گزارش سبک شبانه | زمانبندی یا Cron | تابع زمانبندیشده |
| پاکسازی دادههای موقت | اجرای دورهای | تابعی کوچک برای حذف یا آرشیو دادهها |
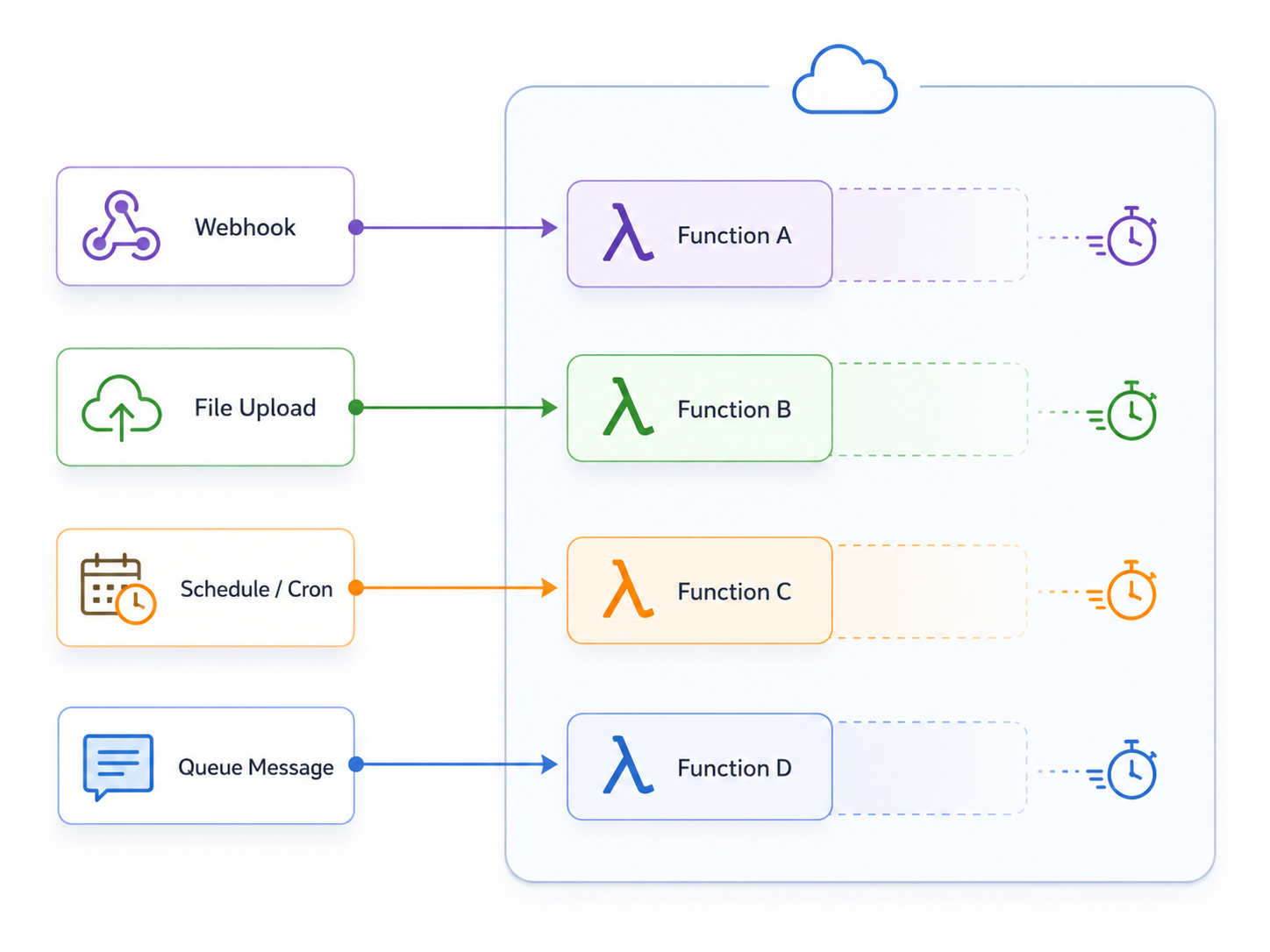
در این مدل، تابع فقط هنگام نیاز اجرا میشود و بعد از پایان کار، لازم نیست بهعنوان یک سرویس دائمی روشن بماند.
اینجا ممکن است یک پرسش طبیعی پیش بیاید: «خب فرق این با Celery چیست؟ Celery هم کار پسزمینه اجرا میکند.» شباهتشان این است که هر دو میتوانند برای کارهای غیرهمزمان و خارج از مسیر اصلی درخواست استفاده شوند؛ مثلاً ارسال ایمیل، پردازش فایل یا اجرای یک کار زمانبر. اما تفاوت اصلی در مدل اجرا و مالکیت زیرساخت است. در Celery معمولاً خودمان workerها را اجرا و مدیریت میکنیم، یک broker مثل Redis یا RabbitMQ داریم، و ظرفیت، استقرار، پایش و مقیاسدهی workerها با خودمان است. در Serverless، اجرای تابع و بخشی از مقیاسدهی را به سکوی اجرا میسپاریم.
Celery بیشتر یک چارچوب اجرای کارهای پسزمینه در برنامهی خودمان است؛ یعنی worker داریم، broker داریم، و زیرساخت اجرای آن را خودمان نگه میداریم. Serverless بیشتر یک مدل اجرای تابع روی سکوی ابری یا سکوی اجرای بیرونی است؛ تابع هنگام محرک اجرا میشود و مدیریت مستقیم سرور و مقیاسدهی کمتر بر عهدهی تیم برنامه است.
بحث هزینه اینجا مهم است، اما باید با احتیاط دربارهاش حرف زد. گاهی Serverless برای کارهای کمتعداد، کوتاه و پراکنده جذاب است، چون به جای روشن نگه داشتن یک سرویس دائمی، بیشتر هنگام اجرا هزینه میدهیم. اگر کاری روزی چند بار اجرا شود یا فقط هنگام رخدادهای خاص لازم باشد، این مدل میتواند بهصرفهتر باشد.
اما این همیشه به معنی ارزانتر بودن نیست. اگر تابعها بسیار پرتعداد اجرا شوند، زمان اجرای طولانی داشته باشند، دادهی زیادی جابهجا کنند، یا زنجیرهای از تابعهای کوچک پشت سر هم راه بیفتد، هزینه میتواند غافلگیرکننده شود. حتی اگر هزینهی مالی خوب به نظر برسد، هزینهی خطایابی، مشاهدهپذیری، وابستگی به ارائهدهنده و پیچیدگی عملیاتی هم باید حساب شود.
Serverless ممکن است هزینهی اجرای کارهای کوتاه و پراکنده را کم کند، اما میتواند هزینهی فهم، پایش و خطایابی سیستم را بالا ببرد. پس انتخاب آن باید بر اساس الگوی مصرف، زمان اجرا، حجم داده و توان عملیاتی تیم باشد؛ نه فقط جذابیت ظاهری مدل پرداخت.
Serverless چند چالش فنی هم دارد. یکی از شناختهشدهترین آنها شروع سرد یا Cold Start است؛ یعنی تابعی که مدتی اجرا نشده، ممکن است در نخستین اجرا کمی دیرتر آماده شود. محدودیت زمان اجرا هم مهم است؛ بسیاری از بسترهای Serverless برای پردازشهای خیلی طولانی مناسب نیستند. از طرف دیگر، اگر تابعها زیاد و پراکنده شوند، دنبال کردن مسیر یک خطا از میان چند تابع کوچک سختتر میشود. همچنین ممکن است به قراردادها و ابزارهای یک ارائهدهندهی خاص وابسته شویم.
| وضعیت | Serverless مناسبتر است؟ | چرا؟ |
|---|---|---|
| کار کوتاه، مستقل و رخدادمحور است | معمولاً بله | لازم نیست سرویس دائمی نگه داریم. |
| کار کمتعداد و پراکنده است | معمولاً بله | هزینه بیشتر هنگام اجرا پرداخت میشود. |
| کار پرترافیک و دائماً فعال است | نه همیشه | سرویس دائمی یا worker دائمی ممکن است قابل پیشبینیتر و حتی ارزانتر باشد. |
| پردازش طولانی یا سنگین است | با احتیاط | محدودیت زمان اجرا و هزینه میتواند مشکلساز شود. |
| کار به وضعیت درونی پیچیده نیاز دارد | با احتیاط | Serverless برای کارهای کوتاه و کموضعیت مناسبتر است. |
| تیم کنترل کامل روی workerها میخواهد | نه همیشه | Celery یا سرویس worker معمولی شاید مناسبتر باشد. |
| تیم به مشاهدهپذیری دقیق نیاز دارد | با طراحی دقیق | خطایابی میان چند تابع پراکنده میتواند سختتر شود. |
Serverless یعنی کل سیستم را از روز اول به چند تابع کوچک تبدیل کنیم؟ نه. خیلی از سرویسها باید همیشه در دسترس، قابل کنترل، قابل مشاهده و دارای چرخهی عمر روشن باشند. Serverless برای بعضی کارها عالی است، اما برای همهی مسئلهها نه.
چه زمانی Serverless انتخاب خوبی است؟
وقتی کاری کوتاه، مستقل، کموضعیت، رخدادمحور یا زمانبندیشده داریم، Serverless میتواند انتخاب خوبی باشد. مثلاً پردازش یک فایل بعد از آپلود، ارسال اعلان بعد از یک رخداد، پاکسازی دورهای دادههای موقت یا واکنش به یک وبهوک پرداخت.
چه زمانی Celery یا worker دائمی ممکن است مناسبتر باشد؟
اگر کارها پیوسته و پرتعدادند، کنترل دقیق روی workerها میخواهیم، کارها به محیط داخلی برنامه خیلی وابستهاند، یا تیم از قبل broker، پایش و مقیاسدهی workerها را خوب مدیریت میکند، Celery یا یک سرویس worker معمولی میتواند سادهتر و قابل پیشبینیتر باشد.
برای من، Serverless یعنی لازم نیست برای هر کار کوچک، یک چراغ همیشه روشن نگه داریم. بعضی کارها فقط وقتی باید اجرا شوند که چیزی اتفاق افتاده، پیامی رسیده، زمانی فرا رسیده یا فایلی بارگذاری شده است. اما همین آزادی اگر بدون فهم هزینه، محدودیت و مشاهدهپذیری بیاید، میتواند سیستم را پراکنده و سختفهم کند.
وقتی سرویسهای دائمی، کارهای کوتاهعمر و منابع اجرایی زیاد میشوند، یک پرسش تازه پیدا میشود: این همه تعریف، تنظیم، دسترسی، صف، تابع، سرویس و محیط را چطور قابل تکرار و قابل بازبینی نگه داریم؟ این همان جایی است که Infrastructure as Code وارد داستان میشود.
وقتی زیرساخت هم باید قابل بازبینی باشد
تا اینجا دربارهی سرویسها، کانتینرها، Kubernetes و Serverless حرف زدیم. کمکم سیستم ما فقط چند فایل کد نیست؛ پایگاه داده دارد، صف پیام دارد، شبکه دارد، کلاستر دارد، دسترسی دارد، تنظیمات محیطی دارد و برای هر محیط، از آزمایشی تا تولید، باید شکل نسبتاً قابل اعتمادی داشته باشد.
اما اینجا یک درد آشنا دوباره برمیگردد. یک نفر میخواهد محیط آزمایشی را شبیه تولید بسازد و میپرسد: نسخهی پایگاه داده دقیقاً چیست؟ صف پیام با چه تنظیماتی ساخته شده؟ چه کسی این دسترسی را به سرویس پرداخت داده؟ چرا در تولید این متغیر محیطی هست ولی در آزمایشی نیست؟ اگر فردا کل محیط را از دست بدهیم، میتوانیم دوباره آن را بسازیم؟
اگر پاسخ این پرسشها در چند کلیک دستی، چند دستور پراکنده، حافظهی آدمها و مستندات قدیمی پخش شده باشد، زیرساخت خودش تبدیل به منبع خطا میشود. همانطور که کد بدون نسخهبندی و بازبینی خطرناک است، زیرساختی هم که معلوم نیست چه کسی، چه چیزی را، کجا و چرا تغییر داده، دیر یا زود دردسر میسازد.
Infrastructure as Code یعنی زیرساخت را با فایلهایی تعریف کنیم که قابل نسخهبندی، بازبینی، تکرار و بازسازیاند؛ نه اینکه بخش مهمی از سیستم فقط در پنلها، دستورهای دستی و حافظهی افراد زندگی کند.
زیرساخت بهمثابه کد یا Infrastructure as Code، که معمولاً IaC گفته میشود، از همین نیاز میآید. ایده این است که بهجای ساختن دستی منابع، وضعیت مطلوب زیرساخت را در فایلهایی تعریف کنیم: این پایگاه داده را میخواهیم، این شبکه باید وجود داشته باشد، این صف پیام با این تنظیمات ساخته شود، این سرویس این دسترسی را داشته باشد، و این کلاستر Kubernetes با این ویژگیها آماده شود.
وقتی این تعریفها وارد Git میشوند، تغییر زیرساخت هم از حالت «کار پنهان در پنل و ترمینال» بیرون میآید. میتوان تغییر را دید، بررسی کرد، دربارهاش نظر داد، تاریخچهاش را فهمید و در بسیاری از موارد دوباره اجرا کرد. هدف این نیست که زیرساخت جادویی شود؛ هدف این است که تصمیمهای زیرساختی از حافظهی افراد بیرون بیاید و به دارایی قابل نگهداری تیم تبدیل شود.
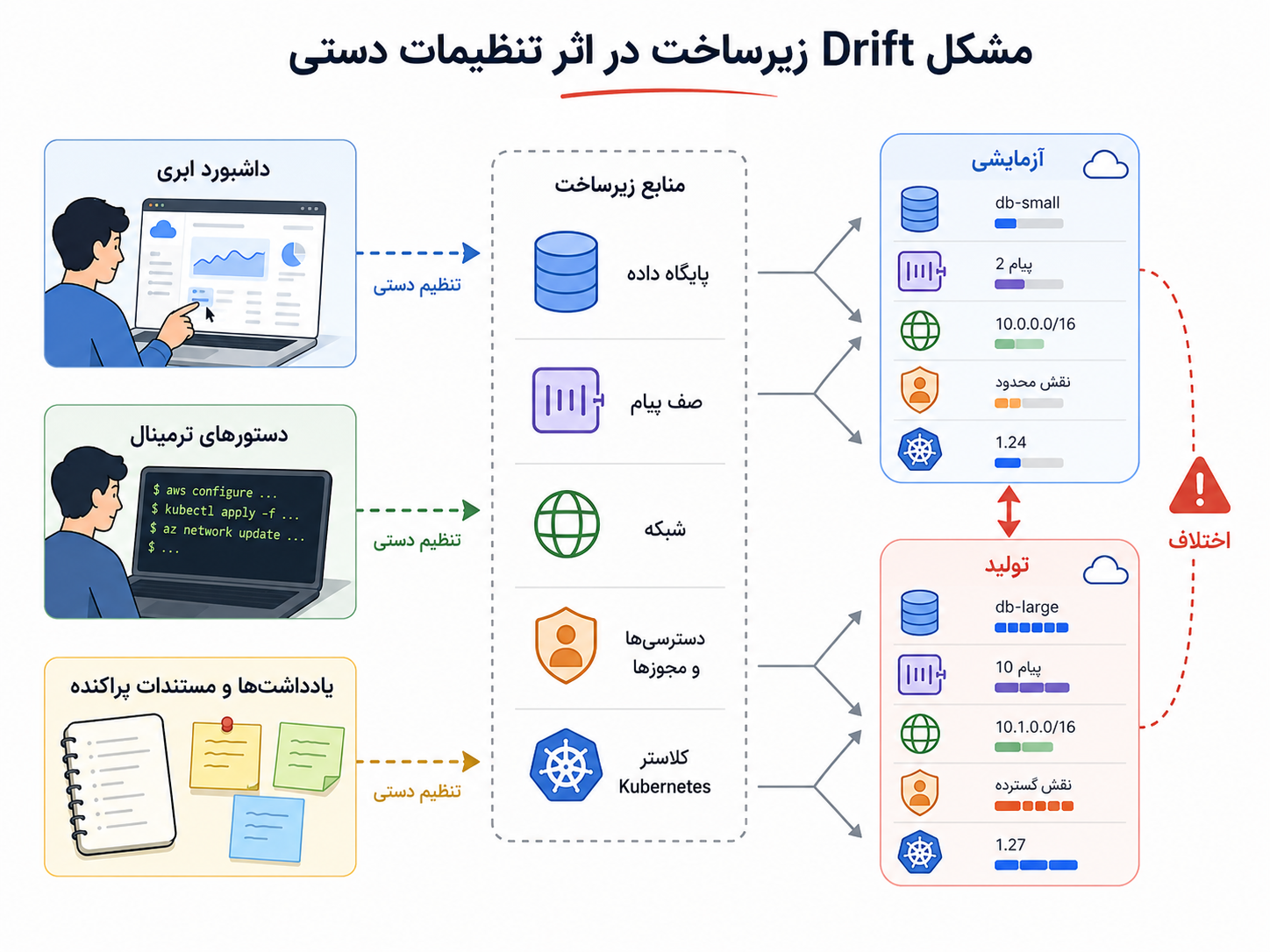
وقتی زیرساخت با کد تعریف میشود، محیطها کمتر به حافظهی افراد و کلیکهای دستی وابسته میمانند.
اینجا باید یک مرز مهم را روشن کنیم: IaC فقط «اتوماسیون» نیست. اتوماسیون میتواند یک اسکریپت باشد که چند دستور را پشت سر هم اجرا میکند. IaC معمولاً یک قدم جلوتر میرود و میگوید وضعیت مطلوب زیرساخت چیست و ابزار تلاش میکند محیط را به آن وضعیت نزدیک کند. البته همهی ابزارها دقیقاً یکسان کار نمیکنند، اما در نگاه کلی، تفاوت این است: اسکریپت بیشتر میگوید «چه کارهایی انجام بده»، IaC بیشتر تلاش میکند بگوید «زیرساخت در نهایت باید چه شکلی باشد».
چند خانواده ابزار در این فضا زیاد دیده میشوند:
| ابزار یا خانواده | معمولاً برای چه چیزی به کار میآید؟ |
|---|---|
| Terraform | تعریف و مدیریت منابعی مثل شبکه، پایگاه داده، صف، load balancer و منابع ابری |
| Pulumi | تعریف زیرساخت با زبانهای برنامهنویسی عمومیتر مثل TypeScript یا Python |
| Ansible | پیکربندی ماشینها، نصب بستهها و اجرای کارهای عملیاتی |
| Kubernetes manifests | تعریف مستقیم منابع Kubernetes مثل Deployment، Service، ConfigMap و Secret |
| Helm | بستهبندی، نصب و نسخهبندی برنامهها روی Kubernetes |
| Kustomize | تنظیم و تغییر manifestهای Kubernetes برای محیطهای مختلف |
| Vault | نگهداری و کنترل دسترسی به رازها، کلیدها و دادههای حساس |
این ابزارها جای هم نیستند. Terraform معمولاً برای ساخت و مدیریت منابع زیرساختی بیرون یا پیرامون برنامه به کار میآید؛ مثلاً شبکه، پایگاه داده، صف یا منابع ابری. Helm و Kustomize بیشتر در فضای Kubernetes کمک میکنند برنامهها و منابع داخل کلاستر را تعریف و تنظیم کنیم. Ansible بیشتر به پیکربندی ماشینها و اجرای کارهای عملیاتی نزدیک است. Vault هم مسئلهی دیگری را هدف میگیرد: رازها و دادههای حساس را چطور امن، کنترلشده و قابل ردیابی نگه داریم.
Helm را میتوان مثل یک بستهبند برای برنامههای Kubernetes دید. وقتی یک برنامه فقط یک Deployment ندارد و همراه خودش Service، ConfigMap، Ingress، Secret و چند مقدار قابل تنظیم دارد، نوشتن و نگهداری manifestهای خام میتواند سخت و تکراری شود. Helm این منابع را در قالب chart بستهبندی میکند و اجازه میدهد برای محیطهای مختلف، مقدارهای متفاوت بدهیم؛ مثلاً تعداد replica، آدرس سرویسها یا تنظیمات منابع.
Terraform معمولاً منابع زیرساختی را میسازد یا مدیریت میکند؛ Helm معمولاً برنامه را روی Kubernetes نصب و تنظیم میکند؛ Argo CD میتواند مراقب باشد چیزی که در Git تعریف شده، واقعاً روی کلاستر هم اجرا شود. این سه ابزار ممکن است کنار هم استفاده شوند، اما نقششان یکی نیست.
برای اینکه ماجرا ملموستر شود، فرض کنید سرویس سفارش به یک پایگاه داده، یک صف پیام، چند متغیر محیطی، چند Secret و یک Deployment روی Kubernetes نیاز دارد. بدون IaC، ممکن است بخشی از اینها در پنل ابری ساخته شود، بخشی با دستور دستی، بخشی با فایلهای پراکنده و بخشی هم در ذهن افراد بماند. با IaC، تلاش میکنیم همین نیازها را در فایلهایی قابل بازبینی تعریف کنیم؛ فایلهایی که تغییراتشان دیده میشود و میتوان دربارهشان تصمیم گرفت.
اما یک نقطهی حساس در این میان وجود دارد: رازها. رمز اتصال به پایگاه داده، کلید دسترسی به سرویس بیرونی، توکنها و گواهیها نباید مثل تنظیمات معمولی در repository پخش شوند. Kubernetes چیزی به نام Secret دارد، اما این بهتنهایی پاسخ کامل مدیریت رازها نیست. Secret میگوید این دادهی حساس باید به شکل یک منبع جدا در کلاستر وجود داشته باشد؛ اما اینکه رازها از کجا بیایند، چه کسی به آنها دسترسی داشته باشد، چطور بچرخند، چطور audit شوند و چطور وارد کلاستر شوند، مسئلهی بزرگتری است.
اینجا ابزارهایی مثل Vault وارد میشوند. Vault کمک میکند رازها در جای متمرکزتر و کنترلشدهتری نگهداری شوند، دسترسیها با policy مشخص شوند، بعضی رازها بهصورت پویا ساخته شوند، و مسیر استفاده از آنها قابل ردیابیتر باشد. در عمل، تیمها ممکن است Vault را کنار Kubernetes، External Secrets Operator، Argo CD یا ابزارهای مشابه استفاده کنند تا رازها بدون اینکه مستقیم در Git ذخیره شوند، به برنامهها برسند.
ConfigMap برای تنظیمات غیرحساس است؛ Secret برای دادهی حساس در Kubernetes است؛ Vault یا ابزارهای مشابه برای مدیریت جدیتر چرخهی عمر رازها، کنترل دسترسی، چرخش و audit استفاده میشوند. IaC نباید باعث شود رمزها و کلیدها راحتتر و سریعتر وارد Git شوند.
وقتی پای Kubernetes وسط است، یک پرسش عملیتر هم پیدا میشود: اگر تعریف Deployment و Service و ConfigMap داخل Git است، چه کسی مطمئن شود وضعیت واقعی کلاستر شبیه همین تعریفهاست؟ اگر کسی دستی در کلاستر تعداد replica را تغییر داد چه؟ اگر نسخهای که واقعاً در حال اجراست با نسخهی داخل Git فرق داشت چه؟
اینجا GitOps وارد داستان میشود.
GitOps را میتوان اینطور ساده فهمید: Git منبع حقیقت وضعیت مطلوب سیستم است، و یک ابزار تلاش میکند وضعیت واقعی محیط را با چیزی که در Git تعریف شده هماهنگ نگه دارد. یعنی Git فقط محل نگهداری کد برنامه نیست؛ دفتر رسمی تصمیمهای اجرایی و زیرساختی هم میشود.
یکی از ابزارهای شناختهشده در این فضا Argo CD است. Argo CD معمولاً در کنار Kubernetes استفاده میشود و manifestها، Helm chartها یا تنظیمات Kustomize داخل Git را با وضعیت واقعی کلاستر مقایسه میکند. اگر اختلافی باشد، میتواند آن را نشان دهد و در صورت تنظیم، محیط را دوباره با Git همگام کند.
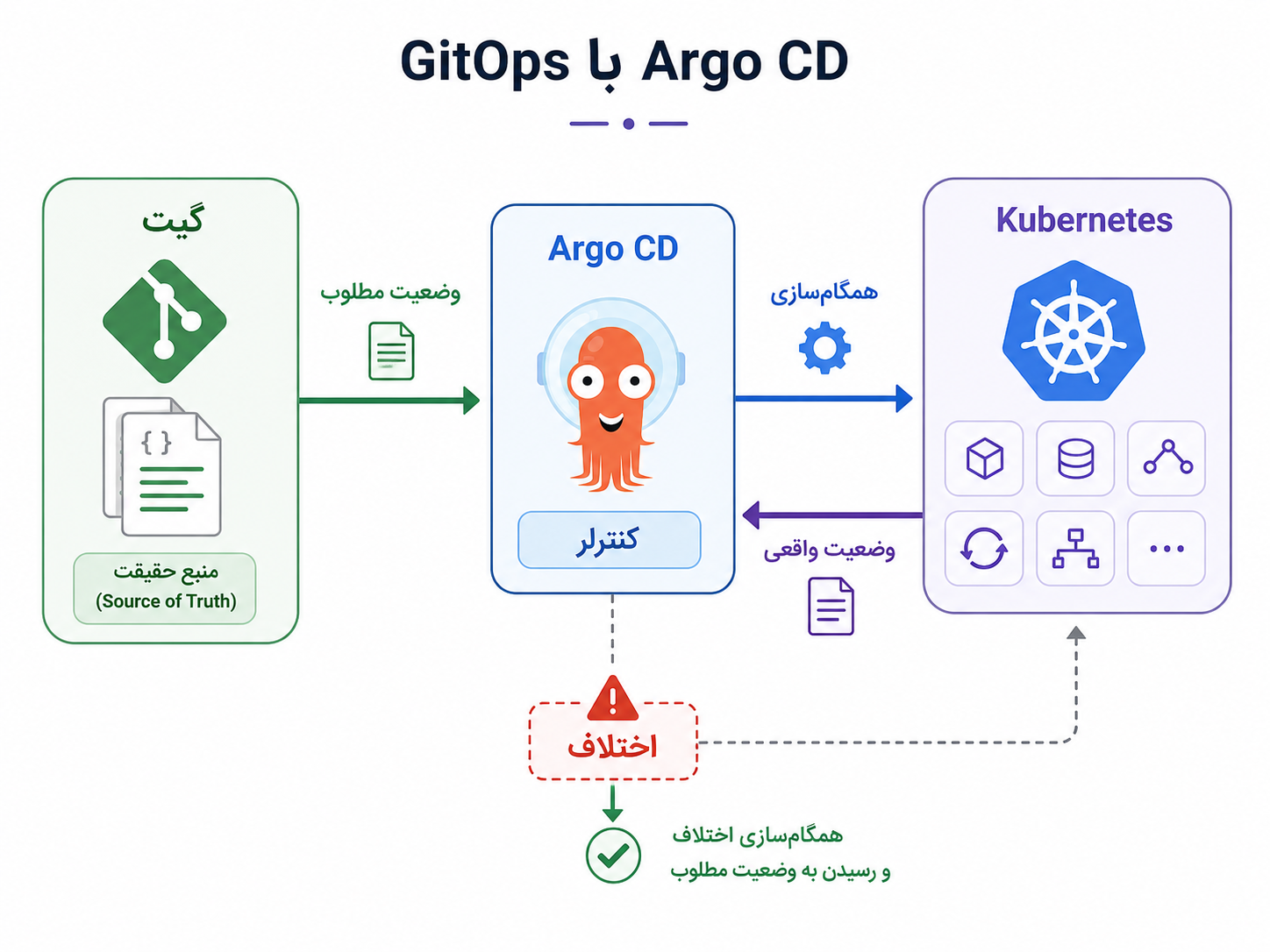
در GitOps، Git منبع حقیقت وضعیت مطلوب است و ابزاری مثل Argo CD مراقب است کلاستر از آن وضعیت منحرف نشود.
تفاوت IaC و GitOps هم مهم است. IaC بیشتر دربارهی این است که منابع و زیرساخت را چگونه با کد تعریف کنیم. GitOps بیشتر دربارهی این است که محیط واقعی چگونه با تعریفهای داخل Git همگام بماند. Argo CD هم یکی از ابزارهایی است که این ایده را، بهویژه در Kubernetes، عملی میکند.
| مفهوم | پرسش اصلی |
|---|---|
| Infrastructure as Code | زیرساخت و منابع را چطور بهصورت فایل، قابل نسخهبندی و بازبینی تعریف کنیم؟ |
| GitOps | چطور کاری کنیم محیط واقعی با تعریفهای داخل Git هماهنگ بماند؟ |
| Argo CD | چطور منابع Kubernetes را با Git مقایسه و همگام کنیم؟ |
| Terraform | منابع زیرساختی مثل شبکه، دیتابیس، صف و منابع ابری را چطور تعریف و مدیریت کنیم؟ |
| Helm / Kustomize | منابع Kubernetes را چطور بستهبندی یا برای محیطهای مختلف تنظیم کنیم؟ |
| Vault | رازها، کلیدها و دادههای حساس را چطور امنتر و کنترلشدهتر مدیریت کنیم؟ |
البته IaC و GitOps هم جادو نیستند. اگر secretها را بد مدیریت کنیم، اگر reviewها سطحی باشند، اگر کسی مستقیم در محیط تولید تغییر بدهد، اگر sync خودکار بدون کنترل روی production فعال شود، یا اگر ساختار repository شلوغ و نامفهوم شود، همین ابزارها هم میتوانند دردسر تازه بسازند.
IaC و GitOps تغییر بد را خوب نمیکنند؛ فقط مسیر تغییر را شفافتر و قابل پیگیریتر میکنند. اگر طراحی زیرساخت بد باشد، IaC همان طراحی بد را منظمتر و سریعتر تکثیر میکند. اگر تغییر خطرناک بدون بازبینی از Git به production برود، همچنان خطرناک است.
چند پرسش خوب پیش از جدی گرفتن IaC و GitOps اینهاست:
| پرسش | چرا مهم است؟ |
|---|---|
| آیا محیط واقعی با فایلهای Git فرق کرده است؟ | این همان drift است و باید دیده یا اصلاح شود. |
| secretها کجا و چطور نگهداری میشوند؟ | نباید دادهی حساس بیمحافظ وارد Git شود. |
| قبل از apply یا sync چه چیزی بازبینی میشود؟ | تغییر زیرساخت باید مثل تغییر کد review شود. |
| rollback چطور انجام میشود؟ | برگشت از تغییر بد باید از قبل قابل تصور باشد. |
| چه کسی اجازهی تغییر production را دارد؟ | IaC بدون مرز دسترسی، خطرناکتر میشود. |
| ساختار repository قابل فهم است؟ | اگر کسی نتواند مسیر تغییر را بفهمد، GitOps فقط ظاهر منظم دارد. |
چه زمانی شاید هنوز IaC کامل زود باشد؟
اگر یک محیط بسیار ساده داریم، منابع کماند، تغییرها بهندرت رخ میدهند و تیم هنوز در حال کشف نیازهای پایه است، شاید چند اسکریپت ساده و مستندات دقیق برای شروع کافی باشد. اما هرچه تعداد محیطها، منابع و افراد بیشتر شود، هزینهی تغییر دستی و حافظهمحور بالا میرود.
چه زمانی GitOps ارزشمندتر میشود؟
وقتی چند تیم روی یک یا چند کلاستر Kubernetes کار میکنند، نسخهها زیاد تغییر میکنند، drift میان Git و محیط واقعی دردسرساز شده، یا لازم است مسیر تغییرات production شفاف و قابل audit باشد، GitOps میتواند ارزش جدی پیدا کند.
برای من، Infrastructure as Code یعنی زیرساخت را از قلمرو حافظهی افراد و کلیکهای دستی بیرون بیاوریم و به چیزی تبدیل کنیم که تیم بتواند آن را ببیند، نقد کند، تغییر دهد و دوباره بسازد. GitOps هم یک قدم جلوتر میپرسد: حالا که وضعیت مطلوب در Git است، چطور مطمئن شویم محیط واقعی از آن دور نشده است؟ و مدیریت رازها یادآوری میکند که قابل بازبینی کردن زیرساخت نباید به قیمت افشا کردن دادههای حساس تمام شود.
تا اینجا دربارهی ساخت، اجرا و نگهداری زیرساخت حرف زدیم. اما وقتی محصول رشد میکند، پرسش دیگری هم ظاهر میشود: آیا همهی مشتریها، سازمانها یا گروههای کاربران از یک سیستم مشترک استفاده میکنند؟ دادهها، تنظیمات و منابع آنها چطور از هم جدا میشود؟ اینجا وارد Multi-tenancy میشویم.
وقتی یک سیستم باید میزبان چند مشتری باشد
تا اینجا دربارهی طراحی سرویسها، ارتباط میان آنها، اجرای کانتینری، Serverless و زیرساخت قابل بازبینی حرف زدیم. حالا فرض کنیم محصول واقعاً رشد کرده است. دیگر فقط یک تیم یا یک سازمان از آن استفاده نمیکند. چند شرکت، چند مدرسه، چند فروشگاه یا چند مشتری سازمانی میخواهند از همان سامانه استفاده کنند.
در نگاه اول، شاید ساده به نظر برسد: همان سیستم را برای چند مشتری باز میکنیم. اما خیلی زود پرسشهای جدیتر پیدا میشوند. دادهی هر مشتری کجا نگهداری میشود؟ کاربران هر مشتری چطور از هم جدا میشوند؟ تنظیمات هر مشتری کجا ذخیره میشود؟ اگر یک مشتری پرترافیک شد، آیا روی بقیه اثر میگذارد؟ اگر یک query اشتباه نوشته شود، آیا ممکن است دادهی مشتری دیگری نمایش داده شود؟
اینجاست که مفهوم Multi-tenancy یا معماری چندمستاجری وارد داستان میشود. در این مدل، یک سامانه به چند tenant خدمت میدهد. tenant میتواند یک شرکت، سازمان، تیم، مدرسه، فروشگاه یا هر واحد مستقلی باشد که داده، کاربر، تنظیمات و مرزهای خودش را دارد.
Multi-tenancy یعنی یک سامانه بتواند به چند مشتری یا سازمان خدمت بدهد، بیآنکه مرز داده، دسترسی، تنظیمات و منابع آنها با هم قاطی شود.
سادهترین راه این است که برای هر مشتری یک نسخهی کامل و جدا از سیستم بالا بیاوریم. این کار از نظر جداسازی ذهنی سادهتر است، اما با زیاد شدن مشتریها هزینهی نگهداری بالا میرود: چند deployment، چند دیتابیس، چند تنظیم، چند migration، چند بکاپ و چند مسیر پایش. از آن طرف، اگر همهی مشتریها را روی یک سیستم کاملاً مشترک بیاوریم، هزینهی عملیاتی کمتر میشود، اما خطرها و پیچیدگیهای تازهای وارد میشود.
پس چندمستاجری یک انتخاب صفر و یکی نیست؛ یک طیف است. هرچه اشتراک منابع بیشتر شود، هزینه و عملیات ممکن است سادهتر شود، اما مسئولیت ما برای جلوگیری از نشت داده، اثرگذاری مشتریها روی هم و پیچیدگی مجوزها بیشتر میشود.
یکی از اولین جاهایی که این تصمیم خودش را نشان میدهد، مدل جداسازی داده است. سه مدل رایجتر را میشود اینطور دید:
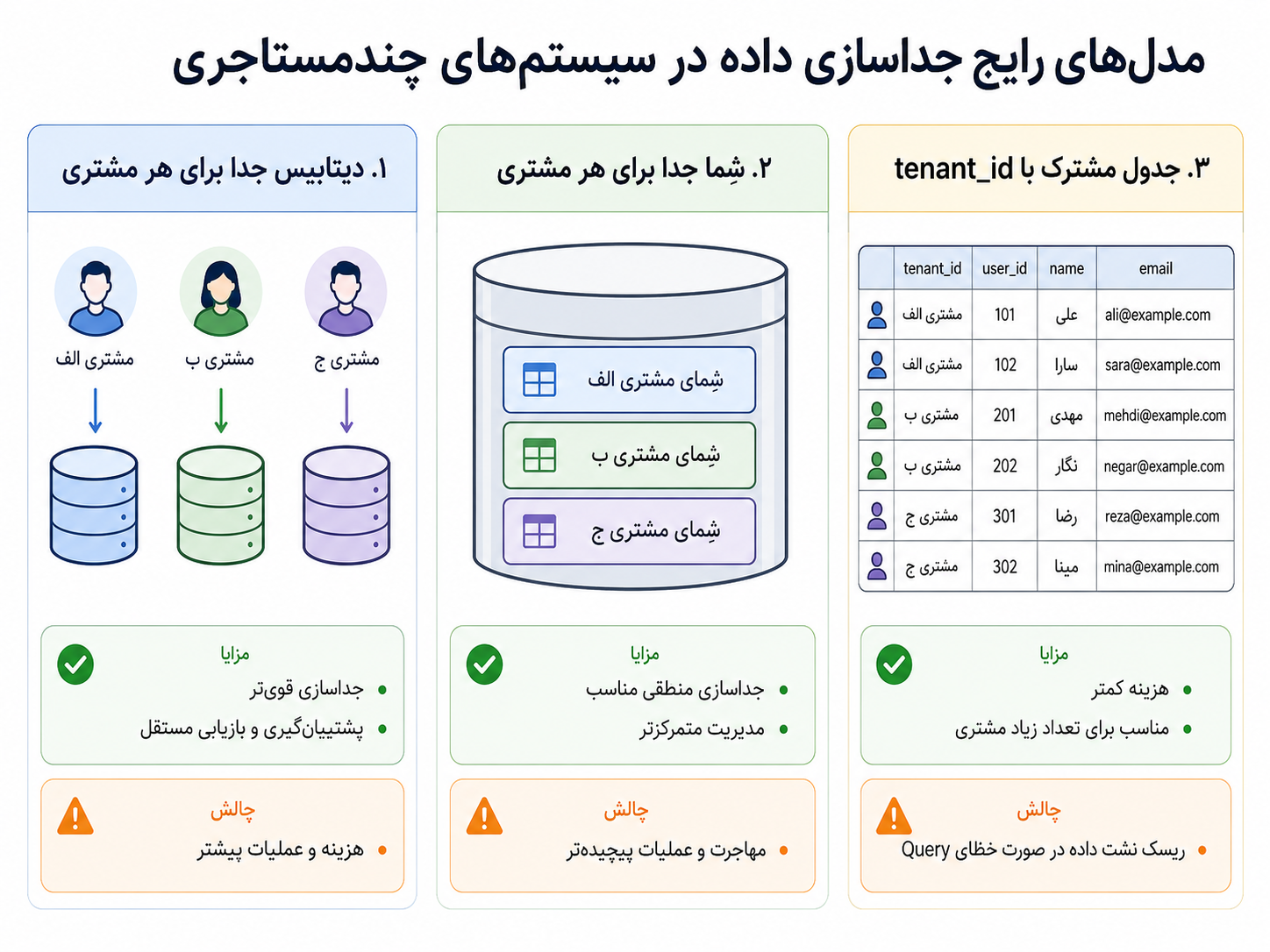
هر مدل، معاملهای میان هزینه، جداسازی، امنیت و پیچیدگی عملیاتی است.
| مدل | توضیح | مزیت | هزینه یا خطر |
|---|---|---|---|
| دیتابیس جدا برای هر tenant | هر مشتری دیتابیس خودش را دارد | جداسازی قویتر، بکاپ و بازیابی مستقلتر | هزینه و عملیات بیشتر |
| schema جدا برای هر tenant | همه روی یک دیتابیساند، اما schema جدا دارند | جداسازی منطقی مناسب، مدیریت متمرکزتر | migration و عملیات پیچیدهتر |
جدول مشترک با tenant_id | دادهها در جدولهای مشترکاند و با tenant_id جدا میشوند | هزینه کمتر و مناسبتر برای تعداد زیاد tenant | خطر نشت داده در صورت خطای query یا کنترل دسترسی |
هیچکدام از این مدلها «بهترین مطلق» نیستند. اگر دادهها بسیار حساساند، تعداد tenantها کم است و نیاز به بکاپ و بازیابی مستقل داریم، دیتابیس جدا میتواند منطقی باشد. اگر تعداد tenantها زیاد است و هزینهی عملیاتی باید کنترل شود، جدول مشترک با tenant_id شاید عملیتر باشد. گاهی هم مدل ترکیبی داریم: tenantهای معمولی روی منابع مشترکاند، اما tenantهای بزرگ یا حساس منابع جدا میگیرند.
اما مهمترین سوءبرداشت این است که فکر کنیم چندمستاجری فقط مسئلهی دیتابیس است. اضافه کردن tenant_id به جدولها شروع کار است، نه پایان آن. اگر cache با tenant جدا نشود، اگر فایلها در storage مسیر یا مالکیت روشن نداشته باشند، اگر log و metricها tenant-aware نباشند، یا اگر مجوزها درست اعمال نشوند، سیستم هنوز خطرناک است.
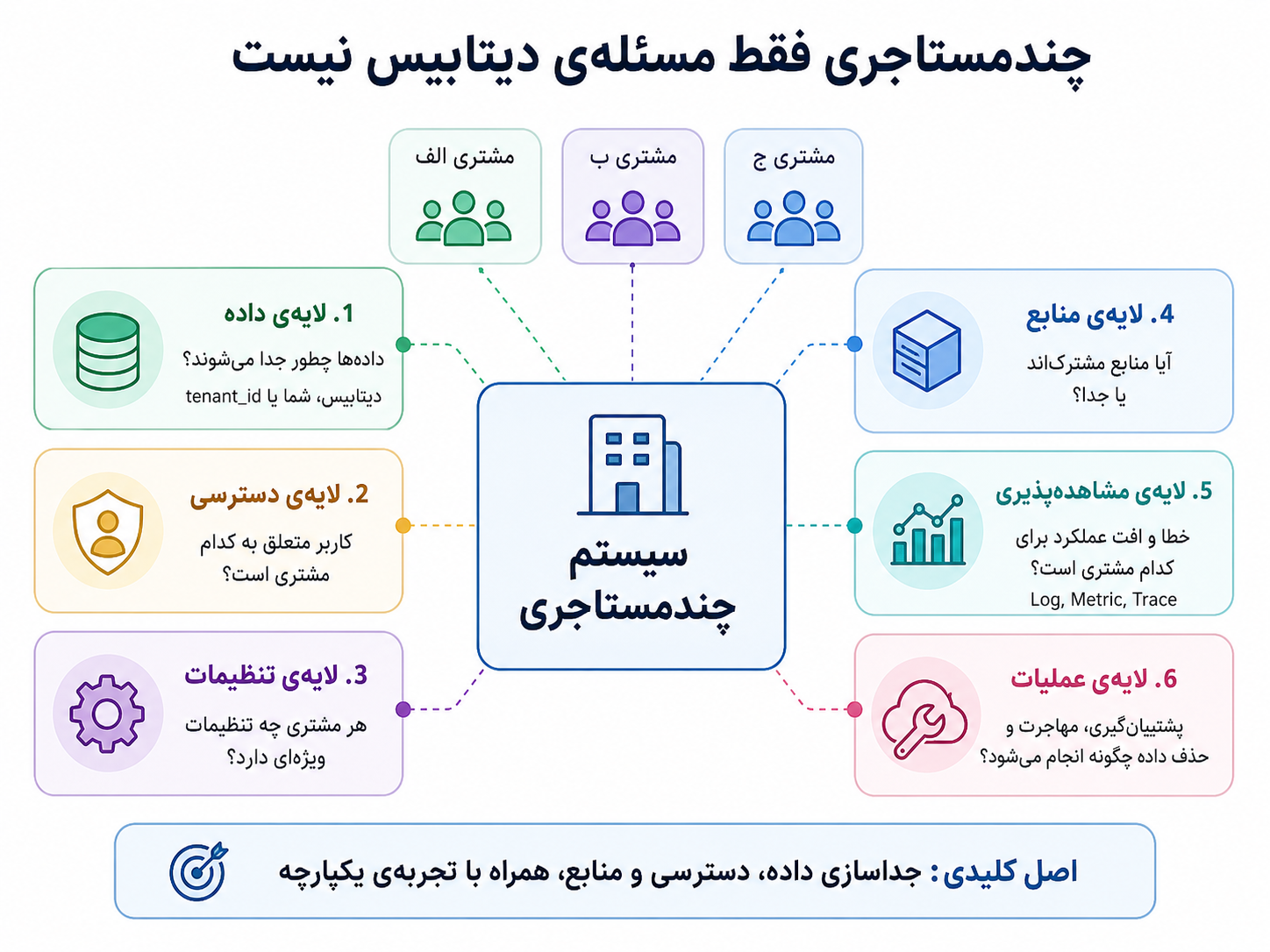
در سیستم چندمستاجری، جداسازی داده فقط یکی از لایههاست؛ دسترسی، تنظیمات، منابع، مشاهدهپذیری و عملیات هم باید tenant-aware باشند.
چندمستاجری را بهتر است در چند لایه ببینیم:
| لایه | پرسش اصلی |
|---|---|
| داده | دادهی tenantها چطور جدا میشود؟ دیتابیس جدا، schema جدا یا tenant_id؟ |
| دسترسی | کاربر از کجا معلوم است متعلق به کدام tenant است و چه مجوزی دارد؟ |
| تنظیمات | هر tenant چه تنظیمات ویژهای دارد و این تنظیمات کجا نگهداری میشود؟ |
| منابع | آیا همه از منابع مشترک استفاده میکنند یا بعضی tenantها منابع جدا دارند؟ |
| مشاهدهپذیری | وقتی خطا یا افت عملکرد رخ میدهد، میفهمیم مربوط به کدام tenant است؟ |
| عملیات | migration، بکاپ، حذف داده و بازیابی برای هر tenant چطور انجام میشود؟ |
یک مثال ساده بزنیم. فرض کنیم فروشگاه الف و فروشگاه ب هر دو از سامانهی ما استفاده میکنند. کاربر فروشگاه الف وارد پنل میشود و گزارش سفارشها را میبیند. اگر query گزارش فقط بر اساس تاریخ فیلتر کند و tenant را فراموش کند، ممکن است سفارشهای فروشگاه ب هم در نتیجه بیاید. این فقط یک bug معمولی نیست؛ در سیستم چندمستاجری، چنین خطایی میتواند فاجعهی اعتماد و امنیت باشد.
اضافه کردن tenant_id به جدولها یعنی Multi-tenancy حل شد؟ نه. باید مطمئن شویم همهی مسیرهای خواندن، نوشتن، cache، فایل، گزارش، log، metric، دسترسی و عملیات، مرز tenant را میشناسند و رعایت میکنند.
یکی از خطرهای مهم دیگر، مسئلهی همسایهی پرمصرف یا noisy neighbor است. وقتی چند tenant روی منابع مشترک اجرا میشوند، یک tenant پرترافیک میتواند منابع را مصرف کند و کیفیت سرویس tenantهای دیگر را پایین بیاورد. مثلاً یک مشتری گزارش سنگین میگیرد، صف پردازش را پر میکند یا تعداد زیادی درخواست همزمان میفرستد، و مشتریهای دیگر هم کندی را تجربه میکنند.
پس در سیستم چندمستاجری، عدالت منابع هم بخشی از طراحی است. ممکن است به rate limit، سهمیه، صف جدا، pool جدا، منابع اختصاصی برای مشتریهای بزرگ، یا اولویتبندی پردازش نیاز داشته باشیم. این تصمیمها فقط فنی نیستند؛ به قرارداد، مدل درآمدی و سطح سرویس وعدهدادهشده به مشتری هم ربط دارند.
فصل قبل دربارهی IaC و GitOps بود. در سیستم چندمستاجری، آن بحث دوباره مهم میشود: شاید برای tenantهای بزرگ دیتابیس جدا بسازیم، namespace جدا در Kubernetes بدهیم، یا تنظیمات و منابعشان را با کد و Git نگهداری کنیم. پس Multi-tenancy فقط در کد برنامه نیست؛ در زیرساخت و عملیات هم خودش را نشان میدهد.
انتخاب مدل چندمستاجری باید با چند معیار انجام شود: حساسیت داده، تعداد tenantها، نیاز به سفارشیسازی، هزینهی عملیات، الزامات حقوقی، نیاز به بکاپ و بازیابی مستقل، و توان تیم برای نگهداری سیستم. تیمی که تازه محصول را ساخته، شاید با مدل سادهتری شروع کند و بعد برای tenantهای خاص، جداسازی قویتری اضافه کند. اما اگر از ابتدا دادهها بسیار حساساند، سادهترین مدل مشترک شاید انتخاب خطرناکی باشد.
| پرسش تصمیمگیری | چرا مهم است؟ |
|---|---|
| دادهی tenantها چقدر حساس است؟ | حساسیت بالا معمولاً جداسازی قویتر میخواهد. |
| چند tenant داریم یا خواهیم داشت؟ | تعداد زیاد، عملیات مدلهای جداگانه را سختتر میکند. |
| هر tenant چقدر سفارشیسازی میخواهد؟ | تنظیمات زیاد، طراحی پیکربندی و استقرار را پیچیدهتر میکند. |
| آیا tenantهای بزرگ داریم؟ | شاید برای آنها منابع یا دیتابیس جدا لازم شود. |
| migration و بکاپ چطور انجام میشود؟ | با زیاد شدن tenantها، عملیات داده سختتر میشود. |
| آیا مشاهدهپذیری tenant-aware داریم؟ | بدون آن، عیبیابی و پاسخگویی به مشتری سخت میشود. |
چه زمانی مدل مشترک با tenant_id میتواند مناسب باشد؟
وقتی تعداد tenantها زیاد است، دادهها حساسیت بسیار بالا ندارند، تیم میتواند کنترل دسترسی و queryها را خوب مدیریت کند، و هزینهی عملیاتی باید پایین بماند، مدل مشترک با tenant_id میتواند انتخاب عملیتری باشد. البته این مدل نیاز به دقت جدی در queryها، cache، گزارشها و تستها دارد.
چه زمانی دیتابیس جدا برای هر tenant منطقیتر است؟
وقتی دادهها بسیار حساساند، مشتریها بزرگاند، بکاپ و بازیابی مستقل مهم است، یا الزام حقوقی و قراردادی برای جداسازی قویتر داریم، دیتابیس جدا میتواند گزینهی مناسبتری باشد. هزینهی عملیاتی این مدل بیشتر است، اما مرز داده روشنتر و مدیریت بعضی عملیاتها مستقلتر میشود.
برای من، Multi-tenancy یعنی پذیرفتن یک معاملهی مهم: میخواهیم تجربهای مشترک و قابل نگهداری بسازیم، اما نباید مرز مشتریها را ساده بگیریم. هرجا منابع را مشترک میکنیم، باید آگاهانهتر دربارهی امنیت، دسترسی، مصرف منابع، مشاهدهپذیری و عملیات فکر کنیم.
تا اینجا گفتیم یک سیستم چندمستاجری چطور داده و منابع چند مشتری را کنار هم نگه میدارد. اما همین انتخاب، فصل بعدی را سختتر میکند: وقتی ساختار داده تغییر میکند، migration دیگر فقط تغییر چند جدول در یک دیتابیس نیست. شاید باید تغییر را روی چند دیتابیس، چند schema یا میلیونها ردیف دارای tenant_id اجرا کنیم. اینجاست که وارد Data Migration میشویم.
وقتی دادهها هم اسبابکشی دارند
در فصل قبل گفتیم وقتی یک سیستم چندمستاجری میشود، دادهی چند مشتری، سازمان یا گروه کاربری در کنار هم مدیریت میشود. حالا تصور کنیم محصول رشد کرده و یک تغییر ظاهراً ساده از راه میرسد: تیم محصول میخواهد فیلد آدرس دقیقتر شود؛ شهر، استان و کدپستی جدا شوند. یا تیم فنی میگوید جدول کاربران باید بازطراحی شود. یا تیم مالی میخواهد وضعیت تراکنشها از یک مقدار کلی به چند وضعیت دقیقتر تبدیل شود.
در نگاه اول، اینها فقط تغییر دیتابیساند: یک ستون اضافه کن، یک جدول بساز، چند داده را جابهجا کن، ستون قدیمی را حذف کن. اما در سیستم واقعی، داده زنده است. کاربرها همزمان در حال استفادهاند، سرویسها به جدولها وابستهاند، گزارشها از داده میخوانند، workerها در پسزمینه چیزی مینویسند، و در سیستم چندمستاجری شاید همین تغییر باید برای چند tenant، schema یا دیتابیس اجرا شود.
اینجاست که Data Migration یا مهاجرت داده وارد داستان میشود. مهاجرت داده فقط جابهجایی چند ردیف نیست؛ یعنی تغییر دادن ساختار، محل یا معنای داده، بدون اینکه اعتماد سیستم به دادهها از بین برود.
Data Migration یعنی دادهی زنده را از یک وضعیت به وضعیت دیگر ببریم، بیآنکه صحت، معنا، دسترسپذیری و اعتماد به داده قربانی شود.
یک مثال ساده را در نظر بگیریم. در جدول users قبلاً فقط یک ستون full_name داشتیم. حالا میخواهیم آن را به first_name و last_name تبدیل کنیم. اگر در یک حرکت ستون قدیمی را حذف کنیم و کد جدید را منتشر کنیم، ممکن است نسخههای قدیمیتر کد هنوز full_name بخواهند. ممکن است بعضی دادهها درست تفکیک نشوند. ممکن است گزارشها هنوز به ستون قدیمی وابسته باشند. اگر جدول بزرگ باشد، تغییر یکباره حتی میتواند باعث قفل شدن جدول یا اختلال در سرویس شود.
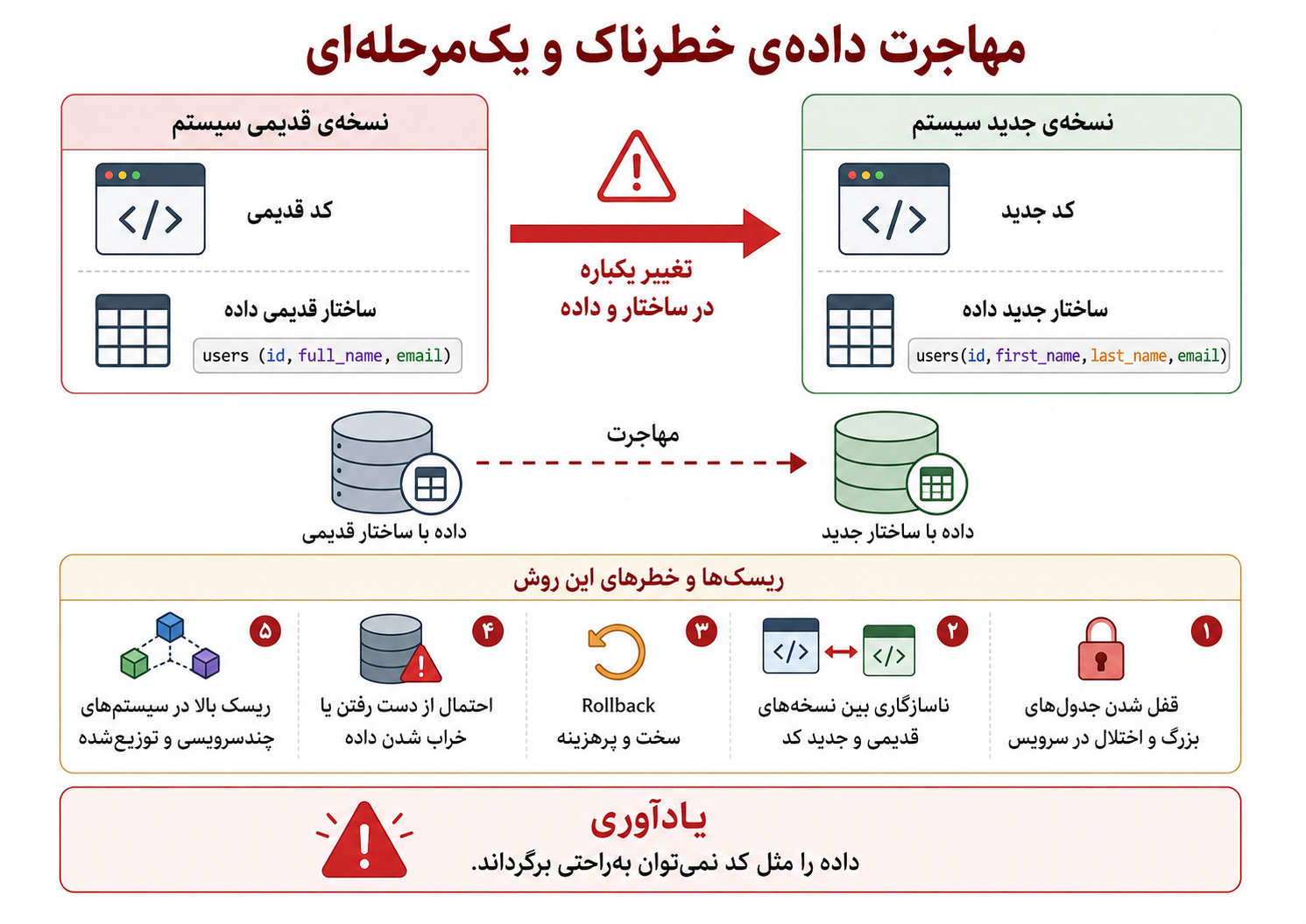
در مهاجرت یکمرحلهای، فرض میکنیم کد، داده و همهی سرویسها همزمان و بیخطا تغییر میکنند؛ در سیستم واقعی این فرض معمولاً خطرناک است.
مهاجرت داده شکلهای مختلفی دارد. گاهی ساختار جدول عوض میشود، گاهی خود دادهها تبدیل میشوند، و گاهی معنای یک مقدار تغییر میکند. سختترین حالت معمولاً همان تغییر معناست، چون خطایش همیشه سریع دیده نمیشود.
| نوع تغییر | مثال | خطر اصلی |
|---|---|---|
| تغییر ساختار | اضافه کردن ستون، ساخت جدول جدید، تغییر نوع ستون | ناسازگاری کد و دیتابیس |
| تغییر داده | پر کردن مقدار جدید، انتقال داده بین جدولها، backfill | دادهی ناقص، فشار روی دیتابیس یا خطای تبدیل |
| تغییر معنا | تبدیل canceled به canceled_by_user و canceled_by_system | خطای پنهان در گزارشها و منطق کسبوکار |
نکتهی مهم این است که migration فقط ALTER TABLE نیست. ممکن است یک migration از نظر دیتابیس ساده باشد، اما از نظر محصولی پیچیده شود. اگر معنای یک وضعیت تغییر کند، باید گزارشها، داشبوردها، APIها، تستها، مستندات و حتی زبان تیم محصول هم با آن تغییر هماهنگ شوند.
راه امنتر معمولاً این است که migration را به یک فرایند مرحلهای تبدیل کنیم؛ نه یک تغییر ناگهانی. یکی از الگوهای رایج برای این کار، الگوی گسترش، پرکردن و جمعکردن است؛ همان چیزی که گاهی با نام Expand → Backfill → Contract شناخته میشود.
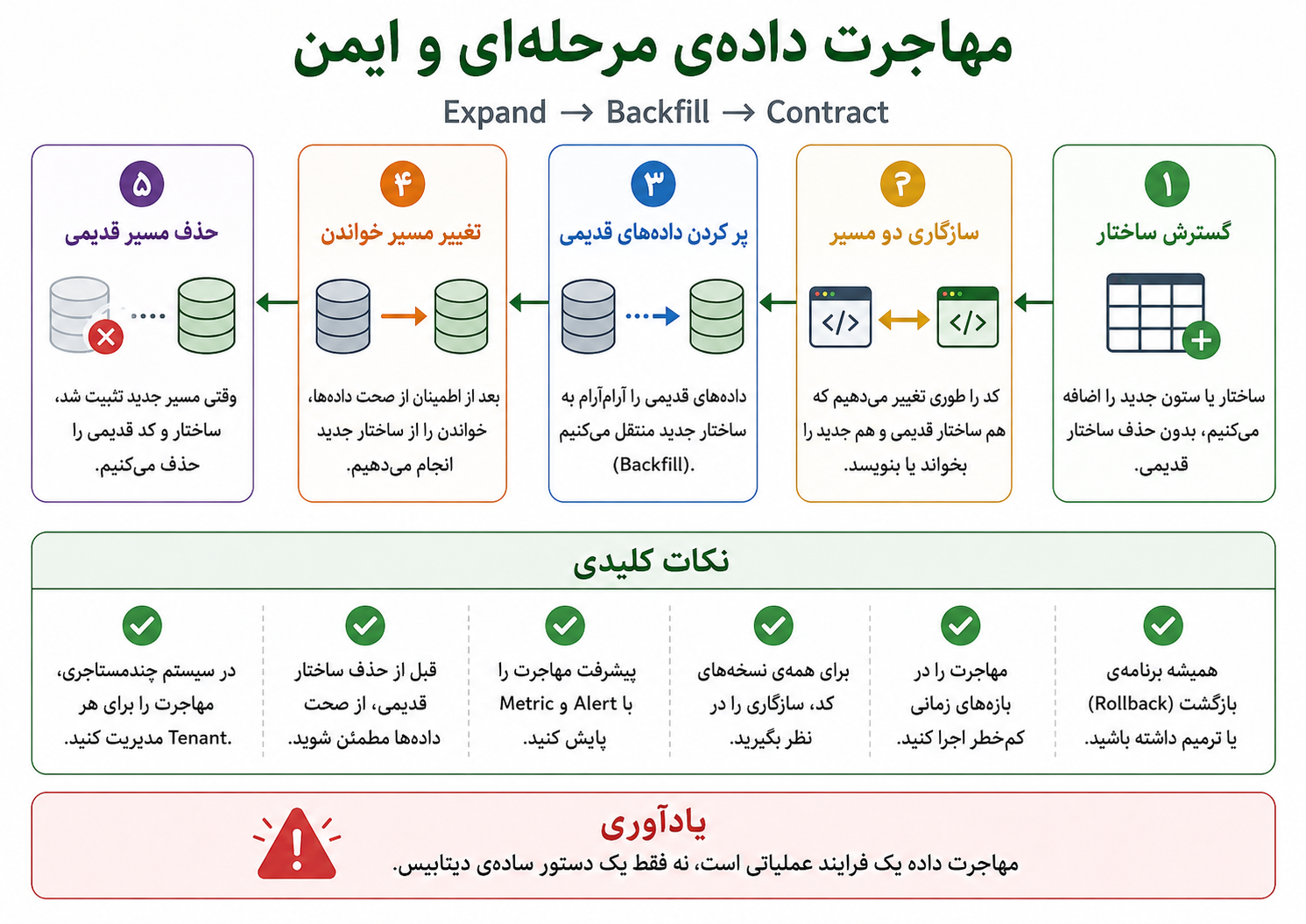
در مهاجرت مرحلهای، ابتدا مسیر جدید را بدون شکستن مسیر قدیمی اضافه میکنیم، بعد دادهها را آرامآرام منتقل میکنیم، و فقط وقتی مطمئن شدیم مسیر جدید پایدار است، مسیر قدیمی را حذف میکنیم.
در مثال full_name، مسیر امنتر میتواند این باشد:
- ستونهای
first_nameوlast_nameرا اضافه کنیم، بدون حذفfull_name. - کد را طوری تغییر دهیم که بتواند با هر دو ساختار کنار بیاید.
- دادههای قدیمی را تدریجی و در batchهای کوچک به ساختار جدید منتقل کنیم.
- مدتی خواندن و نوشتن را پایش کنیم و مطمئن شویم دادههای جدید درستاند.
- خواندن اصلی را از ساختار جدید انجام دهیم.
- بعد از اطمینان، مسیر قدیمی را حذف کنیم.
در سیستمهای واقعی، تغییر داده را بهتر است یک deploy ساده نبینیم. گاهی باید چند نسخه از کد و دیتابیس برای مدتی با هم سازگار بمانند تا بتوانیم بدون قطعی و با ریسک کمتر مهاجرت کنیم.
اینجا دوباره بحث سازگاری نسخهها مهم میشود. کد جدید باید بتواند با دادهی قدیمی کنار بیاید. کد قدیمی هم ممکن است برای مدتی با schema جدید کار کند. اگر چند سرویس داریم که همزمان deploy نمیشوند، migration نباید فرض کند همهی آنها همزمان به نسخهی جدید رفتهاند. اضافه کردن یک ستون معمولاً امنتر از rename یا حذف ستون است، چون کد قدیمی معمولاً از اضافه شدن ستون جدید نمیشکند؛ اما حذف و تغییرهای مخرب باید با احتیاط و مرحلهای انجام شوند.
در سیستم چندمستاجری، migration پیچیدهتر هم میشود. اگر مدل ما جدول مشترک با tenant_id است، migration روی جدولهای بزرگ و مشترک اجرا میشود و باید مراقب فشار روی کل سیستم باشیم. اگر schema جدا برای هر tenant داریم، migration باید روی چند schema اجرا و پایش شود. اگر دیتابیس جدا برای هر tenant داریم، باید بدانیم کدام tenant مهاجرت شده، کدام نشده، و اگر یکی شکست خورد، چه میکنیم.
در سیستم چندمستاجری، migration یک کار عملیاتی هم هست: باید بدانیم تغییر برای کدام tenant اجرا شده، کدام tenant خطا داده، آیا میتوانیم tenantها را مرحلهای مهاجرت دهیم، و اگر یک tenant مشکل داشت، چطور جلوی اثرگذاری روی بقیه را بگیریم.
یکی از اشتباههای خطرناک این است که migration را در ساعت اوج و بدون مشاهدهپذیری اجرا کنیم. اگر backfill روی جدول بزرگ بدون محدودیت اجرا شود، میتواند دیتابیس را تحت فشار بگذارد. اگر جدول قفل شود، سرویس کند یا از دسترس خارج میشود. اگر metric و alert نداشته باشیم، شاید دیر بفهمیم دادهها ناقص منتقل شدهاند.
چند پرسش مهم پیش از اجرای migration:
| پرسش | چرا مهم است؟ |
|---|---|
| آیا نسخههای قدیمی و جدید کد با schema جدید سازگارند؟ | سرویسها همیشه همزمان deploy نمیشوند. |
| آیا migration روی جدول بزرگ lock ایجاد میکند؟ | قفل شدن جدول میتواند سرویس را مختل کند. |
| آیا backfill قابل توقف و ادامه دادن است؟ | migration طولانی ممکن است وسط کار شکست بخورد. |
| آیا progress و خطاها را metric و alert میکنیم؟ | بدون مشاهدهپذیری، migration کورکورانه است. |
| آیا backup، rollback یا برنامهی ترمیم داریم؟ | داده را مثل کد همیشه راحت نمیشود برگرداند. |
| در سیستم چندمستاجری، وضعیت هر tenant معلوم است؟ | ممکن است بعضی tenantها مهاجرت شده باشند و بعضی نه. |
اگر deploy بد باشد، معمولاً میتوانیم نسخهی قبلی کد را برگردانیم. اما اگر migration داده را خراب کند، rollback همیشه ساده نیست. گاهی باید داده را ترمیم کنیم، نه فقط کد را عقب ببریم.
چه زمانی migration یکمرحلهای قابل قبولتر است؟
اگر سیستم هنوز کوچک است، جدولها کمحجماند، فقط یک سرویس به داده وابسته است، downtime کوتاه قابل قبول است و backup روشن داریم، migration یکمرحلهای ممکن است کافی باشد. اما با بزرگ شدن داده، زیاد شدن سرویسها و حساستر شدن محصول، این روش پرریسکتر میشود.
چه زمانی migration مرحلهای ضروریتر میشود؟
وقتی داده زیاد است، سرویسها متعددند، deployها همزمان نیستند، downtime قابل قبول نیست، یا چند tenant داریم، migration مرحلهای معمولاً انتخاب امنتری است. در این حالت باید سازگاری نسخهها، backfill تدریجی، پایش پیشرفت و برنامهی ترمیم را جدی بگیریم.
برای من، Data Migration یعنی پذیرفتن این واقعیت که داده، برخلاف کد، فقط با برگشتن به commit قبلی درست نمیشود. داده تاریخچه دارد، معنا دارد، مشتری دارد و خطای آن میتواند در گزارشها، تصمیمهای کسبوکار و اعتماد کاربر باقی بماند. پس migration خوب بیشتر از آنکه یک دستور دیتابیس باشد، یک فرایند فنی و عملیاتی است.
وقتی migration را مرحلهای، قابل مشاهده و قابل ترمیم طراحی میکنیم، در واقع قبول کردهایم که سیستم واقعی همیشه در معرض تغییر و ریسک است. اما آیا کافی است فقط امیدوار باشیم که همهچیز درست کار کند؟ یا میتوانیم آگاهانه سیستم را در برابر خطاها، قطعیها و رفتارهای غیرمنتظره آزمایش کنیم؟ این پرسش ما را به Chaos Engineering میرساند.
وقتی خرابی اتفاق بد نیست؛ ناآمادگی بد است
تا اینجا سیستم ما بزرگ و واقعیتر شده است. سرویسها از هم جدا شدهاند، پیام و صف و رخداد داریم، دادهها مهاجرت میکنند، زیرساخت با کد مدیریت میشود و شاید چند tenant هم روی یک سامانه زندگی میکنند. اما یک پرسش هنوز باقی است: وقتی بخشی از این سیستم خراب شود، واقعاً میدانیم چه اتفاقی میافتد؟ یا فقط امیدواریم که همهچیز خوب کار کند؟
خیلی از سیستمها در روزهای عادی سالم به نظر میرسند. نمودارها سبز هستند، سرویسها پاسخ میدهند و کاربران شکایت خاصی ندارند. اما کافی است یک سرویس کمی کند شود، یک وابستگی بیرونی خطا بدهد، یک نمونه از سرویس سفارش از مدار خارج شود، یا ارتباط با cache برای چند دقیقه قطع شود. آن وقت ممکن است زنجیرهای از خطاها شروع شود؛ خطاهایی که تا قبل از حادثه، فقط در ذهن ما «نباید اتفاق میافتادند».
Chaos Engineering از همین نقطه شروع میشود: بهجای اینکه فقط منتظر خرابی واقعی بمانیم، خرابیهای محتمل را در اندازهی کوچک، کنترلشده و قابل مشاهده تمرین کنیم تا ضعفها را زودتر پیدا کنیم.
Chaos Engineering یعنی طراحی و اجرای آزمایشهای کنترلشده برای فهمیدن اینکه سیستم در برابر خرابیهای واقعی چقدر تابآور است. هدف خراب کردن سیستم نیست؛ هدف کم کردن غافلگیری در روز حادثه است.
این ایده بیش از همه با Netflix معروف شد. وقتی Netflix روی AWS و معماری ابری توزیعشده کار میکرد، با واقعیتی روبهرو بود که برای خیلی از سیستمهای امروزی هم آشناست: خرابی ماشین، شبکه، وابستگی بیرونی یا بخشی از زیرساخت اتفاقی عجیب و نادر نیست؛ بخشی از زندگی روزمرهی سیستمهای توزیعشده است. Netflix حدود سال ۲۰۱۱ ابزاری به نام Chaos Monkey ساخت؛ ابزاری که بهصورت کنترلشده بعضی instanceها را از مدار خارج میکرد تا تیمها مجبور شوند سیستمهایی بسازند که با خرابی یک نمونه از پا نیفتند. بعدتر این ایده در قالب ابزارها و روشهای بیشتری رشد کرد و Chaos Engineering به یک رویکرد مهندسی برای آزمودن تابآوری تبدیل شد.
ایده این نیست که سیستم را بیهدف خراب کنیم؛ ایده این است که خرابیهای قابل انتظار را قبل از روز حادثه، کنترلشده تمرین کنیم.
البته خود ایدهی تمرین خرابی از هیچ جا ناگهان ظاهر نشد. پیش از این هم تیمها تمرینهای بازیابی از فاجعه، مانورهای عملیاتی و تستهای تابآوری داشتند. تفاوت مهم این بود که Netflix این نگاه را در فضای سرویسهای ابری و توزیعشده بسیار ملموس کرد: اگر میدانیم خرابی بخشی از واقعیت است، پس باید آن را به شکل کنترلشده وارد فرایند یادگیری سیستم کنیم.
اما همینجا باید یک سوءبرداشت خطرناک را کنار بگذاریم. Chaos Engineering یعنی «خرابکاری تصادفی»؟ نه. یعنی تیمی بدون آمادگی برود production را بلرزاند تا ببیند چه میشود؟ قطعاً نه. Chaos Engineering درست، فرضیهمحور است: اول میگوییم انتظار داریم سیستم در یک شرایط مشخص چه رفتاری داشته باشد، بعد یک اختلال محدود و قابل توقف وارد میکنیم، و در نهایت نتیجه را با معیارهای روشن میسنجیم.
مثلاً فرضیه میتواند این باشد: «اگر یکی از نمونههای سرویس سفارش از مدار خارج شود، کاربر نباید خطای محسوس ببیند و ترافیک باید به نمونههای سالم منتقل شود.» بعد آزمایش را در محدودهای کوچک اجرا میکنیم، نرخ خطا، تأخیر، تعداد درخواستهای ناموفق و رفتار alertها را میبینیم، و اگر وضعیت از حد امن خارج شد، آزمایش را متوقف میکنیم.
یک آزمایش درست در Chaos Engineering با فرضیه شروع میشود، محدودهی اثر دارد، قابل مشاهده است، شرط توقف دارد و در نهایت به یادگیری و اصلاح منجر میشود.
چند مفهوم پایه در این مسیر مهماند:
| مفهوم | توضیح ساده |
|---|---|
| Steady State | وضعیت عادی و سالم سیستم که انتظار داریم حفظ شود |
| Hypothesis | فرضیهای که میخواهیم آزمایش کنیم |
| Fault Injection | وارد کردن خطای کنترلشده؛ مثل قطع یک instance یا افزایش تأخیر |
| Blast Radius | محدودهی اثر آزمایش؛ یعنی اگر بد شد، چقدر آسیب میزند |
| Abort Condition | شرط توقف آزمایش |
| Game Day | تمرین برنامهریزیشده برای آزمودن واکنش سیستم و تیم به حادثه |
نمونههای سادهی آزمایش میتواند اینها باشد: حذف یک pod در Kubernetes، خاموش کردن یک نمونه از سرویس سفارش، افزایش تأخیر بین سرویس پرداخت و سفارش، قطع موقت دسترسی به cache، کند کردن یک read replica، پر شدن دیسک یک worker، یا خطای موقت در سرویس ارسال پیامک. در سناریوهای پیشرفتهتر شاید دربارهی از دسترس خارج شدن یک availability zone هم فکر کنیم؛ اما شروع عاقلانه معمولاً از آزمایشهای کوچکتر است، نه از بزرگترین فاجعهی ممکن.
Chaos Engineering خوب معمولاً با آزمایشهای کوچک، قابل توقف و کمخطر شروع میشود. لازم نیست روز اول یک ناحیهی ابری را از مدار خارج کنیم. اول باید مطمئن شویم مشاهدهپذیری، alert، rollback، مالکیت سرویس و واکنش تیم قابل اتکا هستند.
حالا نقد مهم: چرا خیلی از تیمها Chaos Engineering انجام نمیدهند؟ همیشه هم از تنبلی یا عقبماندگی نیست. گاهی انجام ندادن آن تصمیم درستی است، چون پیشنیازهایش فراهم نیست. اگر metric، log، trace و alert درست نداریم، وارد کردن خطا فقط کور کردن خودمان است. اگر rollback و runbook نداریم، آزمایش خرابی ممکن است خودش حادثه شود. اگر تیم هنوز مالکیت سرویسها را روشن نکرده، معلوم نیست هنگام آزمایش چه کسی باید تصمیم بگیرد.
| دلیل انجام ندادن | چرا قابل فهم است؟ |
|---|---|
| مشاهدهپذیری ضعیف | بدون metric و alert، نتیجهی آزمایش قابل اعتماد نیست. |
| نبود برنامهی برگشت | اگر آزمایش بد پیش برود، باید راه توقف و ترمیم داشته باشیم. |
| فشار محصولی | تیمی که زیر فشار تحویل ویژگی است، سخت برای تمرین تابآوری زمان میگذارد. |
| فرهنگ سازمانی نامناسب | بعضی سازمانها آزمایش کنترلشدهی خطا را با بیاحتیاطی یکی میگیرند. |
| سیستم هنوز ساده است | برای بعضی سیستمهای کوچک، تستهای معمولی و پایش ساده کافیتر است. |
| نبود مالکیت روشن | اگر معلوم نیست مالک هر سرویس کیست، آزمایش حادثهمحور خطرناک میشود. |
بنابراین نباید Chaos Engineering را مثل مدال افتخار معرفی کنیم. این کار زمانی ارزشمند است که روی پایههای درست سوار شود: مشاهدهپذیری، مدیریت حادثه، تستهای معمولی، برنامهی برگشت، مالکیت سرویس و فرهنگ یادگیری بدون مقصرسازی.
اگر تیم هنوز مشاهدهپذیری، rollback، runbook و واکنش روشن به حادثه ندارد، Chaos Engineering اولویت اول نیست. در چنین شرایطی، تزریق خطا میتواند بیشتر شلوغکاری و خطر باشد تا مهندسی.
خود Chaos Engineering هم اگر بد اجرا شود، چند خطر دارد. یکی اعتماد کاذب است: چند آزمایش ساده موفق میشود و تیم فکر میکند سیستم واقعاً تابآور است. دیگری آسیب واقعی است: آزمایش بدون محدوده و شرط توقف، خودش outage میسازد. خطر سوم هم نمایش مهندسی است؛ یعنی تیم بهجای حل بدهیهای معلوم، یک نمایش جذاب از «ما chaos داریم» اجرا میکند.
چند پرسش خوب پیش از هر آزمایش:
| پرسش | چرا مهم است؟ |
|---|---|
| فرضیهی ما دقیقاً چیست؟ | بدون فرضیه، آزمایش بیشتر کنجکاوی خطرناک است. |
| وضعیت سالم سیستم را چطور میسنجیم؟ | باید بدانیم چه چیزی نباید خراب شود. |
| محدودهی اثر چقدر است؟ | آزمایش باید blast radius کنترلشده داشته باشد. |
| چه زمانی آزمایش را متوقف میکنیم؟ | شرط توقف باید قبل از اجرا روشن باشد. |
| چه کسی تصمیمگیر و پاسخگوست؟ | در زمان اختلال، مالکیت مبهم خطرناک است. |
| بعد از آزمایش چه چیزی تغییر میکند؟ | اگر یادگیری به اصلاح نرسد، آزمایش ارزش کمی دارد. |
چه زمانی Chaos Engineering ارزشمندتر میشود؟
وقتی سیستم توزیعشده است، وابستگیهای بیرونی دارد، چند سرویس و چند تیم درگیرند، downtime پرهزینه است، و تیم زیرساخت مشاهدهپذیری و واکنش به حادثهی قابل قبول دارد، Chaos Engineering میتواند ضعفهای پنهان را پیش از حادثهی واقعی آشکار کند.
چه زمانی بهتر است فعلاً سراغش نرویم؟
اگر هنوز تستهای پایه، alertهای قابل اعتماد، runbook، rollback، backup، مالکیت سرویسها و فرهنگ پاسخگویی به حادثه نداریم، بهتر است اول همان پایهها را بسازیم. Chaos Engineering نباید جایگزین کارهای پایه شود.
برای من، Chaos Engineering یعنی صادق بودن با واقعیت سیستمهای واقعی: خرابی رخ میدهد. سؤال این نیست که آیا چیزی خراب میشود یا نه؛ سؤال این است که آیا پیش از کاربر و پیش از بحران، رفتار سیستم را در برابر خرابی فهمیدهایم یا نه. اگر این کار با فرضیه، محدوده، مشاهدهپذیری و یادگیری انجام شود، میتواند سیستم و تیم را بالغتر کند. اگر بدون این پایهها انجام شود، فقط اسم شیکتری برای خطر ساختن است.
تا اینجا بیشتر دربارهی سیستمهای فنی و تابآوری آنها حرف زدیم. اما بعضی پیچیدگیها نه فقط از خرابی فنی، بلکه از فرایندهای انسانی و سازمانی میآیند: درخواستها، تأییدها، گردش کارها، نقشها و وضعیتهایی که باید بین چند نفر و چند سیستم جابهجا شوند. اینجا وارد Business Process Management Systems یا BPMS میشویم.
وقتی همهچیز قرار نیست با کدنویسی کامل ساخته شود
بعد از این همه بحث دربارهی سرویسها، زیرساخت، مهاجرت داده، چندمستاجری و تابآوری، یک سؤال ساده اما مهم پیش میآید: آیا هر نیاز نرمافزاری باید با همین وزن مهندسی ساخته شود؟ آیا برای هر فرم داخلی، داشبورد سبک، اتوماسیون کوچک، پنل عملیاتی یا اتصال ساده بین دو ابزار، باید یک پروژهی نرمافزاری کامل تعریف کنیم؟
در خیلی از سازمانها، تیمهای مختلف نیازهای کوچک اما واقعی دارند. تیم فروش یک فرم ثبت سرنخ میخواهد. تیم مالی یک گزارش هزینه میخواهد. تیم عملیات یک داشبورد وضعیت میخواهد. پشتیبانی میخواهد وقتی یک رخداد تکراری اتفاق افتاد، پیام خودکار بفرستد. منابع انسانی یک فرم درخواست مرخصی یا فرایند سادهی تأیید میخواهد. اگر همهی این درخواستها وارد صف تیم مهندسی شود، کمکم تیم فنی به گلوگاه سازمان تبدیل میشود.
گاهی مسئله این نیست که تیم مهندسی کند است؛ مسئله این است که هر نیاز کوچک و داخلی هم به همان مسیر سنگین توسعهی نرمافزار فرستاده میشود.
Low-code و No-code از همین درد تغذیه میکنند. وعدهی آنها جذاب است: سریعتر بساز، کمتر کد بزن، تیمهای غیرمهندسی را توانمندتر کن، و همهچیز را برای یک فرم، داشبورد یا اتوماسیون کوچک از صفر نساز. اما همینجا باید مراقب باشیم؛ این بخش قرار نیست تبلیغ ابزار باشد. Low-code/No-code هم میتواند کمک کند، هم میتواند در بلندمدت سیستم را کندتر، مبهمتر و شکنندهتر کند.
Low-code/No-code یعنی ساخت بخشی از نرمافزارها، فرمها، داشبوردها، اتوماسیونها یا ابزارهای داخلی با کدنویسی کم یا بدون کدنویسی سنتی. اما «کد کمتر» به معنی «مسئولیت مهندسی کمتر» نیست.
ایدهی ساختن ابزار بدون کدنویسی کامل، چیز تازهای نیست. سالها قبل از اینکه اصطلاح Low-code/No-code مد شود، آدمها با صفحهگستردهها، Microsoft Access، ماکروها، فرمسازها و ابزارهای گزارشگیری تلاش میکردند کارهای روزمرهی خودشان را بدون ساختن یک نرمافزار کامل جلو ببرند. یعنی میل به اینکه «کاربر غیرمهندس هم بتواند چیزی بسازد» قدیمیتر از اسمهای امروزی است.
بعدتر، ابزارهای سریعساز برنامه، فرمسازها، ابزارهای اتوماسیون، پلتفرمهای ساخت اپلیکیشن داخلی و سکوهای اتصال بین سرویسها جدیتر شدند. امروز این فضا گستردهتر شده است: ابزارهایی مثل Retool، Airtable، AppSheet، Power Apps، Zapier، Make و n8n هرکدام از زاویهای کمک میکنند فرم، داشبورد، پنل داخلی، جریان خودکار یا اتصال میان سرویسها سریعتر ساخته شود.
n8n مثال خوبی است، چون نشان میدهد Low-code/No-code فقط فرمساز نیست. n8n بیشتر در دستهی اتوماسیون جریان کار قرار میگیرد: میتوانیم چند سرویس را به هم وصل کنیم، وبهوک بگیریم، بر اساس زمانبندی کاری اجرا کنیم، داده را از یک ابزار به ابزار دیگر بفرستیم، پیام Telegram یا Slack ارسال کنیم، یا یک API داخلی را صدا بزنیم. مثلاً وقتی یک فرم پر شد، داده وارد CRM شود، یک پیام برای تیم فروش برود، یک وبهوک داخلی صدا زده شود، و در پایان ایمیل تأیید ارسال شود.
اینها واقعاً میتوانند مفید باشند. برای ساخت نمونهی اولیه، ابزار داخلی کمریسک، اتوماسیونهای سبک، داشبوردهای عملیاتی و کارهای تکراری، Low-code/No-code میتواند سرعت سازمان را بالا ببرد. تیم مهندسی هم به جای ساختن دهها ابزار کوچک و کمریسک، روی هستهی محصول، معماری و مسائل سختتر تمرکز میکند.
اما نیمهی تاریک ماجرا همینجاست. چیزی که امروز به اسم میانبر ساخته میشود، فردا ممکن است تبدیل شود به زیرساخت نامرئی سازمان. یک جریان ساده در n8n، یک فرم در Airtable، یک پنل در Retool یا چند اتوماسیون در Zapier اول کار کمک میکند؛ اما کمکم همانها میشوند مسیر اصلی ثبت درخواست، ارسال پیام به مشتری، تأیید مالی، تغییر وضعیت سفارش، گزارش مدیریتی یا اتصال بین دو سیستم مهم. آن وقت دیگر با یک ابزار ساده طرف نیستیم؛ با یک سیستم تولیدی طرفیم که فقط مثل سیستم تولیدی با آن رفتار نشده است.

روی سطح، چند جریان سریع و تمیز میبینیم؛ زیر سطح، ممکن است منطق پخششده، مالکیت مبهم، دسترسیهای زیاد، نبود تست و بدهی نامرئی شکل گرفته باشد.
نقد ما اصل این ابزارها نیست؛ نقد ما استفادهی بیمالکیت و بیچرخهی عمر از آنهاست. نقد تند اینجاست: این ابزارها اغلب کار را از تیم مهندسی کم نمیکنند؛ کار را از جلوی چشم تیم مهندسی پنهان میکنند. در کوتاهمدت صف مهندسی را دور میزنند، اما در بلندمدت صف تازهای میسازند: صف فهمیدن اینکه چه کسی کجا چه چیزی ساخته، چرا خراب شده، به چه دادهای دسترسی دارد، کدام جریان منطق اصلی کسبوکار را اجرا میکند، و اگر ابزار از کار افتاد چه کسی باید پاسخگو باشد.
مشکل Low-code/No-code این نیست که «کد کم دارد»؛ مشکل وقتی شروع میشود که «مسئولیت مهندسی» هم کمکم حذف شود. هر چیزی که در مسیر واقعی کسبوکار قرار میگیرد، نرمافزار است؛ حتی اگر با کشیدن چند گره ساخته شده باشد. اگر آن چیز مشتری را تحت تأثیر قرار میدهد، دادهی حساس میخواند، پول جابهجا میکند، وضعیت سفارش را تغییر میدهد یا فرایند روزانهی تیمی را پیش میبرد، دیگر نمیتوان با آن مثل یک فایل موقت برخورد کرد.
در n8n و ابزارهای مشابه، خطر اصلی این نیست که جریان ساختهایم؛ خطر این است که جریان تبدیل به منطق کسبوکار شده، اما هنوز با آن مثل یک آزمایش کوچک برخورد میکنیم. این جریانها معمولاً مجوز و اطلاعات اتصال دارند، به APIهای مختلف وصل میشوند، داده جابهجا میکنند و گاهی تصمیمهای مهم میگیرند. اگر مالکیت، کنترل دسترسی، نسخهبندی، پشتیبانگیری، پایش و هشدار نداشته باشند، یک گره کوچک، یک مجوز منقضیشده یا یک تغییر در API بیرونی میتواند یک فرایند مهم را بخواباند.
پس اگر قرار است Low-code/No-code وارد سازمان شود، باید با حاکمیت و مرز روشن وارد شود. باید معلوم باشد چه کسی مالک هر جریان یا ابزار است، چه دادهای خوانده میشود، چه دسترسیهایی داده شده، تغییرات چطور بازبینی میشوند، خطاها کجا دیده میشوند، و چه زمانی یک ابزار داخلی باید از حالت موقت خارج شود و به سیستم جدیتر تبدیل شود.
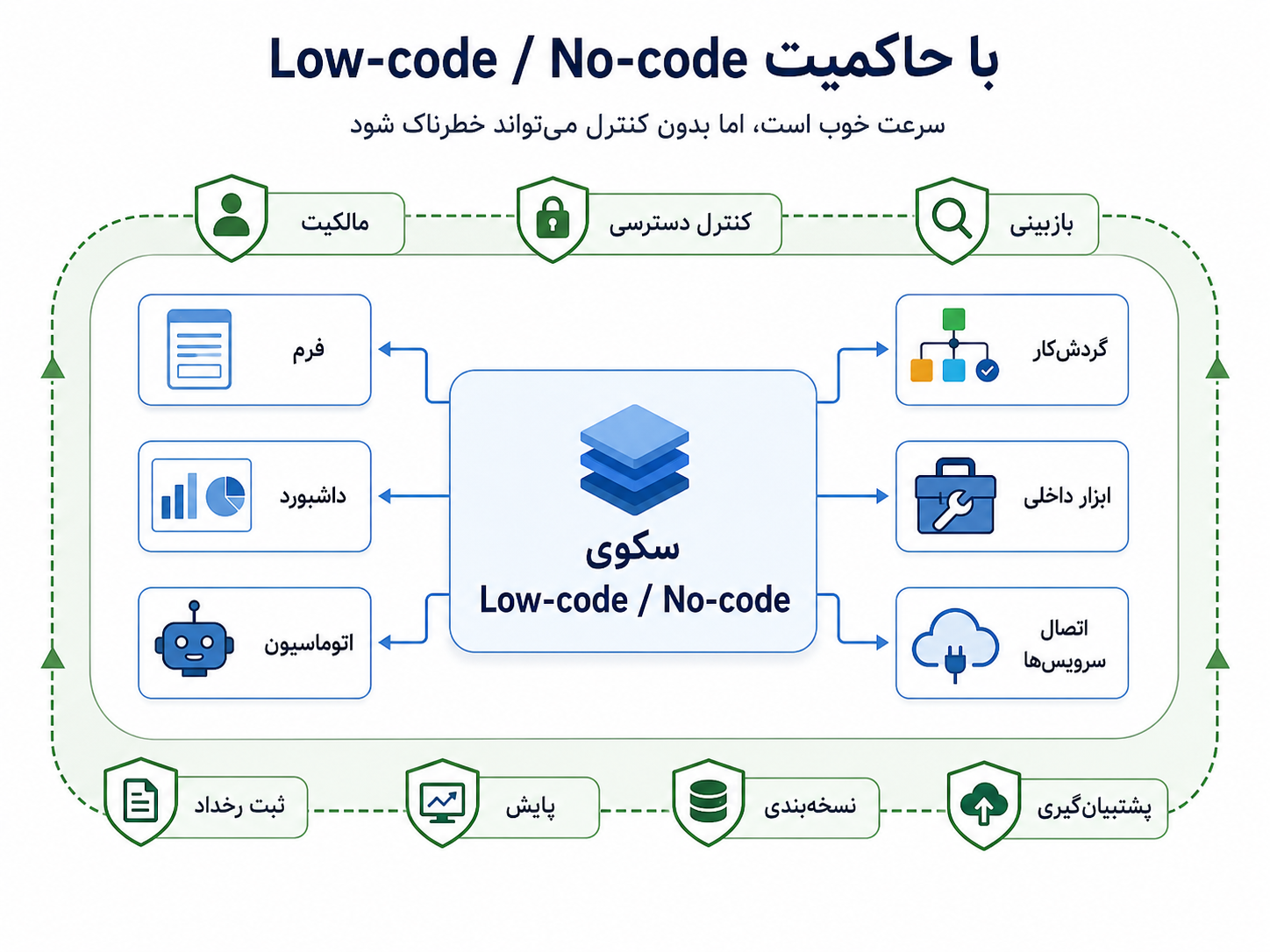
سرعت خوب است، اما بدون کنترل میتواند خطرناک شود. ابزارهای کمکدنویسی هم به مالکیت، دسترسی، بازبینی، نسخهبندی، پایش و پشتیبانی نیاز دارند.
Low-code/No-code برای همهچیز بد نیست؛ اتفاقاً اگر درست استفاده شود، بسیار مفید است. برای ساخت نمونهی اولیه، فرمهای داخلی کمریسک، داشبوردهای سبک، اتوماسیونهای ساده و ابزارهای عملیاتی کوچک میتواند انتخاب خوبی باشد. اما هرچه ابزار به دادهی حساس، تراکنش مالی، منطق اصلی محصول، مشتری واقعی یا عملیات حیاتی نزدیکتر شود، باید سختگیرتر شویم. آنجا دیگر سرعت اولیه کافی نیست؛ چرخهی عمر مهم است.
ساختن یک جریان در چند ساعت شاید سریع باشد، اما اگر مالکیت، تست، نسخهبندی، امنیت، مشاهدهپذیری و برنامهی خطا نداشته باشد، هزینهاش در زمان تغییر، خطا و مهاجرت پس گرفته میشود.
این نگاه، ما را از یک سوءبرداشت دور میکند: Low-code/No-code جایگزین مهندسی نرمافزار نیست؛ فقط بعضی شکلهای ساخت نرمافزار را برای بعضی مسئلهها سریعتر و در دسترستر میکند. اگر مسئله کوچک، داخلی، کمریسک و قابل جایگزینی است، این ابزارها میتوانند عالی باشند. اگر مسئله حیاتی، حساس، پیچیده و بلندمدت است، باید همان سطحی از فکر مهندسی را وارد کنیم که برای هر سیستم مهم دیگری لازم داریم.
برای من، Low-code/No-code نه ناجی است و نه دشمن. یک ابزار است؛ ابزاری که وقتی برای مسئلهی درست، با مالکیت روشن و مرز مشخص استفاده شود، سرعت میسازد. اما وقتی جای معماری، مالکیت و چرخهی عمر نرمافزار را بگیرد، در بلندمدت همان چیزی را تولید میکند که قرار بود حل کند: کندی، آشفتگی و وابستگی.
اینجا پل بخش بعد شکل میگیرد. Low-code/No-code خانوادهی وسیعی از ابزارهاست؛ از فرم و داشبورد تا اتوماسیون و اتصال بین سرویسها. اما وقتی مسئله از چند اتصال ساده فراتر میرود و تبدیل میشود به فرایند رسمی سازمانی با نقشها، وضعیتها، تأییدها، زمانبندیها، گزارش مدیریتی و چرخهی عمر روشن، وارد دنیای BPMS میشویم.
وقتی کار فقط کد نیست، فرایند هم هست
در بخش قبل گفتیم Low-code و No-code میتوانند برای فرمها، داشبوردها، اتوماسیونهای سبک و ابزارهای داخلی مفید باشند؛ اما همانجا هم دیدیم که اگر این ابزارها بدون مالکیت و مرز روشن رشد کنند، آرامآرام تبدیل میشوند به زیرساخت نامرئی سازمان. حالا یک قدم جلوتر میرویم. فرض کنیم مسئله دیگر فقط یک فرم یا یک جریان ساده نیست؛ مسئله خودِ فرایند کسبوکار است.
تفاوت BPMS با یک جریان ساده این است که BPMS بیشتر دربارهی زندگی یک پرونده در طول زمان است؛ نه فقط اجرای چند عمل پشت سر هم. یک پرونده ممکن است میان چند نقش انسانی، چند تصمیم، چند وضعیت، چند سیستم و چند زمانبندی حرکت کند.
یک مثال ساده را در نظر بگیریم: مرجوعی کالا. اول کار شاید فقط یک فرم باشد. مشتری درخواست میدهد، پشتیبانی بررسی میکند و نتیجه را اعلام میکند. اما بعد سازمان رشد میکند و فرایند شاخه پیدا میکند. اگر مبلغ کالا زیاد بود، مدیر باید تأیید کند. اگر دلیل مرجوعی خرابی بود، تیم کنترل کیفیت باید نظر بدهد. اگر تأیید شد، تیم مالی باید بازپرداخت انجام دهد. اگر سه روز گذشت و اقدامی نشد، باید هشدار بخورد. اگر رد شد، دلیل رد باید ثبت شود. اگر تأیید شد، باید به سیستم انبار یا مالی پیام برود.
اینجا دیگر با یک فرم ساده طرف نیستیم. با کاری طرفیم که بین چند نقش انسانی، چند تصمیم، چند وضعیت، چند سیستم و چند زمانبندی حرکت میکند. اگر این مسیر در ایمیل، اکسل، پیامرسان، تماس تلفنی، چند اسکریپت و حافظهی آدمها پخش شود، بعد از مدتی هیچکس دقیق نمیداند هر درخواست کجاست، چرا گیر کرده، چه کسی باید اقدام کند و قانون تصمیم دقیقاً کجا تعریف شده است.
وقتی یک فرایند واحد در ابزارهای مختلف پخش شود، دیدن وضعیت، مسئول مرحلهی بعد و دلیل توقف کار سخت میشود.
BPMS یا سامانهی مدیریت فرایندهای کسبوکار، از همین درد شروع میشود. ایده این است که فرایندهای مهم فقط در ذهن آدمها، ایمیلها، فایلهای پراکنده و کدهای نامنظم زندگی نکنند؛ بلکه مدلسازی، اجرا، پایش و اصلاح شوند. BPMS تلاش میکند جریان کار را به چیزی تبدیل کند که بتوانیم آن را ببینیم، دربارهاش حرف بزنیم، وضعیتش را بفهمیم و تغییرش را کنترل کنیم.
BPMS ابزاری است برای مدلسازی، اجرای قابل پیگیری، پایش و تغییر فرایندهایی که معمولاً چند مرحله، چند نقش انسانی، چند تصمیم و چند اتصال سیستمی دارند.
میل به مدیریت فرایندها چیز تازهای نیست. سازمانها همیشه فرم، ارجاع، تأیید، پرونده و گردش کار داشتهاند. در دنیای نرمافزار هم از سالها قبل سیستمهای جریان کار، موتورهای قوانین، ابزارهای BPM و زبانهای مدلسازی فرایند شکل گرفتند. استانداردهایی مثل BPMN کمک کردند فرایندها به شکل نمودارهایی مدل شوند که هم برای تحلیلگر کسبوکار قابل فهم باشند، هم برای تیم فنی قابل تبدیل به اجرا یا پیادهسازی. امروز ابزارهایی مثل Camunda، Flowable، Bonita و ابزارهای مشابه تلاش میکنند همین ایده را در سیستمهای واقعی اجراپذیرتر کنند.
اما BPMS فقط کشیدن فلوچارت نیست. اگر فقط نمودار بکشیم و بعد همهچیز همچنان در ایمیل و کدهای پراکنده اجرا شود، مسئله حل نشده است. BPMS وقتی معنا دارد که فرایند بتواند وضعیت داشته باشد، در مرحلهای منتظر بماند، به نقش مشخصی وظیفه بدهد، بر اساس تصمیم مسیر عوض کند، به سرویس بیرونی پیام بدهد، زمانسنج و هشدار داشته باشد و قابل پایش باشد.
در همان مثال مرجوعی کالا، میتوانیم مسیر را روشنتر کنیم: درخواست ثبت میشود، پشتیبانی بررسی اولیه انجام میدهد، اگر نیاز به تأیید داشت مدیر وارد میشود، اگر تأیید شد تیم مالی اقدام میکند و در پایان وضعیت درخواست بسته میشود. در هر لحظه معلوم است درخواست در چه وضعیتی است، مسئول مرحلهی بعد کیست و چرا از یک مسیر خاص عبور کرده است.
در BPMS، فرایند فقط چند دستور پشت سر هم نیست؛ یک مسیر دارای وضعیت، نقش، تصمیم و قابل پیگیری است.
مزیت اصلی BPMS این نیست که کد را حذف میکند. مزیت اصلی این است که فرایند را به یک موجود قابل مشاهده و قابل بحث تبدیل میکند. آدم محصول، عملیات، حقوقی، مالی و فنی میتوانند دربارهی یک مدل مشترک حرف بزنند. میتوانند ببینند گلوگاه کجاست، چه مرحلهای زیاد طول میکشد، کدام تصمیمها زیاد رد میشوند، و کجا باید نقش، قانون یا مسیر فرایند تغییر کند.
BPMS وقتی ارزشمند است که مسئلهی اصلی، خود جریان کار باشد: فرایندی چندمرحلهای، چندنقشی، تغییرپذیر، زمانمند و نیازمند ردیابی. اگر فقط یک فرم ساده یا یک اتوماسیون کوچک داریم، شاید BPMS از همان ابتدا بیش از حد سنگین باشد.
اما حالا نوبت نقد جدی است. BPMS نباید تبدیل شود به جایی که منطق اصلی محصول در آن دفن میشود. این خطر واقعی است. چون ظاهر BPMS معمولاً شفاف و فریبنده است: چند نمودار، چند کار، چند فرم، چند تصمیم و چند اتصال. اما اگر مراقب نباشیم، همان منطق مهمی که باید در سرویسهای قابل تست، قابل مشاهده و دامنهمحور باشد، در میان نمودارها، کارهای اسکریپتی، قانونهای پراکنده و اتصالهای پنهان دفن میشود.
مشکل BPMS این نیست که فرایند را مدل میکند؛ مشکل وقتی شروع میشود که مدل فرایند جای طراحی دامنه و معماری سیستم را بگیرد. اگر قواعد اصلی محصول، محاسبات حساس، تصمیمهای امنیتی، منطق مالی یا تغییرات مهم وضعیت را بیحساب داخل BPMS ببریم، بعد از مدتی سیستم نه سادهتر، که سختتر از کد معمولی قابل فهم و تغییر میشود.
گاهی BPMS پیچیدگی را از کد بیرون نمیکشد؛ فقط همان پیچیدگی را در نمودارها، کارها و اتصالهای پنهان قایم میکند.
فرایندها به مرور شاخه و شرط پیدا میکنند. یک استثنا برای مشتری مهم اضافه میشود، بعد یک مسیر ویژه برای قراردادهای بزرگ، بعد یک قانون موقت برای تیم مالی، بعد یک اسکریپت برای اصلاح داده، بعد یک اتصال به CRM، بعد یک اتصال به سرویس پرداخت. بعد از مدتی نموداری که قرار بود شفافکننده باشد، خودش تبدیل میشود به جنگلی از فلشها و شرطها. تغییر ساده نیازمند فهم چند مدل، چند نقش، چند فرم، چند اتصال بیرونی و چند قانون پنهان میشود.
پس مرز سالم این است: BPMS بهتر است ارکسترکنندهی فرایند باشد، نه مالک همهی منطق کسبوکار. اگر قرار است اعتبار مالی مشتری محاسبه شود، موجودی کیف پول تغییر کند، سیاست امنیتی حساس اعمال شود یا تصمیمی با اثر مالی جدی گرفته شود، بهتر است این منطق در سرویسهای دامنهمحور، قابل تست و قابل مشاهده بماند. BPMS میتواند آن سرویسها را صدا بزند، مسیر را هماهنگ کند و وضعیت فرایند را نگه دارد، اما نباید بیدلیل جای آنها را بگیرد.
BPMS برای هماهنگی فرایند خوب است، نه برای دفن کردن همهی منطق محصول. اگر منطق اصلی، تستپذیری، مالکیت و مشاهدهپذیری را قربانی نمودارهای ظاهراً ساده کنیم، فقط پیچیدگی را از یک جا به جای دیگر منتقل کردهایم.
برای فرایندهای ساده، از روز اول BPMS لازم نیست. اگر یک فرم داخلی، یک تأیید ساده یا یک اتوماسیون کمریسک داریم، شاید همان ابزارهای سادهتر بخش قبل کافی باشند. BPMS وقتی ارزش پیدا میکند که فرایند واقعاً طولانی، چندنقشی، تغییرپذیر، حساس به زمان و نیازمند حسابرسی باشد. در غیر این صورت، ممکن است ابزار سنگینی وارد کنیم که خودِ ابزار از مسئله بزرگتر شود.
چه زمانی BPMS انتخاب خوبی است؟
وقتی فرایند چندمرحلهای است، چند نقش انسانی دارد، وضعیت آن باید در طول زمان نگهداری شود، تأخیرها و گلوگاهها مهماند، حسابرسی لازم است، و تغییر فرایند باید برای تیمهای فنی و غیرفنی قابل بحث باشد، BPMS میتواند انتخاب مناسبی باشد.
چه زمانی بهتر است سراغ BPMS نرویم؟
اگر فرایند ساده است، تغییر کمی دارد، یک سرویس کوچک میتواند آن را روشن و قابل تست پیاده کند، یا هنوز خود مسئله به اندازهی کافی تثبیت نشده، شروع با BPMS ممکن است زود باشد. در چنین حالتی ابزارهای سبکتر، کدنویسی مستقیم یا حتی یک جریان ساده ممکن است انتخاب بهتری باشد.
برای من، BPMS یعنی پذیرفتن اینکه در بعضی سیستمها، خودِ فرایند به اندازهی کد مهم است. باید بدانیم کار کجاست، دست کیست، چرا متوقف شده و با چه قانونی جلو میرود. اما BPMS هم مثل Low-code/No-code قرار نیست جای فکر مهندسی را بگیرد. وقتی درست استفاده شود، فرایند را شفاف و قابل پایش میکند. وقتی بد استفاده شود، پیچیدگی را در نمودارها پنهان میکند و به سیستم ظاهراً تصویری اما عملاً سختفهم میرسیم.
تا اینجا دربارهی ابزارهایی حرف زدیم که ساخت نرمافزار، عملیات، فرایند و اتوماسیون را تغییر میدهند. اما موج تازهتری هم وارد مهندسی نرمافزار شده است: هوش مصنوعی. حالا سؤال این است که آیا هوش مصنوعی میتواند خود فرایند ساخت نرمافزار را تغییر دهد؟ اینجا وارد AI4SE میشویم؛ یعنی استفاده از هوش مصنوعی برای کمک به مهندسی نرمافزار.
وقتی هوش مصنوعی وارد کارگاه مهندسی نرمافزار میشود
حتی اگر معماری، زیرساخت و فرایندها را بهتر کنیم، خود کار روزمرهی مهندسی نرمافزار هنوز سنگین است. کد بیشتر شده، درخواستهای ادغام یا Pull Requestها بزرگتر شدهاند، سرویسها به هم وابستهتر شدهاند، مستندات زود کهنه میشوند، تستها باید بهروز بمانند، بازآرایی کد یا refactor خطر شکستن رفتار دارد، و بازبینی تغییرات وقت و دقت زیادی میخواهد. حتی اگر تیم خوبی داشته باشیم، بخشی از کارهای روزانه تکراری، فرساینده و مستعد خطای انسانیاند.
اینجا AI4SE وارد میشود. AI4SE یعنی استفاده از هوش مصنوعی برای کمک به فعالیتهای مهندسی نرمافزار؛ نه حذف مهندسی نرمافزار. هوش مصنوعی میتواند کنار تیم بنشیند، بعضی کارها را سریعتر کند، بعضی مسیرهای فهم را کوتاهتر کند و بعضی خطاها را زودتر به چشم بیاورد. اما تصمیم، مالکیت و مسئولیت همچنان با تیم مهندسی است.
AI4SE یعنی بهکارگیری هوش مصنوعی برای بهتر، سریعتر یا قابلاعتمادتر کردن فعالیتهای مهندسی نرمافزار؛ از فهم کد و تولید تست تا بازبینی، مستندسازی، تحلیل خطا و کمک به نگهداری سیستم.
این مسیر از هیچجا ناگهان با ChatGPT شروع نشد. قبل از موج مدلهای زبانی بزرگ، سالها ابزارهای تحلیل ایستا، ابزارهای سبک بررسی کد، جستوجوی کد، تکمیل خودکار، پیشنهاد بازآرایی، تشخیص خطا و تولید تست وجود داشتند. بخشی از آنها قاعدهمحور بودند، بخشی از تکنیکهای برنامهکاوی و یادگیری ماشین استفاده میکردند، و بخشی هم در محیطهای توسعه به شکل پیشنهادهای محدود دیده میشدند.
بعدتر با رشد یادگیری عمیق و مدلهای آموزشدیده روی کد، کمکهای هوشمندتر ممکن شد. برای خیلی از توسعهدهندهها، GitHub Copilot یک نقطهی عطف بود؛ ابزاری که در ۲۰۲۱ بهعنوان یک «همکار برنامهنویس هوشمند» معرفی شد و تجربهی تولید و تکمیل کد با مدل زبانی را وارد کار روزمرهی توسعهدهندگان کرد. اما موج بعدی فقط تکمیل خودکار نبود. با رشد مدلهای زبانی بزرگ، مسئله از ادامه دادن چند خط کد به فهمیدن شرح مسئله، خواندن چند فایل، پیشنهاد وصله، نوشتن تست، توضیح تغییر و حتی اجرای چند گام روی مخزن کد نزدیک شد.
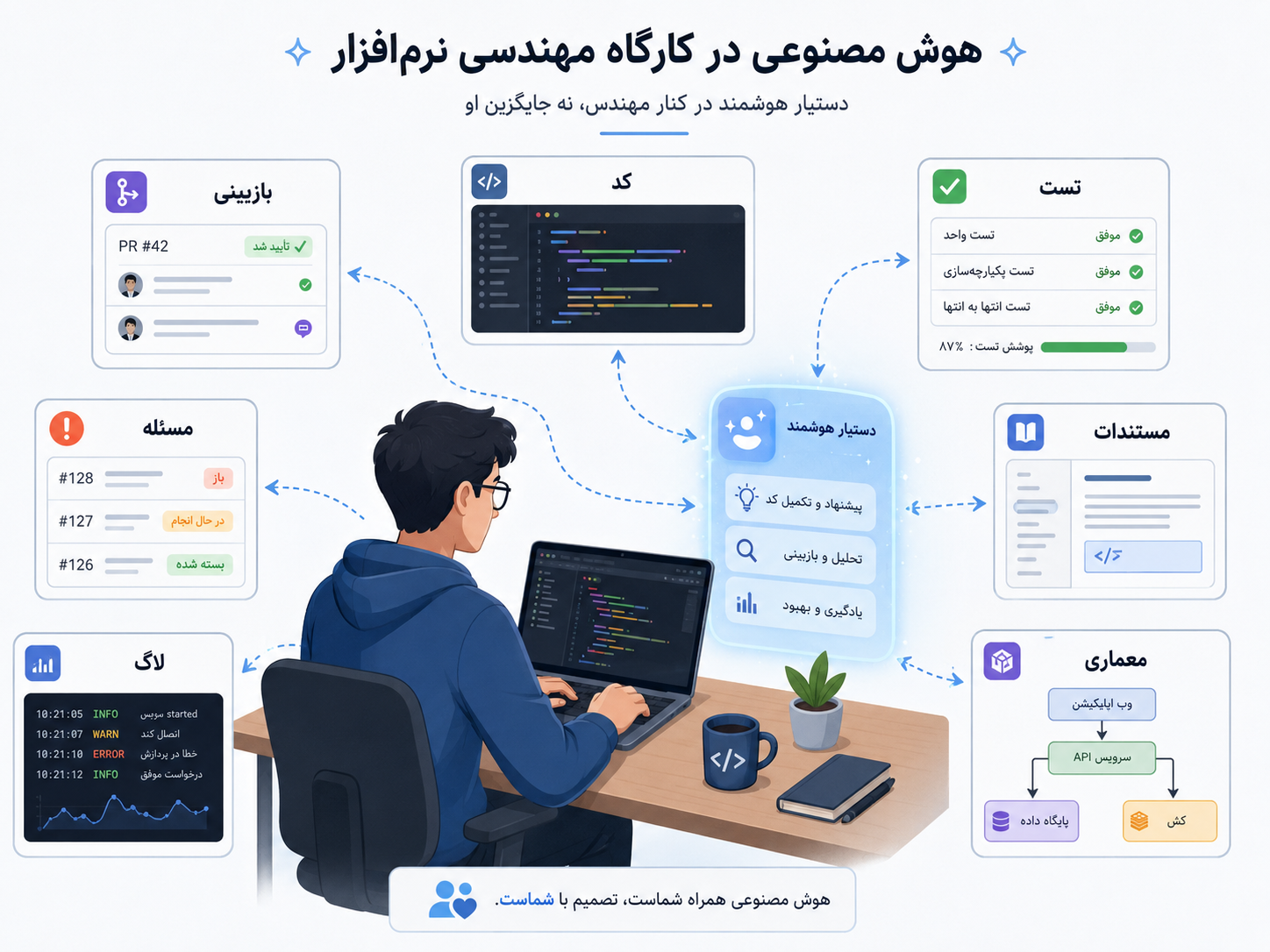
هوش مصنوعی میتواند کنار مهندس باشد؛ برای پیشنهاد، توضیح، بررسی و یادآوری. اما جای تصمیم مهندسی، مالکیت و فهم سیستم را نمیگیرد.
کاربردهای AI4SE فقط به تولید کد محدود نیست. گاهی ارزش آن در فهمیدن کد موجود است: خلاصه کردن یک فایل پیچیده، توضیح مسیر اجرای یک قابلیت، یا پیدا کردن ارتباط چند کلاس و سرویس. گاهی در تست کمک میکند: پیشنهاد حالتهای مرزی، ساخت دادهی آزمایشی یا یادآوری سناریوهایی که از قلم افتادهاند. گاهی در بازبینی کد مفید است: خلاصه کردن درخواست ادغام، برجسته کردن تغییرهای پرریسک، پیشنهاد تست، یا پیدا کردن ناسازگاری با قرارداد API. گاهی هم در مستندسازی و عیبیابی کمک میکند: نوشتن پیشنویس مستندات، خلاصه کردن لاگها، دستهبندی خطاها یا کوتاه کردن مسیر بررسی حادثه.
اما هرچه از «تولید چند خط کد» به «تصمیم مهندسی» نزدیک میشویم، کیفیت زمینه مهمتر میشود. یک مدل اگر فقط تغییرات کد را ببیند، شاید بتواند ظاهر تغییر را توضیح دهد؛ اما نمیتواند همیشه بفهمد این تغییر با نیت شرح مسئله، قرارداد API، معماری سرویس، تستهای موجود، محدودیتهای دامنه و تجربهی کاربر سازگار است یا نه. در کارهای جدی، مدل فقط به دستور خوب نیاز ندارد؛ به زمینهی خوب نیاز دارد.
این نکته مخصوصاً در بازبینی کد پررنگ است. بازبینی خوب فقط خواندن تغییرات کد نیست. بازبینی یعنی فهمیدن اینکه چرا این تغییر انجام شده، روی چه رفتاری اثر میگذارد، چه قراردادی را تغییر میدهد، کدام تست باید اضافه شود، چه چیزی ممکن است در سرویس دیگری بشکند و آیا این تغییر با مسیر بلندمدت سیستم سازگار است یا نه.
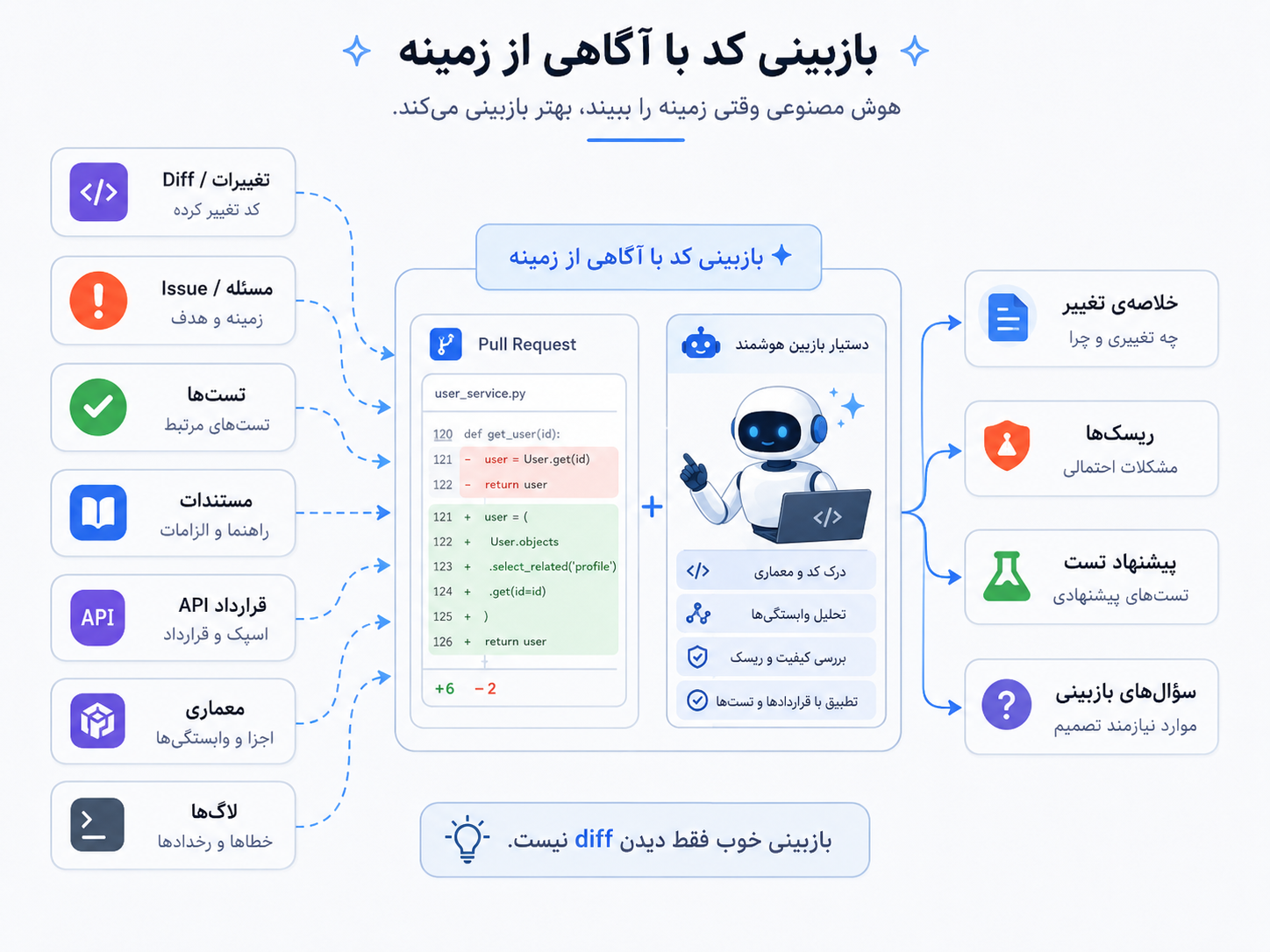
هوش مصنوعی وقتی بهتر بازبینی میکند که فقط تغییرات کد را نبیند؛ بلکه شرح مسئله، تستها، مستندات، قراردادها، معماری و لاگها هم بخشی از زمینه باشند.
برای همین، بازبین هوشمند خوب باید بیشتر از یک تولیدکنندهی نظر باشد. باید بتواند نیت تغییر را بفهمد، سؤالهای درست بپرسد، جاهایی را که نیاز به تست دارند برجسته کند، و اگر زمینه کافی نیست، با اعتمادبهنفس بیجا حکم ندهد. حتی در بهترین حالت هم نقش آن کمک به بازبین انسانی است، نه جایگزینی کامل او.
بازبینی فقط خواندن تغییرات کد نیست. بازبینی یعنی فهمیدن نیت تغییر، اثر آن روی رفتار سیستم، قراردادها، تستها و نگهداری آینده. بدون زمینهی کافی، بازبین هوشمند هم بهراحتی به نظرهای عمومی و کمارزش میرسد.
در تولید تست هم همین مرز وجود دارد. هوش مصنوعی میتواند حالت آزمایشی پیشنهاد بدهد، اما تست خوب فقط زیاد بودن تعداد تستها نیست. تست خوب باید رفتار مهم را تثبیت کند، حالت مرزی واقعی را پوشش دهد و نسبت به بازآراییهای بیاثر شکننده نباشد. اگر هوش مصنوعی تستهایی بسازد که فقط جزئیات پیادهسازی را بررسی میکنند، ممکن است تعداد تستها زیاد شود، اما اعتماد ما به تغییر بیشتر نشود. حتی بدتر، ممکن است بازآراییهای خوب را سختتر کند، چون تستها به جای رفتار، به شکل داخلی کد چسبیدهاند.
هدف تست، افزایش اعتماد به تغییر است؛ نه فقط افزایش تعداد فایلهای تست. این همان جایی است که قضاوت مهندسی مهم میشود. مدل میتواند پیشنهاد بدهد، اما تیم باید تشخیص دهد آیا این تست واقعاً رفتار مهم را پوشش میدهد یا فقط خروجی ظاهراً قانعکننده تولید کرده است.
حالا نقد اصلی بخش: AI4SE وقتی خطرناک میشود که سازمانها سرعت تولید خروجی را با کیفیت مهندسی اشتباه بگیرند. مدل میتواند سریع کد بنویسد، اما سریعتر نوشتن کد لزوماً یعنی سریعتر رسیدن به نرمافزار قابل نگهداری نیست. ممکن است خروجی زیاد شود، اما بازبینی سختتر شود. ممکن است کد بیشتری تولید شود، اما کسی عمیقاً مالک آن نباشد. ممکن است تست بیشتری ساخته شود، اما رفتار مهم پوشش داده نشود. ممکن است مستندات روانتر شوند، اما دقیق نباشند.

روی سطح، تولید کد، تست و مستندات سریعتر میشود؛ زیر سطح، اگر مالکیت و بازبینی نباشد، بدهی نگهداری و ابهام سیستم بیشتر میشود.
خطر AI4SE فقط این نیست که مدل اشتباه میکند. خطر بزرگتر این است که مدل با اعتمادبهنفس اشتباه میکند و ما هم از خستگی، فشار زمانی یا جذابیت سرعت، آن را میپذیریم. خروجی مدل معمولاً خوشساخت و قانعکننده است؛ همین باعث میشود خطاهایش دیرتر دیده شود. کدی که با اطمینان نوشته شده، تستی که نام خوبی دارد، یا مستندی که روان است، الزاماً درست نیست.
هوش مصنوعی میتواند تولید کد را ارزانتر کند، اما اگر فهم سیستم گرانتر شود، تیم در مجموع کندتر شده است. این جمله برای من مرکز نقد AI4SE است. اگر هر قابلیت با سرعت بیشتری کد تولید کند، اما بازبینی، نگهداری، عیبیابی و فهم تغییر سختتر شود، ما فقط بدهی فنی را سریعتر تولید کردهایم.
هوش مصنوعی میتواند خروجی بیشتری تولید کند؛ اما خروجی بیشتر اگر بیمالک، کمفهم، کمتست یا ناسازگار با معماری باشد، به کیفیت تبدیل نمیشود. گاهی فقط هزینهی نگهداری را به آینده منتقل میکند.
پس مرز سالم چیست؟ هوش مصنوعی برای کارهای کمکی، تکراری، توضیحی و اکتشافی بسیار مفید است؛ جایی که انسان هنوز تصمیم نهایی را میگیرد. خلاصه کردن درخواست ادغام، پیشنهاد حالتهای آزمایشی، تولید پیشنویس مستندات، توضیح کد قدیمی، کمک به جستوجو در مخزن کد، یا ساخت نمونهی اولیه میتواند عالی باشد. اما تصمیمهای حساس معماری، امنیت، داده، رفتار دامنه و تغییرات پرریسک نباید فقط به خروجی مدل سپرده شوند.
هوش مصنوعی نمیتواند جای خالی معماری نامفهوم، تستهای بد، مستندات فرسوده و مالکیت مبهم را معجزهوار پر کند؛ گاهی فقط آنها را سریعتر تکثیر میکند. اگر مخزن کد بینظم است، اگر قراردادها روشن نیستند، اگر تستها شکنندهاند، اگر شرح مسئلهها مبهماند، مدل هم بر همان ابهام سوار میشود و خروجیهایی میدهد که شاید زیبا باشند، اما الزاماً قابل اتکا نیستند.
چه زمانی AI4SE واقعاً کمک میکند؟
وقتی مسئله محدود و روشن است، زمینهی کافی داریم، خروجی مدل بازبینی میشود، و تیم از هوش مصنوعی برای کاهش کار تکراری یا افزایش فهم استفاده میکند، نه برای حذف قضاوت مهندسی. در این حالت هوش مصنوعی میتواند سرعت فهم، مستندسازی، تستنویسی اولیه و بررسی تغییرات را بهتر کند.
چه زمانی AI4SE خطرناک میشود؟
وقتی خروجی مدل بدون بازبینی وارد کد میشود، وقتی زمینه ناقص است، وقتی مدل به جای بازبین یا معمار تصمیم میگیرد، وقتی تستهای تولیدی فقط ظاهر اعتماد میسازند، یا وقتی سازمان به جای بهتر کردن معماری و کیفیت، فقط انتظار دارد هوش مصنوعی مشکلات ساختاری را جبران کند.
برای من، AI4SE یعنی آوردن یک دستیار قدرتمند به کارگاه مهندسی نرمافزار. این دستیار میتواند سریع بخواند، سریع پیشنهاد بدهد، سریع خلاصه کند و سریع پیشنویس بسازد. اما نرمافزار خوب فقط از سرعت ساخته نمیشود. نرمافزار خوب به فهم، مالکیت، بازبینی، تست، طراحی و تصمیمگیری مسئولانه نیاز دارد. هوش مصنوعی اگر اینها را تقویت کند، ارزشمند است؛ اگر جای آنها بنشیند، خطرناک است.
تا اینجا گفتیم هوش مصنوعی چطور میتواند به مهندسی نرمافزار کمک کند. اما سؤال برعکس هم وجود دارد: وقتی خود محصول ما مبتنی بر هوش مصنوعی است، چطور باید آن را مهندسی کنیم؟ مدلها رفتار کاملاً قطعی ندارند، داده و دستور و ارزیابی بخشی از سیستم میشوند، و رفتار خروجی همیشه مثل کد معمولی قابل پیشبینی نیست. اینجا وارد SE4AI میشویم: مهندسی نرمافزار برای سیستمهای هوش مصنوعی.
وقتی خود هوش مصنوعی هم به مهندسی نیاز دارد
در بخش قبل گفتیم هوش مصنوعی چطور میتواند به مهندسی نرمافزار کمک کند: در فهم کد، نوشتن تست، بازبینی، مستندسازی و عیبیابی. حالا سؤال را برعکس میکنیم. اگر خودِ محصول ما مبتنی بر هوش مصنوعی باشد چه؟ اگر قابلیت اصلی سیستم نه فقط چند خط کد، بلکه یک مدل، دستور مدل، داده، بازیابی دانش، ارزیابی و سیاست محصولی باشد، مهندسی نرمافزار چه نقشی دارد؟
تصور کنیم تیمی میخواهد یک قابلیت هوشمند به محصول اضافه کند: چتبات پشتیبانی، سیستم پیشنهاددهنده، تشخیص تقلب، خلاصهسازی تیکتها، تحلیل احساسات پیامهای کاربران، جستوجوی هوشمند، یا یک قابلیت مبتنی بر مدل زبانی بزرگ برای تولید پاسخ. در دمو همهچیز جذاب است. چند مثال خوب جواب میگیرند، تیم محصول هیجانزده میشود و همه حس میکنند «فقط کافی است مدل را صدا بزنیم».
اما محصول واقعی با دمو فرق دارد. ورودیها تمیز و قابل پیشبینی نیستند. کاربران سؤالهای عجیب میپرسند. دادهی زمینه ناقص است. خروجی مدل گاهی غلط اما قانعکننده است. دستورهای مدل تغییر میکنند. نسخهی مدل عوض میشود. معیار کیفیت همیشه یک عدد ساده نیست. گاهی پاسخ از نظر زبانی خوب است، اما از نظر محصولی، حقوقی، امنیتی یا اخلاقی قابل قبول نیست. اینجا روشن میشود که سیستم مبتنی بر هوش مصنوعی فقط مدل نیست؛ یک سیستم نرمافزاری کامل است.
SE4AI یعنی استفاده از اصول مهندسی نرمافزار برای ساخت سیستمهای مبتنی بر هوش مصنوعی؛ سیستمهایی که فقط با داشتن مدل قوی قابل اعتماد نمیشوند.
مرز این بخش با بخش قبل و بعدی مهم است. AI4SE میپرسید: هوش مصنوعی چطور به کارهای مهندسی نرمافزار کمک میکند؟ SE4AI میپرسد: وقتی نرمافزارمان هوش مصنوعی دارد، چطور آن را مثل یک سیستم مهندسیشده، قابل تست، قابل کنترل و قابل اعتماد بسازیم؟ MLOps که بخش بعدی است، بیشتر روی چرخهی عملیاتی مدلها تمرکز میکند: داده، آموزش، نسخهبندی مدل، استقرار، پایش، رانش و بازآموزی.
در نرمافزار سنتی، بخش زیادی از رفتار سیستم از کدی میآمد که خودمان نوشته بودیم. اگر ورودی مشخصی میدادیم، انتظار خروجی مشخصی داشتیم. البته باگ همیشه وجود داشت، اما رفتار اصلی سیستم از منطق صریح کد میآمد. با ورود سیستمهای یادگیری ماشین، بخشی از رفتار دیگر مستقیماً در کد نوشته نمیشد؛ از داده یاد گرفته میشد. با مدلهای زبانی بزرگ این پیچیدگی شکل تازهای گرفت: علاوه بر کد، داده و مدل، حالا دستور مدل، زمینه، بازیابی دانش، حافظه، ابزارهای متصل، لایههای حفاظتی و ارزیابی هم بخشی از رفتار سیستماند.
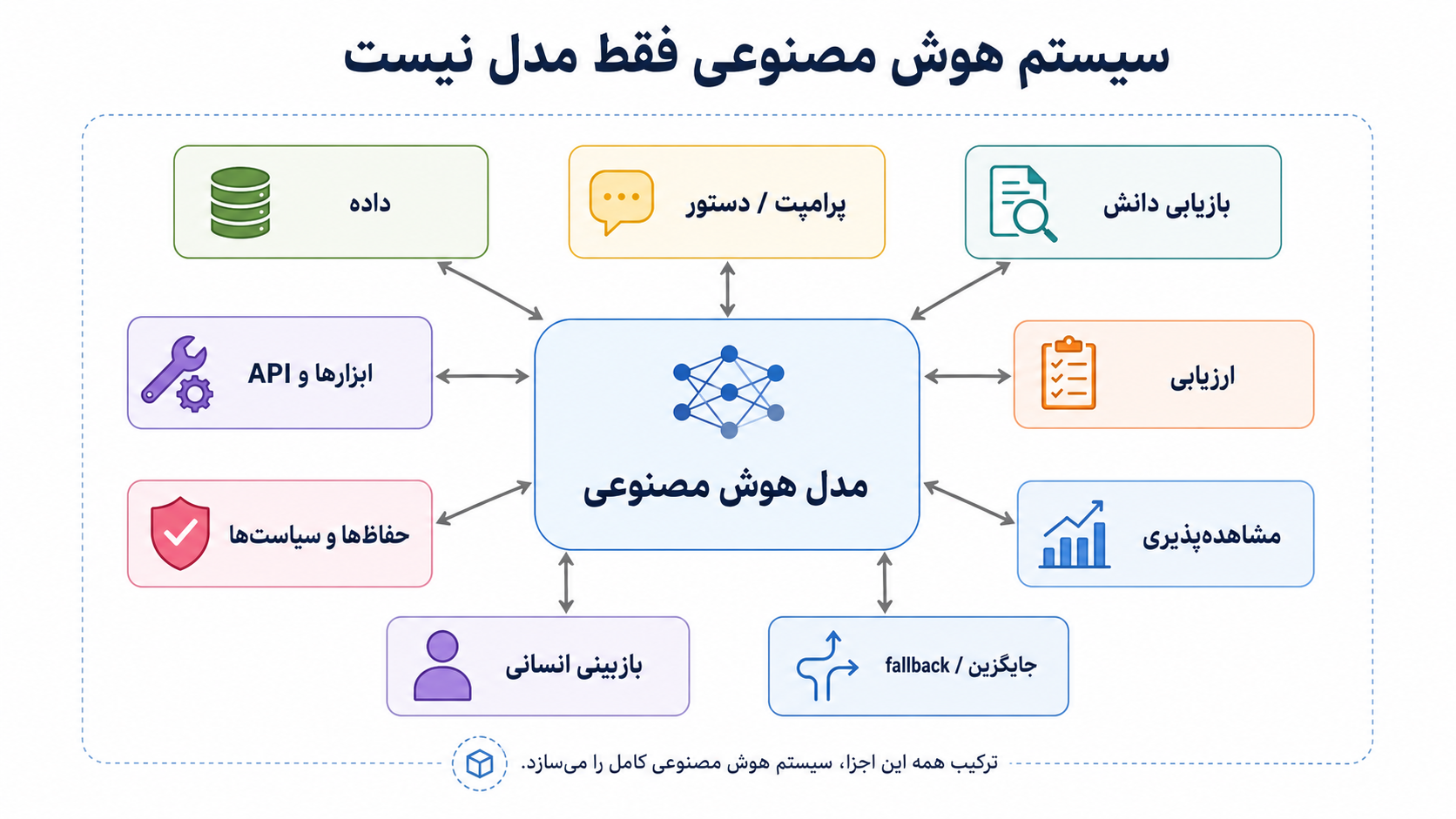
مدل فقط یکی از اجزای سیستم هوش مصنوعی است. داده، دستور مدل، بازیابی دانش، ارزیابی، حفاظتها، مشاهدهپذیری، مسیر جایگزین و بازبینی انسانی هم بخشی از سیستماند.
پس پرسشهای مهندسی عوض میشوند. چه چیزی نسخهبندی میشود؟ فقط کد یا دستور مدل و مجموعهدادهی ارزیابی هم؟ چه چیزی تست میشود؟ فقط API یا کیفیت خروجی مدل هم؟ چه چیزی قابل برگشت است؟ نسخهی مدل، دستور مدل، شاخص بازیابی دانش یا سیاست محصول؟ چه کسی مالک رفتار خروجی است؟ اگر مدل مطمئن نیست، سیستم باید چه کند؟ اگر پاسخ خطرناک، نادرست یا خارج از سیاست محصول بود، چه لایهای جلوی آن را میگیرد؟
یکی از سختترین بخشهای SE4AI، تست و ارزیابی است. در سیستمهای کلاسیک، اغلب میتوانیم بگوییم برای این ورودی، خروجی دقیقاً باید این مقدار باشد. اما در سیستمهای هوش مصنوعی، مخصوصاً مدلهای زبانی، همیشه یک خروجی واحد و قطعی نداریم. چند پاسخ ممکن است قابل قبول باشند. یک پاسخ ممکن است از نظر جملهبندی عالی باشد، اما از نظر دامنه غلط باشد. ممکن است مدل در بیشتر نمونهها خوب عمل کند، اما در چند سناریوی حساس خطای پرهزینه بدهد.
به همین دلیل، تست در سیستمهای هوش مصنوعی فقط test case کلاسیک نیست. به ارزیابی نیاز داریم: نمونههای واقعی و نماینده، معیارهای کیفیت، ارزیابی انسانی در بخشهای حساس، تست بازگشتی برای دستور مدل و نسخهی مدل، سناریوهای خطرناک، و بررسی توهم مدل، سوگیری، حریم خصوصی و امنیت. در سیستم هوش مصنوعی، گاهی سؤال اصلی این نیست که «آیا خروجی دقیقاً برابر مقدار مورد انتظار است؟»؛ سؤال این است که «آیا خروجی برای این زمینه قابل قبول، امن، مفید و مطابق سیاست محصول است؟»
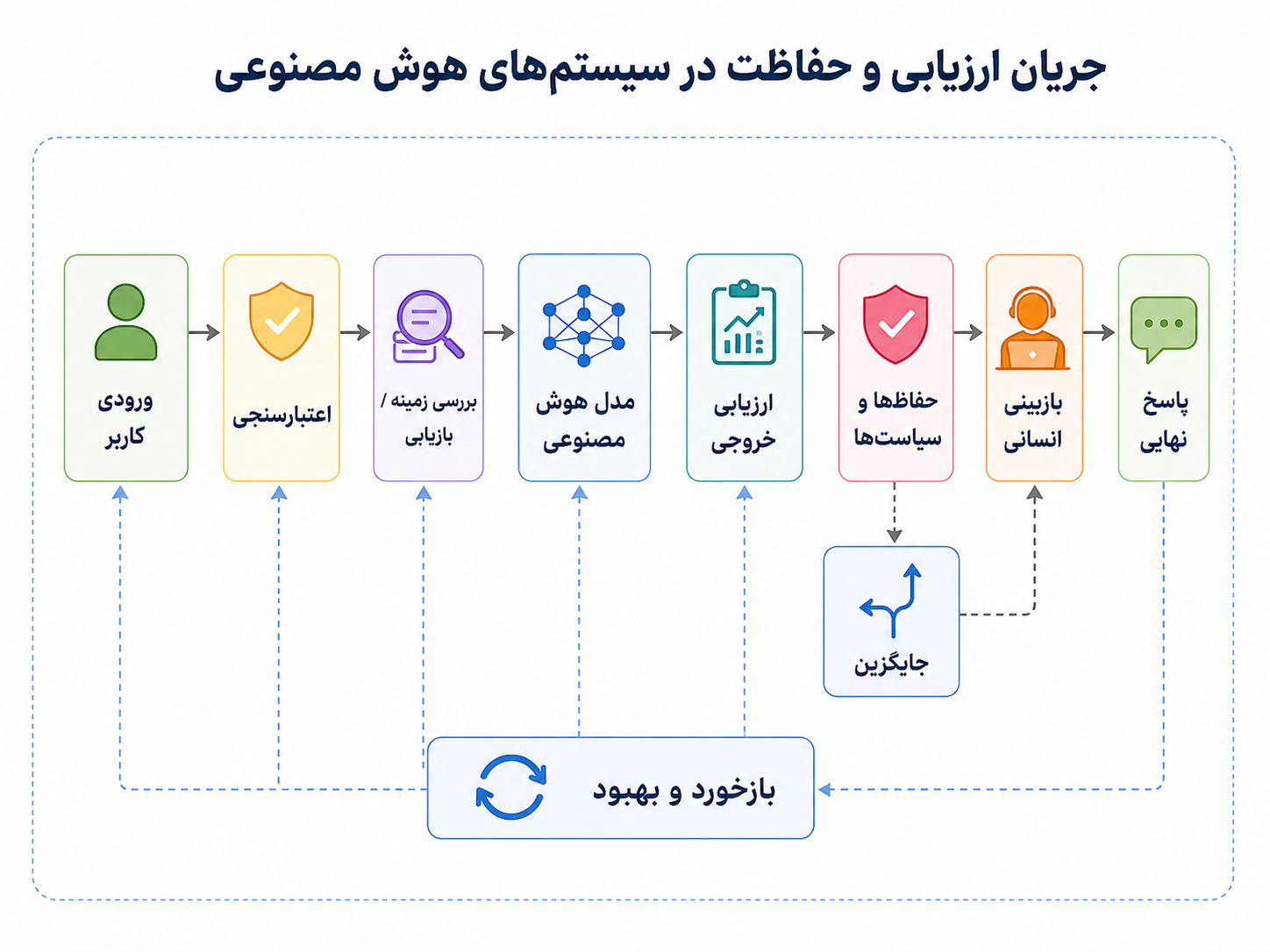
خروجی هوش مصنوعی نباید خام وارد محصول شود؛ باید اعتبارسنجی، ارزیابی، محدودسازی، پایش و در موقعیتهای حساس، بازبینی انسانی داشته باشد.
این موضوع ما را به مسئولیت محصول میرساند. در نرمافزار کلاسیک، اگر تابعی خطا بدهد، معمولاً دنبال باگ در کد میگردیم. در سیستم هوش مصنوعی ممکن است کد درست اجرا شده باشد، API مدل پاسخ داده باشد، هیچ خطای اجرایی رخ نداده باشد، اما خروجی محصول غلط باشد. مثلاً چتبات پشتیبانی سیاست بازگشت وجه را اشتباه توضیح دهد. ابزار خلاصهسازی نکتهی مهم تیکت را حذف کند. سیستم رتبهبندی گروهی از کاربران را ناعادلانه پایینتر بیاورد. یا یک ابزار تولید محتوا ناخواسته دادهی حساس را وارد پاسخ کند.
از نگاه کاربر، اینها خطای «مدل» نیستند؛ خطای محصولاند. وقتی هوش مصنوعی وارد محصول میشود، خروجی مدل هم بخشی از تجربهی کاربر و مسئولیت تیم است. نمیتوانیم بگوییم «مدل اینطور گفت» و کنار بکشیم. باید از قبل طراحی کنیم: کجا مدل اجازهی پاسخ آزاد دارد؟ کجا باید فقط از منابع معتبر جواب بدهد؟ کجا باید بگوید نمیدانم؟ کجا خروجی فقط پیشنهاد است و اقدام خودکار نیست؟ کجا انسان باید وارد حلقه شود؟ و کجا ردپای حسابرسی لازم داریم؟
در سیستمهای مبتنی بر مدل زبانی، چند جزء تازه وارد معماری میشوند. الگوی دستور مدل فقط یک متن ساده نیست؛ یک دارایی مهندسی است که باید نسخه داشته باشد، قابل بازبینی باشد و با تغییرش ارزیابی اجرا شود. بازیابی دانش فقط جستوجوی چند سند نیست؛ روی کیفیت پاسخ و ریسک توهم مدل اثر میگذارد. اتصال مدل به ابزارها فقط قابلیت جذاب محصولی نیست؛ باید محدودیت دسترسی، حسابرسی، خطایابی و مسیر جایگزین داشته باشد. حافظهی مکالمه هم فقط امکانات محصولی نیست؛ میتواند مسئلهی حریم خصوصی، امنیت و کیفیت ایجاد کند.
در سیستمهای مبتنی بر مدل زبانی، دستور مدل، سازندهی زمینه، بازیاب دانش، ابزارهای متصل، حافظه، لایههای حفاظتی و مجموعهدادهی ارزیابی باید مثل اجزای واقعی سیستم دیده شوند؛ نه مثل متنهای موقتی که هرکس دستی تغییرشان بدهد.
حالا نقد اصلی بخش: بزرگترین خطای تیمها این است که سیستم هوش مصنوعی را به مدل تقلیل میدهند. فکر میکنند اگر مدل قویتر شود، مسئله حل است. اما در عمل، بسیاری از شکستها از خود مدل شروع نمیشوند؛ از سیستم اطراف مدل میآیند: دادهی بد، تعریف مبهم مسئله، نداشتن ارزیابی، نبود مسیر جایگزین، سیاست محصولی نامشخص، دادهی حساس در دستور مدل، اعتماد بیش از حد به خروجی، نبود مشاهدهپذیری، یا نبود مالکیت برای رفتار مدل.
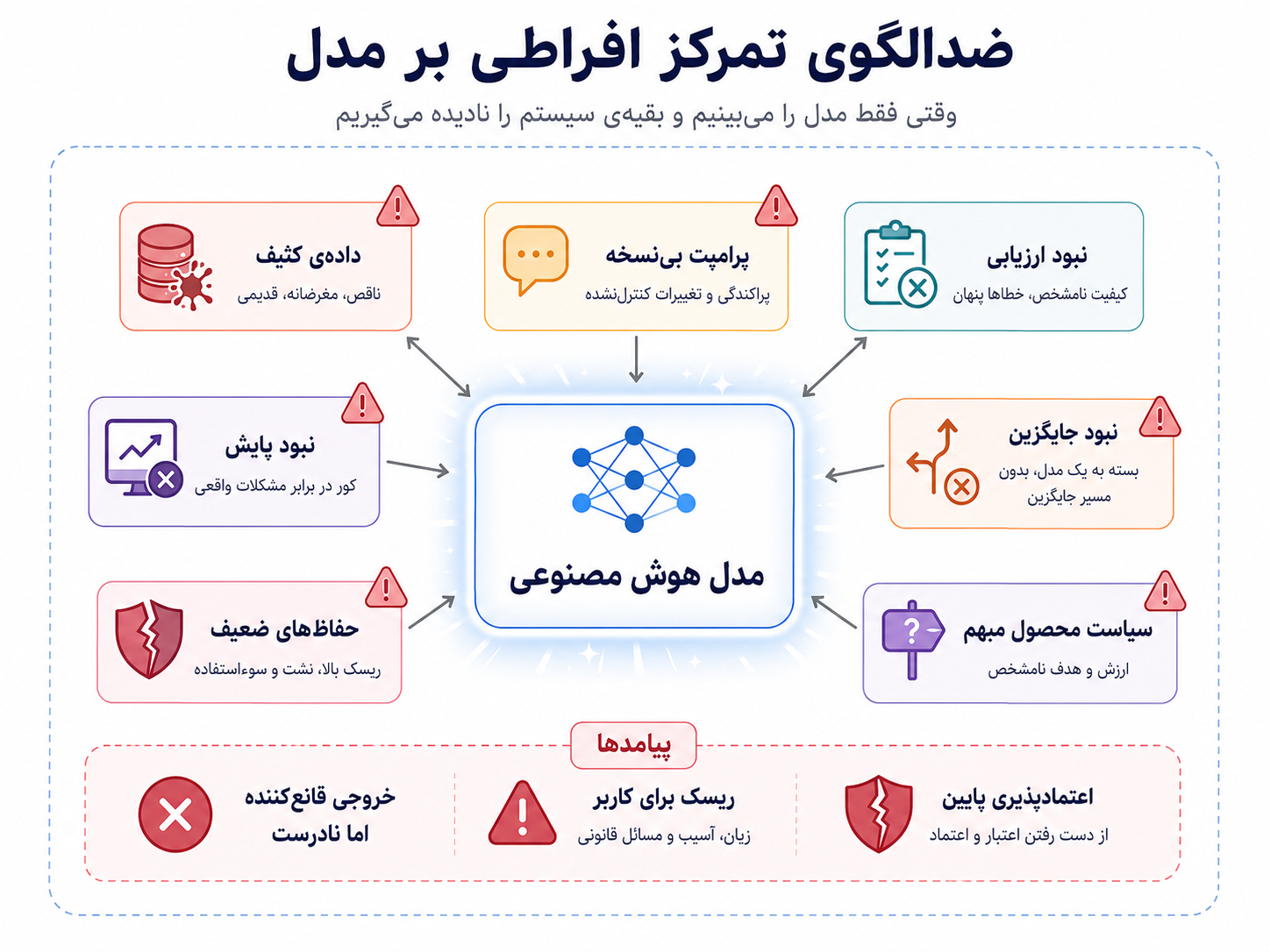
مدل بهتر، سیستم بد را نجات نمیدهد؛ اگر داده، ارزیابی، حفاظت، پایش، سیاست محصول و مسیر جایگزین ضعیف باشند، خروجی فقط قانعکنندهتر و خطرناکتر میشود.
مدل بهتر، معماری بد را نجات نمیدهد؛ فقط گاهی خرابی را قانعکنندهتر پنهان میکند. اگر نمیدانیم خروجی هوش مصنوعی را چطور ارزیابی کنیم، هنوز آمادهی سپردن تصمیم مهم به آن نیستیم. اگر نمیدانیم در چه شرایطی باید بگوید «نمیدانم»، هنوز طراحی محصول کامل نشده است. اگر نمیدانیم وقتی مدل اشتباه کرد چه کسی پاسخگوست، هنوز مالکیت روشن نداریم.
این نگاه یعنی SE4AI فقط بحث مدل و دقت نیست؛ بحث سیستم و مسئولیت است. باید بدانیم کدام داده وارد مدل میشود، کدام خروجی اجازهی نمایش به کاربر دارد، کدام تصمیم نیاز به تأیید انسانی دارد، کدام رفتار باید ثبت و حسابرسی شود، و کدام تغییر باید با ارزیابی مقایسه شود. باید بتوانیم نسخهی مدل، دستور مدل، بازیابی دانش و سیاست محصول را کنار هم ردیابی کنیم تا اگر رفتار محصول تغییر کرد، بفهمیم چرا.
اگر داده بد است، ارزیابی نداریم، مسیر جایگزین نداریم، لایههای حفاظتی ضعیفاند، دستور مدل بینسخه است و مالکیت رفتار مدل روشن نیست، مدل قویتر فقط بخشی از مسئله را پنهان میکند. اعتماد به سیستم هوش مصنوعی از مهندسی کل سیستم میآید، نه فقط از نام مدل.
برای ساخت سیستم هوش مصنوعی قابل اعتماد، باید چند چیز را از ابتدا جدی بگیریم. مسئله و معیار خوب بودن خروجی باید روشن باشد. دادهی ورودی و دادهی ارزیابی باید نماینده و قابل پیگیری باشند. دستور مدل و تنظیمات باید نسخهبندی شوند. خروجی باید پایش شود. برای خطا، عدم اطمینان، محتوای خطرناک یا درخواست خارج از محدوده باید مسیر جایگزین داشته باشیم. در کارهای حساس، انسان باید بخشی از طراحی باشد، نه وصلهای که بعد از حادثه اضافه میشود.
چه زمانی SE4AI جدیتر میشود؟
وقتی خروجی هوش مصنوعی روی کاربر واقعی، تصمیم محصولی، دادهی حساس، پول، اعتبار، رتبهبندی، توصیه، پشتیبانی یا اقدام خودکار اثر میگذارد، دیگر با یک دمو طرف نیستیم. در این شرایط باید ارزیابی، لایههای حفاظتی، مشاهدهپذیری، مسیر جایگزین، امنیت، حریم خصوصی و مالکیت رفتار مدل جدی گرفته شود.
چه زمانی هنوز در مرحلهی آزمایش هستیم؟
اگر فقط یک نمونهی اولیه داریم، خروجی هوش مصنوعی تصمیم مهمی نمیگیرد، دادهی حساس درگیر نیست، و انسان همهی خروجیها را پیش از استفاده بررسی میکند، میتوانیم سبکتر حرکت کنیم. اما همین مرحله هم باید از ابتدا به ما یاد بدهد که معیار کیفیت، ریسکها و مرزهای استفاده چه هستند.
برای من، SE4AI یعنی پذیرفتن اینکه سیستم مبتنی بر هوش مصنوعی فقط یک مدل نیست. مدل مهم است، اما بدون دادهی خوب، دستور مدل قابل کنترل، ارزیابی، لایهی حفاظتی، مشاهدهپذیری، مسیر جایگزین، امنیت، تجربهی کاربر و مسئولیت انسانی، محصول قابل اعتمادی ساخته نمیشود. هوش مصنوعی وقتی وارد محصول میشود، باید مثل بخشی از سیستم مهندسی شود؛ نه مثل جادویی که بیرون از قواعد مهندسی قرار دارد.
تا اینجا گفتیم سیستم هوش مصنوعی فقط مدل نیست و باید مهندسی شود. اما وقتی پای مدل، داده و تغییر مداوم رفتار وسط باشد، عملیات هم شکل تازهای پیدا میکند. نمیتوان مدل را یکبار مستقر کرد و فراموش کرد. داده تغییر میکند، توزیع ورودی عوض میشود، کیفیت افت میکند، و مدل باید پایش و گاهی بازآموزی شود. این ما را به بخش بعدی میرساند: MLOps.
وقتی مدل هم مثل کد، چرخهی تولید و نگهداری میخواهد
در بخش قبل گفتیم سیستم مبتنی بر هوش مصنوعی فقط یک مدل نیست. داده، دستور مدل، ارزیابی، حفاظتها، مشاهدهپذیری، مسیر جایگزین و مسئولیت انسانی هم بخشی از سیستماند. حالا یک قدم عملیاتیتر برمیداریم: اگر مدل وارد محصول شد، چطور آن را در تولید زنده، قابل پایش، قابل بازگشت و قابل بهبود نگه داریم؟
یک صحنهی آشنا را تصور کنیم. تیم داده یا تیم محصول یک مدل خوب ساخته است. در نوتبوک آزمایشی همهچیز امیدوارکننده است. دادهی آموزشی آماده شده، چند نمودار خوب داریم، معیارها مناسباند و مدل روی دادهی تست عملکرد قابل قبولی نشان میدهد. همه خوشحالاند و جملهی معروف شنیده میشود: «خب، حالا فقط مستقر کنیم.»
اما درست از همینجا درد واقعی شروع میشود. مدل در محیط تولید با دادههایی روبهرو میشود که همیشه شبیه دادهی آزمایشگاهی نیستند. رفتار کاربران تغییر میکند. فصل، کمپین، قیمت، سیاست محصول، بازار یا حتی شکل استفادهی کاربران عوض میشود. ویژگیهایی که موقع آموزش تمیز و کامل بودند، در تولید دیر، ناقص یا با تعریف متفاوت میرسند. مدلی که امروز خوب کار میکند، ممکن است دو ماه بعد آرامآرام افت کند؛ بدون اینکه سرویس از کار بیفتد یا خطای واضحی بدهد.
اینجاست که MLOps وارد داستان میشود.
MLOps یعنی ساختن چرخهای قابل اعتماد برای بردن مدلهای یادگیری ماشین از آزمایش به تولید، و نگهداری آنها در دنیایی که داده و رفتار سیستم مدام تغییر میکند.
مرز MLOps با بخش قبل مهم است. SE4AI میپرسید سیستم مبتنی بر هوش مصنوعی را چطور درست طراحی کنیم: کیفیت خروجی، ارزیابی، حفاظت، تجربهی کاربر، مسئولیت و معماری محصول. MLOps بیشتر روی چرخهی عملیاتی مدل و داده تمرکز دارد: داده چطور آماده میشود، مدل چطور آموزش میبیند، نسخهی مدل و داده چطور ثبت میشود، مدل چطور مستقر میشود، کیفیتش در تولید چطور پایش میشود، و اگر افت کرد یا داده تغییر کرد، چه میکنیم.
MLOps از نظر ذهنی به DevOps نزدیک است. در DevOps یاد گرفتیم کد فقط نوشته نمیشود؛ باید ساخته، تست، مستقر، پایش و در صورت نیاز برگردانده شود. اما در سیستمهای یادگیری ماشین، فقط کد نداریم. داده و مدل هم داراییهای اصلیاند. در نرمافزار کلاسیک، اگر کد تغییر نکند، انتظار داریم رفتار سیستم نسبتاً پایدار بماند. اما در یادگیری ماشین، حتی اگر کد و مدل تغییر نکنند، دنیای بیرون تغییر میکند و کیفیت مدل میتواند افت کند.
در MLOps، دارایی مهندسی فقط کد نیست؛ داده، ویژگی، مدل، معیار ارزیابی و خط لولهی آموزش هم دارایی مهندسیاند.
مدل فقط آموزش داده نمیشود؛ وارد چرخهای از داده، آمادهسازی، آموزش، ارزیابی، ثبت، استقرار، پایش و بازخورد میشود.
در مرحلهی آزمایش، نوتبوک ابزار بسیار خوبی است. میتوانیم سریع ایدهها را امتحان کنیم، نمودار بکشیم، مدلها را مقایسه کنیم و بفهمیم اصلاً مسئله ارزش ادامه دادن دارد یا نه. اما نوتبوک بهتنهایی محصول نیست. اگر نمیدانیم داده دقیقاً از کجا آمده، چطور پاکسازی شده، چه ویژگیهایی ساخته شده، کدام نسخه از کد استفاده شده، چه پارامترهایی تنظیم شده و مدل با چه معیارهایی ارزیابی شده، بازتولید همان نتیجه بعداً سخت میشود.
مدلی که فقط در نوتبوک خوب کار میکند، هنوز محصول نیست؛ فقط یک شواهد آزمایشگاهی است. برای اینکه مدل وارد سیستم واقعی شود، باید آموزش آن تکرارپذیر باشد، دادهاش قابل اعتبارسنجی باشد، مدلش نسخه داشته باشد، استقرارش کنترلشده باشد و کیفیتش بعد از استقرار دیده شود.
در یادگیری ماشین، داده فقط ورودی نیست؛ بخشی از رفتار سیستم است. اگر دادهی آموزشی نمایندهی دنیای واقعی نباشد، مدل در تولید بد عمل میکند. اگر schema داده تغییر کند، مدل ممکن است بیسروصدا خراب شود. اگر تعریف یک ویژگی عوض شود، مدل همان ورودی ظاهری را میگیرد، اما معنای آن عوض شده است. اگر داده دیر برسد یا ناقص باشد، خروجی مدل قابل اعتماد نیست.
مثلاً مدلی برای تشخیص تقلب داریم. اگر روشهای تقلب تغییر کنند، رفتار کاربران در یک فصل خاص عوض شود، یا یک ویژگی مهم با تأخیر برسد، دادهی تولید با دادهی زمان آموزش فاصله میگیرد. مدل همچنان خروجی میدهد، اما کیفیتش ممکن است پایین آمده باشد. این نوع خرابی با خطای اجرایی معلوم نمیشود؛ باید با پایش داده و کیفیت مدل دیده شود.
در یادگیری ماشین، خرابی همیشه از کار افتادن سرویس نیست؛ گاهی افت آرام کیفیت مدل است، چون دادهی واقعی از دادهی زمان آموزش فاصله گرفته است.
اینجا مفهوم رانش مهم میشود. رانش داده یعنی توزیع دادهی ورودی در تولید با دادهی زمان آموزش فرق کند. رانش مدل یا افت کیفیت یعنی خروجی و عملکرد مدل در دنیای واقعی دیگر مثل گذشته قابل اعتماد نباشد. گاهی این افت روی کل کاربران دیده نمیشود، بلکه روی یک گروه یا بخش خاص پنهان میماند. برای همین فقط دیدن یک عدد کلی مثل دقت کافی نیست. باید بدانیم مدل روی گروهها، سناریوها و بخشهای مهم محصول چطور رفتار میکند.
MLOps باید به اعتبارسنجی داده، کیفیت داده، سازگاری ویژگیها و پایش توجه کند. باید بفهمیم آیا دادهای که مدل میبیند همان معنایی را دارد که زمان آموزش داشته است یا نه. باید تشخیص دهیم آیا توزیع پیشبینیها تغییر کرده، تأخیر بالا رفته، خطای ویژگیها زیاد شده، یا کیفیت مدل روی گروه خاصی افت کرده است.
بخش مهم دیگر، نسخهبندی و ثبت مدل است. وقتی مدل جدیدی مستقر میشود، باید بتوانیم بگوییم با چه دادهای آموزش دیده، چه کدی آن را ساخته، چه پارامترهایی داشته، چه معیارهایی گرفته، چه کسی آن را تأیید کرده و روی چه بخشهایی خوب یا بد عمل کرده است. اگر مدل جدید بدتر شد، نسخهی قبلی باید قابل پیدا کردن و برگشت باشد.
اینجاست که مفاهیمی مثل رهگیری آزمایشها، مخزن ثبت مدل و مدیریت خروجیهای مدل مهم میشوند. ابزارهایی مثل MLflow، Weights & Biases، Kubeflow یا مخزن ویژگیهایی مثل Feast هرکدام بخشی از این مسئله را حل میکنند. اما ابزار بهتنهایی کافی نیست. اگر تیم نداند معیار تصمیمگیری چیست، چه چیزی باید ثبت شود و چه زمانی یک مدل اجازهی ورود به تولید دارد، مخزن ثبت مدل فقط تبدیل میشود به انبار فایلهای مدل.
در نرمافزار معمولی، CI/CD معمولاً یعنی کد را بساز، تست کن و بعد مستقر کن. در یادگیری ماشین این چرخه پیچیدهتر است. باید کد آموزش تست شود، داده اعتبارسنجی شود، مدل آموزش ببیند، مدل ارزیابی شود، اگر از حد قابل قبول بهتر بود ثبت شود، بعد به شکل کنترلشده مستقر شود و پس از آن رفتار مدل در تولید پایش شود. گاهی حتی از بازآموزی پیوسته حرف میزنیم؛ یعنی بازآموزی مداوم یا دورهای مدل. اما اینجا هم باید مراقب باشیم: خودکار کردن بازآموزی بدون کنترل کیفیت داده، یعنی سرعت دادن به تولید مدلهای بد.
اگر دادهی جدید آلوده، ناقص یا نمایندهی رفتار درست نباشد، بازآموزی خودکار فقط خطا را سریعتر وارد مدل بعدی میکند. MLOps خوب یعنی کنترل کیفیت چرخه، نه فقط اتوماسیون بیشتر.
نقد اصلی بخش این است: خیلی از تیمها MLOps را با ابزار اشتباه میگیرند. فکر میکنند اگر MLflow، Kubeflow، خط لولهی جذاب یا داشبورد داشته باشند، MLOps حل شده است. اما MLOps قبل از ابزار، یک نظم مهندسی است: تعریف مالکیت، معیار کیفیت، دادهی قابل اعتماد، بازتولیدپذیری، ارزیابی، پایش، برگشت و فرایند تصمیمگیری.
MLOps بدون تعریف روشن از کیفیت مدل، فقط اتوماسیون تولید خروجی است. اگر نمیدانیم مدل در تولید خوب کار میکند یا نه، داشتن خط لوله فقط ما را سریعتر به ابهام میرساند. مدل خوب در آزمایش الزاماً مدل خوب در محصول نیست. دقت کلی ممکن است افت کیفیت روی بخشهای مهم را پنهان کند. تشخیص رانش بدون برنامهی اقدام، فقط یک هشدار تزئینی است. پایش هم فقط تأخیر و در دسترس بودن سرویس نیست؛ کیفیت پیشبینی هم بخشی از سلامت سیستم است.
استقرار مدل پایان کار نیست؛ شروع نگهداری است. اگر مدل را مستقر کنیم و فراموش کنیم، تغییر داده و افت کیفیت دیر یا زود خودش را نشان میدهد.
ضدالگوی رایج این است که مدل را مستقر کنیم و بعد فراموشش کنیم. در روز استقرار همهچیز خوب به نظر میرسد. اما هفتهها و ماهها بعد، داده تغییر میکند، کیفیت مدل افت میکند، کاربران رفتار متفاوتی نشان میدهند، هشدار مشخصی وجود ندارد و کسی دقیق نمیداند مدل فعلی با کدام داده و کدام کد ساخته شده است. اینجا مشکل فقط فنی نیست؛ اعتماد محصولی و تصمیمگیری سازمانی هم آسیب میبیند.
مدل در تولید مثل یک فایل ثابت نیست. کیفیت آن به دادهی ورودی، رفتار کاربران، تغییرات محصول و شرایط بیرونی وابسته است. پس نگهداری مدل باید بخشی از طراحی سیستم باشد، نه کاری که بعد از اولین حادثه به آن فکر کنیم.
MLOps برای آزمایش سادهی دانشگاهی یا یک نمونهی اولیهی کوچک شاید لازم نباشد. اگر هدف فقط یادگیری، ارائهی اولیه یا اثبات امکانپذیری است، یک نوتبوک و چند معیار ساده میتواند کافی باشد. اما وقتی خروجی مدل روی کاربران واقعی، پول، ریسک، رتبهبندی، پیشنهاد، تشخیص تقلب، پشتیبانی یا تصمیم محصولی اثر میگذارد، دیگر با یک آزمایش طرف نیستیم. مدل بخشی از سیستم تولیدی است و باید مثل بخشی از سیستم تولیدی با آن رفتار کنیم.
چه زمانی MLOps جدی میشود؟
وقتی مدل وارد تولید میشود، چند تیم درگیر میشوند، داده مرتب تغییر میکند، تصمیم مدل روی کاربر یا کسبوکار اثر دارد، و لازم است آموزش، ارزیابی، استقرار و پایش قابل تکرار و قابل ردیابی باشند، MLOps از یک انتخاب خوب به یک نیاز جدی تبدیل میشود.
چه زمانی هنوز سادهتر حرکت کنیم؟
اگر هنوز در مرحلهی اکتشاف هستیم، مدل فقط برای یادگیری یا نمونهی اولیه استفاده میشود، خروجی روی کاربر واقعی اثر ندارد، و بازتولید دقیق هنوز مسئلهی اصلی نیست، میتوان سبکتر شروع کرد. اما حتی در همین مرحله هم بهتر است از ابتدا عادت کنیم داده، کد، معیار و نتیجهی آزمایشها را شفاف نگه داریم.
برای من، MLOps یعنی مدل را از یک خروجی آزمایشگاهی به بخشی قابل اعتماد از سیستم تولید تبدیل کنیم. این کار فقط با مستقر کردن مدل تمام نمیشود؛ به دادهی قابل اعتماد، آموزش تکرارپذیر، نسخهبندی، ارزیابی، استقرار کنترلشده، پایش کیفیت، تشخیص رانش، برگشت و تصمیمگیری انسانی نیاز دارد. مدل در تولید زنده است، چون دنیای اطرافش تغییر میکند.
از یک برنامهی ساده شروع کردیم و رسیدیم به سیستمی که داده، مدل، زیرساخت، عملیات، انسان، فرایند و هوش مصنوعی دارد. حالا دیگر مهندسی نرمافزار فقط نوشتن کد نیست؛ ساختن سیستمی است که در زمان، تغییر، خطا و رشد دوام بیاورد. بخش پایانی همین مسیر را جمعبندی میکند.
جمعبندی: وقتی نرمافزار بزرگ میشود، مسئله فقط کد نیست
ما این مسیر را از یک جای ساده شروع کردیم: یک برنامه، چند endpoint، چند کاربر و چند نیاز روشن. در آن نقطه، خیلی از مفاهیمی که در این نوشته دیدیم شاید زیادی بزرگ، رسمی یا حتی نمایشی به نظر برسند. کسی که هنوز یک محصول کوچک دارد، شاید واقعاً نیازی به Kubernetes، GitOps، CQRS، Event Sourcing، BPMS، Chaos Engineering یا MLOps نداشته باشد. این نکته را باید جدی گرفت؛ معماری خوب یعنی انتخاب بهاندازه، نه جمع کردن اسمهای جذاب.
اما نرمافزار اگر زنده بماند، تغییر میکند. کاربرها بیشتر میشوند، تیم بزرگتر میشود، نیازها از هم فاصله میگیرند، چند مصرفکنندهی مختلف پیدا میکنیم، سرویسها به هم وابسته میشوند، داده زیاد میشود، خطاها پرهزینهتر میشوند، زیرساخت پیچیدهتر میشود و کمکم پرسشهای تازهای پیش میآید: قرارداد API کجاست؟ هر مصرفکننده چه نیازی دارد؟ مرز دامنه کجاست؟ پیامها چطور جابهجا میشوند؟ دادهی قدیمی را چطور مهاجرت میدهیم؟ اگر بخشی از سیستم خراب شد چه میشود؟ فرایندهای سازمانی کجا قابل پیگیریاند؟ و وقتی هوش مصنوعی وارد محصول شد، کیفیت و مسئولیت خروجی را چطور میسنجیم؟
این نوشته قرار نبود از همهی این مفاهیم قهرمان بسازد. اتفاقاً در بیشتر بخشها یک هشدار تکرار شد: هر ابزار و الگو اگر بیجا وارد شود، میتواند مسئلهی تازه بسازد. BFF اگر فقط کپیکاری منطق شود، بدهی میسازد. Event Sourcing اگر برای مسئلهی نامناسب انتخاب شود، خواندن و نگهداری را سخت میکند. Serverless اگر بدون فهم مدل اجرا و هزینه وارد شود، غافلگیر میکند. Low-code و BPMS اگر بدون مالکیت و مرز روشن رشد کنند، منطق را از جلوی چشم تیم پنهان میکنند. هوش مصنوعی اگر بدون زمینه، ارزیابی و مسئولیت انسانی استفاده شود، فقط خروجی قانعکنندهتر تولید میکند؛ نه لزوماً نرمافزار بهتر.
این مفاهیم مدال افتخار نیستند؛ ابزارهاییاند برای پاسخ دادن به دردهای واقعی. وقتی درد واقعی وجود ندارد، استفاده از آنها بیشتر نمایش معماری است تا مهندسی.
از طرف دیگر، سادگی هم همیشه فضیلت نیست. سادگی وقتی ارزشمند است که مسئولانه باشد. اینکه همهچیز را در یک سرویس، یک جدول، یک جریان کاری، یک اسکریپت یا یک نوتبوک نگه داریم، شاید در شروع سریع باشد؛ اما اگر سیستم رشد کرده و هنوز هیچ مرزی، هیچ پایشی، هیچ تستی، هیچ قرارداد روشنی و هیچ مالکیتی نداریم، دیگر اسمش سادگی نیست. آنجا با سادگی بیمسئولیت طرفیم؛ چیزی که امروز راحت است و فردا هزینهاش را با کندی، خطا و ترس از تغییر پس میدهد.
پس خط میانی این است: نه معماری نمایشی، نه سادگی بیمسئولیت.
معماری نمایشی یعنی ابزارها را زودتر از درد واقعی وارد کنیم. سادگی بیمسئولیت یعنی درد واقعی را ببینیم و همچنان وانمود کنیم با چند فایل و چند دستور دستی همهچیز قابل کنترل است. مهندسی نرمافزار بالغ، بین این دو افراط حرکت میکند: مسئله را میفهمد، هزینهی راهحل را میسنجد، و ابزار را وقتی وارد میکند که واقعاً به روشنتر شدن، قابل نگهداریتر شدن یا قابل اعتمادتر شدن سیستم کمک کند.
در این مسیر، تقریباً همهی مفاهیم یک پیام مشترک داشتند: سیستمهای نرمافزاری فقط از کد تشکیل نشدهاند. قراردادها، دادهها، رخدادها، صفها، زیرساخت، استقرار، مشاهدهپذیری، مهاجرت داده، فرایندهای انسانی، ابزارهای داخلی، مدلهای هوش مصنوعی و حتی تصمیمهای سازمانی، همه بخشی از واقعیت نرمافزارند. اگر فقط کد را ببینیم، دیر یا زود آن بخشهای پنهان از جایی دیگر خودشان را نشان میدهند.
همینجا ارزش نگاه مرحلهای روشن میشود. لازم نیست روز اول همهچیز را کامل و سنگین طراحی کنیم. بهتر است از سادهترین راه مسئولانه شروع کنیم، اما حواسمان به نشانههای رشد باشد. وقتی چند مصرفکننده نیازهای متفاوت دارند، شاید BFF معنا پیدا کند. وقتی ارتباط سرویسها زیاد میشود، شاید صف پیام یا معماری رخدادمحور لازم شود. وقتی زیرساخت با کلیک و حافظهی افراد جلو میرود، IaC و GitOps جدیتر میشوند. وقتی دادهی زنده تغییر میکند، مهاجرت مرحلهای لازم میشود. وقتی مدل وارد تولید میشود، MLOps دیگر تزئین نیست.
قبل از وارد کردن هر الگو یا ابزار، بپرسیم: این انتخاب کدام درد واقعی را کم میکند؟ چه هزینهای به سیستم اضافه میکند؟ چه کسی مالک آن است؟ اگر شکست خورد، چطور میفهمیم و چطور برمیگردیم؟
اگر بخواهم کل این نوشته را در یک تصویر ذهنی خلاصه کنم، نرمافزار شبیه موجودی است که در زمان رشد میکند. اوایل فقط باید راه برود. بعد باید با دیگران حرف بزند. بعد باید بار بیشتری حمل کند. بعد باید بیمار نشود، یا اگر شد، زود بفهمیم. بعد باید در محیطهای مختلف زندگی کند. بعد باید با داده، فرایند، انسان و هوش مصنوعی کنار بیاید. ما هم بهعنوان مهندس، فقط سازندهی چند تابع نیستیم؛ نگهدارندهی این موجود در مسیر رشد هستیم.
این یعنی مهندسی نرمافزار، در معنای جدیاش، هنر انتخابهای مسئولانه در زمان است. گاهی انتخاب مسئولانه این است که ابزار تازهای وارد نکنیم. گاهی انتخاب مسئولانه این است که بالاخره بپذیریم راه دستی و سادهی قبلی دیگر جواب نمیدهد. گاهی باید پیچیدگی را بپذیریم، چون مسئله واقعاً پیچیده شده است. گاهی باید جلوی پیچیدگی را بگیریم، چون فقط از هیجان ابزار آمده، نه از نیاز سیستم.
در پایان، اگر خواننده بعد از این نوشته فقط نام این بیست مفهوم را حفظ کند، اتفاق مهمی نیفتاده است. هدف بهتر این است که وقتی در یک جلسه، طراحی، بازبینی، مهاجرت داده، انتخاب ابزار یا بحث معماری با یکی از این واژهها روبهرو میشود، بتواند یک قدم عقبتر بایستد و بپرسد:
این مفهوم دقیقاً قرار است کدام مشکل ما را حل کند؟
آیا مشکل ما واقعاً به این اندازه رسیده است؟
چه هزینهای پنهان میکند؟
چه چیزی را قابل مشاهدهتر، قابل تغییرتر یا قابل اعتمادتر میکند؟
و اگر اشتباه انتخابش کنیم، چه چیزی سختتر میشود؟
اگر این پرسشها همراه ما بمانند، این مسیر ارزشش را داشته است. چون مهندسی نرمافزار خوب با حفظ کردن اسم الگوها ساخته نمیشود؛ با دیدن مسئله، فهمیدن زمینه، سنجیدن هزینهها و انتخابهای مرحلهای ساخته میشود.